Compare commits
4792 Commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
c591621b2e | ||
|
|
5300d22fa1 | ||
|
|
3f8b6cc3c8 | ||
|
|
8488f6db18 | ||
|
|
1e1d7a31ea | ||
|
|
9394a38c7d | ||
|
|
0cb8dad051 | ||
|
|
a41cdab05e | ||
|
|
478fb85224 | ||
|
|
c50a93f2e8 | ||
|
|
bd64bde554 | ||
|
|
7427b368e9 | ||
|
|
b8576200b4 | ||
|
|
6a15917500 | ||
|
|
58c175ca32 | ||
|
|
4a05c62329 | ||
|
|
41513b3131 | ||
|
|
3f8624a29a | ||
|
|
790a7c434e | ||
|
|
6f37179e9f | ||
|
|
a41abdce24 | ||
|
|
7639b3d9ba | ||
|
|
6d12e0bc1a | ||
|
|
cb68849324 | ||
|
|
7dd0a4ccd9 | ||
|
|
22ec60e9f0 | ||
|
|
7b58623ca2 | ||
|
|
f61c3a5c4e | ||
|
|
5e6fbf5108 | ||
|
|
e02a3f6a35 | ||
|
|
d55c2d7a2c | ||
|
|
f5922ee4bc | ||
|
|
96f16f32cc | ||
|
|
ac71cb763f | ||
|
|
91662d08ae | ||
|
|
a99ea36b31 | ||
|
|
06fb3c1604 | ||
|
|
1956099022 | ||
|
|
bc2234bd85 | ||
|
|
76ef77d36f | ||
|
|
4e3ead31cf | ||
|
|
3f4df27025 | ||
|
|
aebb4f6931 | ||
|
|
69a40de884 | ||
|
|
325a4b6b89 | ||
|
|
d5ba802b7a | ||
|
|
208c440fd1 | ||
|
|
f305bc2f2f | ||
|
|
636ecc4e76 | ||
|
|
aaa7400ebc | ||
|
|
2fcfa08ce1 | ||
|
|
7385dfc100 | ||
|
|
ceea713cb0 | ||
|
|
f5ac855454 | ||
|
|
a6fe5f6d0e | ||
|
|
fe326271dc | ||
|
|
22126c8c98 | ||
|
|
152e17a4b0 | ||
|
|
74656a3f3d | ||
|
|
5ba3b7498d | ||
|
|
c2f183703a | ||
|
|
1aaa61faf0 | ||
|
|
de65f5a4bb | ||
|
|
66c1c43b31 | ||
|
|
c13af19f0e | ||
|
|
4972505947 | ||
|
|
b216e348ad | ||
|
|
4ac1e6ac72 | ||
|
|
0b320d31c9 | ||
|
|
2b23e61ead | ||
|
|
4ba690b8c9 | ||
|
|
c75a5da266 | ||
|
|
c6f01f2d42 | ||
|
|
e070e55aed | ||
|
|
408ea00873 | ||
|
|
4b844abf3b | ||
|
|
93223446ed | ||
|
|
993754c479 | ||
|
|
36d4a38005 | ||
|
|
e472a0f702 | ||
|
|
573071ae3a | ||
|
|
8b8658bd72 | ||
|
|
176da99558 | ||
|
|
385578da16 | ||
|
|
2a7b39d6c9 | ||
|
|
8642cfbb40 | ||
|
|
2264ea8017 | ||
|
|
9a76ce6172 | ||
|
|
3f66cd36f7 | ||
|
|
46c78191cd | ||
|
|
5b9af6e606 | ||
|
|
02d809531b | ||
|
|
4fdf0f75e0 | ||
|
|
6b8a04ed72 | ||
|
|
d2550861a7 | ||
|
|
22588e1ed9 | ||
|
|
b15de12be9 | ||
|
|
becd5769d3 | ||
|
|
71d99059a3 | ||
|
|
0fbb9b451a | ||
|
|
b8aa8896b8 | ||
|
|
98e130b2cc | ||
|
|
34f53de6b0 | ||
|
|
98ee14e936 | ||
|
|
13c12ce191 | ||
|
|
01d0ed4427 | ||
|
|
2c061cc308 | ||
|
|
1dd7753351 | ||
|
|
8992d535fe | ||
|
|
c6ff02ea03 | ||
|
|
654230d558 | ||
|
|
42098f8ed9 | ||
|
|
9c1a069abc | ||
|
|
338c379153 | ||
|
|
d5b02c3527 | ||
|
|
1407b08ccb | ||
|
|
50cd55f8f7 | ||
|
|
d25ee2ee4f | ||
|
|
2912f3bda3 | ||
|
|
0d69a97e4b | ||
|
|
fcac38eebe | ||
|
|
c10c586b87 | ||
|
|
ddb38b8563 | ||
|
|
8c5c1715d8 | ||
|
|
3bc70722fb | ||
|
|
7fa614f266 | ||
|
|
1e7558617e | ||
|
|
945335d0f2 | ||
|
|
663c297df6 | ||
|
|
fe0c056c83 | ||
|
|
368b3e1ed8 | ||
|
|
83a30c0d96 | ||
|
|
22a079fdac | ||
|
|
7ce64a1c49 | ||
|
|
8f17bb07a2 | ||
|
|
cf75b30ca2 | ||
|
|
2d46c8b9d2 | ||
|
|
6630969369 | ||
|
|
f48c13fde0 | ||
|
|
142f7d5d63 | ||
|
|
c174e3a417 | ||
|
|
4536a5ff77 | ||
|
|
cdb517efa5 | ||
|
|
b98ae97e1f | ||
|
|
8803d0e833 | ||
|
|
d25b613ab8 | ||
|
|
95ee32c9f3 | ||
|
|
b42cb5e0f5 | ||
|
|
04c7e6b2ff | ||
|
|
10febd444e | ||
|
|
203713228f | ||
|
|
2cea684def | ||
|
|
1d070b6070 | ||
|
|
f549578a19 | ||
|
|
c95dc3cbe9 | ||
|
|
3191ebfd39 | ||
|
|
c488f9c9d2 | ||
|
|
006b7b2bc0 | ||
|
|
e64b491183 | ||
|
|
326a3889e6 | ||
|
|
f3be6cd7bb | ||
|
|
407534a7b4 | ||
|
|
7ecf90cff3 | ||
|
|
69c1b39953 | ||
|
|
9ecb3ac159 | ||
|
|
8be7be6c11 | ||
|
|
dba56f4b13 | ||
|
|
89c46bebe6 | ||
|
|
325feb6a7f | ||
|
|
d178cd2d3a | ||
|
|
833e586bdf | ||
|
|
11a6223a63 | ||
|
|
0fb90651b2 | ||
|
|
f0ce01f740 | ||
|
|
58de613c85 | ||
|
|
dc64b379b1 | ||
|
|
9303c10c07 | ||
|
|
02832c403c | ||
|
|
bda36b208a | ||
|
|
292a8ac09c | ||
|
|
4c30b08ad9 | ||
|
|
f6bc6c5472 | ||
|
|
94008d4205 | ||
|
|
74059559a1 | ||
|
|
da1cdeec3f | ||
|
|
c2c99a4b79 | ||
|
|
8803d28f44 | ||
|
|
b488ad9531 | ||
|
|
3c08b611e1 | ||
|
|
0701c4ea3c | ||
|
|
0f429a1b1b | ||
|
|
b6c29c5dcc | ||
|
|
75fb7f5a26 | ||
|
|
4e14d1fc85 | ||
|
|
1d1e02585f | ||
|
|
ece4aed17e | ||
|
|
a3e5f2d6e6 | ||
|
|
25e0928eac | ||
|
|
142ae82d03 | ||
|
|
1fee1305c3 | ||
|
|
6693ed3ee5 | ||
|
|
2a599ee97c | ||
|
|
5733f5fb2d | ||
|
|
fb3ef57e90 | ||
|
|
6bbc3f22ba | ||
|
|
a458199863 | ||
|
|
45a295ed45 | ||
|
|
d7effbef19 | ||
|
|
3607c98d20 | ||
|
|
453df76095 | ||
|
|
848b516c3b | ||
|
|
b45429d1ec | ||
|
|
2a014ad881 | ||
|
|
7fa8e2c7c6 | ||
|
|
57509076c4 | ||
|
|
95af68692f | ||
|
|
df1524a9ca | ||
|
|
ea60b6616d | ||
|
|
d76bc188e6 | ||
|
|
0030eb9916 | ||
|
|
1520e7dc68 | ||
|
|
486620a3bf | ||
|
|
761ac4c44f | ||
|
|
c10259b866 | ||
|
|
dfb46b933a | ||
|
|
1f644fe601 | ||
|
|
4bc7455e93 | ||
|
|
e7dbc66f56 | ||
|
|
1422358a25 | ||
|
|
c274e370e0 | ||
|
|
f67ac592b1 | ||
|
|
89e35673ea | ||
|
|
91c7e8eb7e | ||
|
|
408b2d9f1b | ||
|
|
e755e27b56 | ||
|
|
2c1c5aafe5 | ||
|
|
28c9c63106 | ||
|
|
8e6d3d6fd1 | ||
|
|
61ad086eae | ||
|
|
57ee946ca4 | ||
|
|
4ca0483fc4 | ||
|
|
61b3b95261 | ||
|
|
f1740e336b | ||
|
|
1c68e89fc1 | ||
|
|
166712eb60 | ||
|
|
dbdf8a9a56 | ||
|
|
02fa852a4b | ||
|
|
c633ec01a6 | ||
|
|
d9027813a8 | ||
|
|
075cdb328e | ||
|
|
181aa66b65 | ||
|
|
435c134451 | ||
|
|
8d585f7508 | ||
|
|
1a0eb2217c | ||
|
|
37bd8ff493 | ||
|
|
e04f768d2c | ||
|
|
e42c631de6 | ||
|
|
8899891a28 | ||
|
|
b5517f68fe | ||
|
|
0d2017f1b5 | ||
|
|
78171b260b | ||
|
|
a50a541423 | ||
|
|
13f46f71c1 | ||
|
|
9920e286c5 | ||
|
|
3dc0dff6ea | ||
|
|
7a8d0cfe20 | ||
|
|
08ed3dc95a | ||
|
|
76ed6ef9bc | ||
|
|
36c62c91fe | ||
|
|
a64dbda708 | ||
|
|
7181f0c8b9 | ||
|
|
c78a18bc0e | ||
|
|
1188016590 | ||
|
|
5d3bede980 | ||
|
|
5daea16958 | ||
|
|
dc431423bd | ||
|
|
94d185ffa2 | ||
|
|
7de75011b6 | ||
|
|
4ae804df08 | ||
|
|
fc35237330 | ||
|
|
c511dae590 | ||
|
|
7f44c27b6b | ||
|
|
c60c641b60 | ||
|
|
6ab400cfc9 | ||
|
|
6d17fedfed | ||
|
|
5805a9b88b | ||
|
|
bc316c2689 | ||
|
|
224f364f47 | ||
|
|
fba6fb2915 | ||
|
|
e6b0b62669 | ||
|
|
3b434065f0 | ||
|
|
dfda93522d | ||
|
|
4f222b3946 | ||
|
|
f63cc12e9a | ||
|
|
ac859adc4e | ||
|
|
b029922629 | ||
|
|
fd4fda305d | ||
|
|
3e31b0c5d6 | ||
|
|
23fb7074ae | ||
|
|
ac79f1fb81 | ||
|
|
9b5aa2a5cb | ||
|
|
7790a7d480 | ||
|
|
784816de4f | ||
|
|
dc43eed4c3 | ||
|
|
a91139ead4 | ||
|
|
a01eda70b5 | ||
|
|
1b8af53912 | ||
|
|
1bfbb9ffa2 | ||
|
|
acac4a8bc1 | ||
|
|
96938f395e | ||
|
|
9ff2d6d012 | ||
|
|
cf06873a88 | ||
|
|
4a29a19812 | ||
|
|
a6583c0114 | ||
|
|
0efccd536b | ||
|
|
8fc3a55b19 | ||
|
|
f4d468895c | ||
|
|
0df83712e5 | ||
|
|
bf4754060d | ||
|
|
ed737aaf69 | ||
|
|
e53bc946e1 | ||
|
|
996dcbebaf | ||
|
|
9c95920a9a | ||
|
|
ebb8308c6d | ||
|
|
40d9ea8f09 | ||
|
|
54b2f9fa85 | ||
|
|
f9c8b87073 | ||
|
|
3db287fdd4 | ||
|
|
6c504ea742 | ||
|
|
5683c210e6 | ||
|
|
c562415255 | ||
|
|
68d21a1f8c | ||
|
|
f56fb2cec1 | ||
|
|
3f89fe2111 | ||
|
|
888d2e6643 | ||
|
|
626c985567 | ||
|
|
4aa8e3d267 | ||
|
|
7a8d8ff452 | ||
|
|
244ea2561e | ||
|
|
7fd66dc92c | ||
|
|
a715c52783 | ||
|
|
fe60deb209 | ||
|
|
922b7e757f | ||
|
|
6a3fed6641 | ||
|
|
06323ab4f9 | ||
|
|
8d4d798a9a | ||
|
|
eb6f7cf1eb | ||
|
|
89efe99ad5 | ||
|
|
3088e26a63 | ||
|
|
6707ec8cfd | ||
|
|
aa85223f2e | ||
|
|
0535204985 | ||
|
|
e005e5cfb6 | ||
|
|
c9c48bb542 | ||
|
|
31c4141c49 | ||
|
|
7f6b088fb6 | ||
|
|
c15bc21fcd | ||
|
|
3b99f98008 | ||
|
|
675c24d2f4 | ||
|
|
2e44c630db | ||
|
|
2c4aad05fe | ||
|
|
74e2f9554c | ||
|
|
45243747e6 | ||
|
|
2c6d3c60a5 | ||
|
|
ecfdcc8d94 | ||
|
|
087f0ed7bb | ||
|
|
b8aa5b4efa | ||
|
|
6ff9ecd394 | ||
|
|
87a01b9e92 | ||
|
|
099329f561 | ||
|
|
a0c46bd44d | ||
|
|
ee4764715b | ||
|
|
c7e641b828 | ||
|
|
28a6a81341 | ||
|
|
0b7fb5e12a | ||
|
|
7502b5856c | ||
|
|
3be157c6b9 | ||
|
|
c7d0c2ea9e | ||
|
|
02de03e825 | ||
|
|
8184c8f99f | ||
|
|
caafe1c175 | ||
|
|
ef83c507c9 | ||
|
|
727d5f75ce | ||
|
|
83aec21bf9 | ||
|
|
d33c56075f | ||
|
|
703060b318 | ||
|
|
a2eb16e363 | ||
|
|
afa1852e37 | ||
|
|
428b7e044e | ||
|
|
8ab12c589a | ||
|
|
08e7b80360 | ||
|
|
d43f40b3c7 | ||
|
|
490e4cf480 | ||
|
|
68cbc68c91 | ||
|
|
31fd972a4e | ||
|
|
50d3e18f9d | ||
|
|
4f3957d698 | ||
|
|
3d10186215 | ||
|
|
c8dc73fec4 | ||
|
|
dfdd05ad64 | ||
|
|
65ba39467c | ||
|
|
95f7f4dcca | ||
|
|
edf58c5114 | ||
|
|
34dc740acf | ||
|
|
4f1c8cdda8 | ||
|
|
6f403aa6c5 | ||
|
|
991c09faca | ||
|
|
aaaa00bb67 | ||
|
|
35ce47fed9 | ||
|
|
52e9b34abe | ||
|
|
66d8196524 | ||
|
|
eafbee00d6 | ||
|
|
4b7e84a84e | ||
|
|
c1e4d1eba4 | ||
|
|
5409b6df33 | ||
|
|
9d76d90828 | ||
|
|
6d81e8054f | ||
|
|
8f6e4d4b4b | ||
|
|
d67bc4f4ce | ||
|
|
f602d42ebd | ||
|
|
33b5b25ad8 | ||
|
|
5f6ff53690 | ||
|
|
36c29fd768 | ||
|
|
4510f84822 | ||
|
|
757be8dd83 | ||
|
|
6b0cd0c3aa | ||
|
|
44a09a745f | ||
|
|
4d3acd9cd3 | ||
|
|
e3c7bc9161 | ||
|
|
5c48690979 | ||
|
|
467bb4cc80 | ||
|
|
b85b60d79d | ||
|
|
0a938a174e | ||
|
|
1d2efe0b05 | ||
|
|
f4562ad914 | ||
|
|
ca56590649 | ||
|
|
9206b14768 | ||
|
|
971c51256d | ||
|
|
cd2cf872db | ||
|
|
e1db59e69d | ||
|
|
c0c4c8e024 | ||
|
|
3d38507f15 | ||
|
|
38d8a01e6b | ||
|
|
c374f48e6f | ||
|
|
53fcf10b32 | ||
|
|
020028e72b | ||
|
|
4f657b9298 | ||
|
|
985bb49b2b | ||
|
|
faaf624ff9 | ||
|
|
6f90e5988e | ||
|
|
2e8eb00efb | ||
|
|
6ccb1a06d3 | ||
|
|
246ad99d82 | ||
|
|
e7de969108 | ||
|
|
501967bd03 | ||
|
|
651a2503f8 | ||
|
|
a72248c760 | ||
|
|
2bfd7fb24b | ||
|
|
ae3b2254a6 | ||
|
|
8309390c8d | ||
|
|
e5184f1e92 | ||
|
|
9cf8d32b81 | ||
|
|
0e25c27eb0 | ||
|
|
5ad68c28b0 | ||
|
|
5ff19f7103 | ||
|
|
b11df43b7f | ||
|
|
2311fc5d38 | ||
|
|
a955b950da | ||
|
|
1a32fcee5e | ||
|
|
501345d634 | ||
|
|
0bb891d49e | ||
|
|
3739a09e30 | ||
|
|
270fd8f27d | ||
|
|
f8b678c96d | ||
|
|
12cbd6c00a | ||
|
|
85f7eb513a | ||
|
|
07c1fcc170 | ||
|
|
0544579b75 | ||
|
|
56e31dee1a | ||
|
|
e189453005 | ||
|
|
682dfb272e | ||
|
|
44a8eeb46a | ||
|
|
9783244e9e | ||
|
|
aceda00f28 | ||
|
|
a2c9b9356d | ||
|
|
9478c5a132 | ||
|
|
b49066f7fb | ||
|
|
257a8a9ce0 | ||
|
|
5f5afd35dc | ||
|
|
7e50351584 | ||
|
|
3121d5edc4 | ||
|
|
b43d685c72 | ||
|
|
7d441cee06 | ||
|
|
ffbd5a3047 | ||
|
|
c512a65f78 | ||
|
|
ea3b78c7b6 | ||
|
|
b16ecaf83c | ||
|
|
14a5532430 | ||
|
|
689e3f1a0d | ||
|
|
2ca9ec5360 | ||
|
|
c2fea9fe7e | ||
|
|
81a12c144d | ||
|
|
0c1dfffd36 | ||
|
|
5aa12cf256 | ||
|
|
6f6ee36fc3 | ||
|
|
6c465391de | ||
|
|
1b19b6974a | ||
|
|
3196519205 | ||
|
|
a2d0afab87 | ||
|
|
f9fdda7d32 | ||
|
|
90bfc8f469 | ||
|
|
5e835486c5 | ||
|
|
d88badfd1d | ||
|
|
94342c6e43 | ||
|
|
7aa5db95a4 | ||
|
|
9d92542652 | ||
|
|
e8af38db04 | ||
|
|
3224d86e46 | ||
|
|
f7db08df14 | ||
|
|
1d25e18b3d | ||
|
|
9ccceedb75 | ||
|
|
2af564294d | ||
|
|
33772a9773 | ||
|
|
cc62cd2e1d | ||
|
|
75d12267af | ||
|
|
e161fa598f | ||
|
|
0c09d72d09 | ||
|
|
99efdd19c1 | ||
|
|
7bf8083314 | ||
|
|
5676daafbe | ||
|
|
e83a6404c4 | ||
|
|
d53a49bfbb | ||
|
|
93f3faf277 | ||
|
|
e4e48fd14f | ||
|
|
c47224cffa | ||
|
|
ad71403117 | ||
|
|
186740f895 | ||
|
|
f8d7fc47cf | ||
|
|
f71db40a27 | ||
|
|
ab05e27254 | ||
|
|
a7aaf15e19 | ||
|
|
620d55a060 | ||
|
|
c1ed50cebf | ||
|
|
2c015d6b6f | ||
|
|
cd487b2023 | ||
|
|
495d27b51d | ||
|
|
a0015d30f8 | ||
|
|
86da4fc42a | ||
|
|
9bf75235c6 | ||
|
|
e38ededfb5 | ||
|
|
c84b75d3d2 | ||
|
|
b92ddc14a2 | ||
|
|
b651c7870b | ||
|
|
54983f4ddd | ||
|
|
0e79a08a76 | ||
|
|
edbf39832d | ||
|
|
8f1a4d250c | ||
|
|
5ac13227c8 | ||
|
|
32d8306031 | ||
|
|
fef64d315c | ||
|
|
de580d67aa | ||
|
|
4e1143bd26 | ||
|
|
391a13e5b0 | ||
|
|
5c0bc1ac65 | ||
|
|
32b5edd7f9 | ||
|
|
d2b48ffdfa | ||
|
|
38842d11ce | ||
|
|
0812d456a9 | ||
|
|
356a845a68 | ||
|
|
6dfaf074e8 | ||
|
|
8519eb97ef | ||
|
|
e8c03dd80a | ||
|
|
c0b22d1cd2 | ||
|
|
79eb6faa7a | ||
|
|
c936eaa1bf | ||
|
|
89f54b920e | ||
|
|
b98bf9a12b | ||
|
|
74d705a62e | ||
|
|
6c0be2e754 | ||
|
|
5da54d8c0a | ||
|
|
c42eb0f2d3 | ||
|
|
e6864494f6 | ||
|
|
fd4e636b61 | ||
|
|
8c44f5a1b2 | ||
|
|
c316936298 | ||
|
|
c174ea4dbc | ||
|
|
a8a0e9a817 | ||
|
|
d647d454b3 | ||
|
|
7c30b7ec44 | ||
|
|
60f80184b3 | ||
|
|
1fef4af9fb | ||
|
|
6d5fbbfda8 | ||
|
|
f7dd6c9d98 | ||
|
|
cef377fdbc | ||
|
|
6695cf2755 | ||
|
|
bce5cf3fad | ||
|
|
002de7d218 | ||
|
|
4af5e6565a | ||
|
|
5ac28b36d4 | ||
|
|
8bd899f2de | ||
|
|
f60390045c | ||
|
|
a5f09642e7 | ||
|
|
cd78e754d8 | ||
|
|
3eb70969da | ||
|
|
f90757c723 | ||
|
|
3a51ee5a78 | ||
|
|
4c315bf73b | ||
|
|
73196a4594 | ||
|
|
86041eb9fe | ||
|
|
308e0c47d3 | ||
|
|
79aaa94790 | ||
|
|
23947d0006 | ||
|
|
aa4ec14ba8 | ||
|
|
5b8253a2a7 | ||
|
|
e97fe1e495 | ||
|
|
bd61c0d786 | ||
|
|
fda5bcdec1 | ||
|
|
f3639e84c0 | ||
|
|
9460f44b95 | ||
|
|
c07911ad42 | ||
|
|
bd14840540 | ||
|
|
f0d2abe0d8 | ||
|
|
c07a505dcd | ||
|
|
befa49422b | ||
|
|
07bd70ce33 | ||
|
|
0195e29d8d | ||
|
|
02e8f7e866 | ||
|
|
d3851dd382 | ||
|
|
21d6c8202a | ||
|
|
e1af68fc6b | ||
|
|
2f0ad892c2 | ||
|
|
e6d85036fd | ||
|
|
4ae1f641a6 | ||
|
|
6c0bd1c078 | ||
|
|
35d1b26101 | ||
|
|
c7272849bf | ||
|
|
514d485634 | ||
|
|
28c4fc3899 | ||
|
|
445b4d9ad0 | ||
|
|
1016e9e474 | ||
|
|
4d2b7d2150 | ||
|
|
c368ef3726 | ||
|
|
b905d7599a | ||
|
|
bcf63acfd4 | ||
|
|
81c64d271f | ||
|
|
e61e03e05a | ||
|
|
53be049cf0 | ||
|
|
1ddc05c96f | ||
|
|
c775f808fc | ||
|
|
c273ff8477 | ||
|
|
24a815def7 | ||
|
|
297e7386ac | ||
|
|
7dafed0b78 | ||
|
|
881d248987 | ||
|
|
e2a27b84f1 | ||
|
|
29d303a5cc | ||
|
|
94a3ce1390 | ||
|
|
d93c80f941 | ||
|
|
340c0addaa | ||
|
|
17764c5122 | ||
|
|
62d24fbd88 | ||
|
|
a5f15d1d02 | ||
|
|
83c9607ebe | ||
|
|
3cd2c8c4fe | ||
|
|
77fa0e5ba3 | ||
|
|
275e0cd977 | ||
|
|
766d6351c1 | ||
|
|
09ab741015 | ||
|
|
8f7da7381c | ||
|
|
4948e410ff | ||
|
|
b2579cd29b | ||
|
|
8e3d203b96 | ||
|
|
ad2818b0b0 | ||
|
|
a60dae643e | ||
|
|
5353b7d4bf | ||
|
|
2cea12ce11 | ||
|
|
b6a955af34 | ||
|
|
f3edc3bb9a | ||
|
|
5e9467a248 | ||
|
|
e0a725b932 | ||
|
|
024eb91ed4 | ||
|
|
e1b99aabd8 | ||
|
|
064b11321b | ||
|
|
f67135037b | ||
|
|
61f4e964ab | ||
|
|
55e0962b1f | ||
|
|
dce03c75df | ||
|
|
5a51f25001 | ||
|
|
22cff97e9d | ||
|
|
03978331da | ||
|
|
1f2f19a8c3 | ||
|
|
4881e376e8 | ||
|
|
374a1bc3b4 | ||
|
|
dd93f6055d | ||
|
|
16d1fd2b9a | ||
|
|
bfcca778b2 | ||
|
|
1369628d8a | ||
|
|
0e8b7d05d4 | ||
|
|
3a81a1a912 | ||
|
|
26a1b683ea | ||
|
|
4a29975753 | ||
|
|
4b6a082ad5 | ||
|
|
b7c6787b9c | ||
|
|
f941b6c504 | ||
|
|
bc0855e08f | ||
|
|
6df7052bdb | ||
|
|
9e106d43c6 | ||
|
|
d5cb1d2147 | ||
|
|
6985c8fe7d | ||
|
|
b1717dac7d | ||
|
|
bbd61224c3 | ||
|
|
94391ddf6a | ||
|
|
664d81ff76 | ||
|
|
771ed02aa4 | ||
|
|
c49088cbe4 | ||
|
|
193d7ddb2a | ||
|
|
95cae3589d | ||
|
|
1129ac3d85 | ||
|
|
41ec7c0d20 | ||
|
|
de7dc3d6aa | ||
|
|
5468deba17 | ||
|
|
9ef0c058ea | ||
|
|
79c375bab6 | ||
|
|
9be3e68380 | ||
|
|
c8f2359119 | ||
|
|
49665e1714 | ||
|
|
b9cb6e7c07 | ||
|
|
56b555ffa0 | ||
|
|
fcfda77089 | ||
|
|
56e4c8ddfa | ||
|
|
1ad70a54c1 | ||
|
|
ad3f3ab7d3 | ||
|
|
7509ec44dc | ||
|
|
5ad569cbd3 | ||
|
|
2e3b6dc692 | ||
|
|
9d0932c1e2 | ||
|
|
0cbaf3db0c | ||
|
|
41871f9e0a | ||
|
|
892b36c297 | ||
|
|
61c8aa9f92 | ||
|
|
7c38c9076f | ||
|
|
fbca6fa138 | ||
|
|
4846786686 | ||
|
|
468997aefd | ||
|
|
db226e9046 | ||
|
|
48249d74eb | ||
|
|
d7b5e6cda5 | ||
|
|
05f4233e0d | ||
|
|
4731b25f2e | ||
|
|
89b830d102 | ||
|
|
1f01bcad3a | ||
|
|
e3c9243b6a | ||
|
|
267b460759 | ||
|
|
0ef74854ff | ||
|
|
f3009355af | ||
|
|
596ad6e39a | ||
|
|
11516bd84a | ||
|
|
b0d485e1cb | ||
|
|
1e516f5a38 | ||
|
|
93ebae4c48 | ||
|
|
c1a5d453be | ||
|
|
68e214829b | ||
|
|
766a72debe | ||
|
|
53e9fca3de | ||
|
|
5e45a8ad14 | ||
|
|
a32980cdd8 | ||
|
|
834c20f14d | ||
|
|
bb6b1d43bc | ||
|
|
f6b35b985c | ||
|
|
de0dd18aeb | ||
|
|
4ceb021e17 | ||
|
|
0541395c50 | ||
|
|
300934332e | ||
|
|
4fb74f7b23 | ||
|
|
bf8644d96f | ||
|
|
78abd0c4b9 | ||
|
|
8458f8cd73 | ||
|
|
d66e67b9e8 | ||
|
|
8808aacdd9 | ||
|
|
b69b3c2793 | ||
|
|
96dfdae960 | ||
|
|
43d0de2b85 | ||
|
|
a1353572ea | ||
|
|
b652cc9b9d | ||
|
|
35db2ce799 | ||
|
|
4a77202018 | ||
|
|
6b6f0ad021 | ||
|
|
a03ed3d669 | ||
|
|
24ca5e1ba0 | ||
|
|
119f004e23 | ||
|
|
ed739359fd | ||
|
|
349d87980b | ||
|
|
becc2f6d6f | ||
|
|
dda7ea7d40 | ||
|
|
67a8ec04f8 | ||
|
|
927e42e22e | ||
|
|
b1e8516b51 | ||
|
|
67e408ea49 | ||
|
|
e8d6a04a53 | ||
|
|
750d1d1ecc | ||
|
|
cfab993ec0 | ||
|
|
48dd4d1bb7 | ||
|
|
b94d6124c5 | ||
|
|
2f5741fc51 | ||
|
|
cdcfebd660 | ||
|
|
9a82930af9 | ||
|
|
ca8d91e85e | ||
|
|
3104a9bf67 | ||
|
|
9e5955b7b9 | ||
|
|
a78f01e1e1 | ||
|
|
22fe1df260 | ||
|
|
5a2e149ab3 | ||
|
|
c5d13af625 | ||
|
|
4cc960a011 | ||
|
|
6ac8d70dca | ||
|
|
52f0d468e3 | ||
|
|
b8017dc00f | ||
|
|
47487f230c | ||
|
|
edd89e950a | ||
|
|
4cbc932034 | ||
|
|
4b3fc6d5a1 | ||
|
|
f1bb2f6d24 | ||
|
|
19b09fe694 | ||
|
|
d81c24cd5d | ||
|
|
6730bf4dd3 | ||
|
|
2dcfad6999 | ||
|
|
6e4b083106 | ||
|
|
0ea2124fcd | ||
|
|
a626324357 | ||
|
|
b0055802aa | ||
|
|
814a348d75 | ||
|
|
7baee59ae7 | ||
|
|
f04981248c | ||
|
|
7e54f9d21e | ||
|
|
b37177a347 | ||
|
|
6d600bb8b3 | ||
|
|
c02518b5cf | ||
|
|
c112a45673 | ||
|
|
508ced89f2 | ||
|
|
94e40ec820 | ||
|
|
8bad75d2b1 | ||
|
|
499b2b5f44 | ||
|
|
b64070a3b1 | ||
|
|
5874872e81 | ||
|
|
fdd54f9b33 | ||
|
|
b96efbdabf | ||
|
|
834edea9e5 | ||
|
|
8567d353b1 | ||
|
|
cca0c65568 | ||
|
|
9d5963c682 | ||
|
|
499a5da566 | ||
|
|
4394ca795e | ||
|
|
2e73ed1426 | ||
|
|
88f8a9b6e3 | ||
|
|
d462c1e585 | ||
|
|
5de932d051 | ||
|
|
59d6541b91 | ||
|
|
cb1da99fbc | ||
|
|
4d40fcf9f7 | ||
|
|
9fda316040 | ||
|
|
ab760635d7 | ||
|
|
9fb167bca0 | ||
|
|
972eaf3d20 | ||
|
|
3dd6b74305 | ||
|
|
6a91cbdb8d | ||
|
|
4a3cefd18a | ||
|
|
ef97650b2a | ||
|
|
24a45c2a32 | ||
|
|
ecfb04ce24 | ||
|
|
e884f08e8b | ||
|
|
56c20ea768 | ||
|
|
e376d9dc1b | ||
|
|
f0458f5f16 | ||
|
|
92d94102ea | ||
|
|
b20e6c856a | ||
|
|
287b4e7c13 | ||
|
|
748ca84ef7 | ||
|
|
47c25a972d | ||
|
|
13846358ef | ||
|
|
a76bd6f3af | ||
|
|
d0da952307 | ||
|
|
d7aadcdbcc | ||
|
|
6e188cc3b5 | ||
|
|
b1aa630ba1 | ||
|
|
b246c0e04b | ||
|
|
07154a74aa | ||
|
|
ffd2adb960 | ||
|
|
662de320a2 | ||
|
|
e67c1a8f73 | ||
|
|
fed1cc4762 | ||
|
|
a83fd6d5ce | ||
|
|
994e38f9d0 | ||
|
|
fab286164d | ||
|
|
1bf116ead2 | ||
|
|
881ecd76e7 | ||
|
|
38208a67d0 | ||
|
|
58418eea93 | ||
|
|
c19c229e2e | ||
|
|
2c2e53b0d5 | ||
|
|
cb7d28f1c3 | ||
|
|
118be0a234 | ||
|
|
cfcec527a6 | ||
|
|
e8f133fce4 | ||
|
|
97906ac755 | ||
|
|
ccd8a29bc8 | ||
|
|
2acdef55d6 | ||
|
|
baa5d2f8c0 | ||
|
|
cde9823cec | ||
|
|
d2c0c5c901 | ||
|
|
7e36d7da2b | ||
|
|
4c1fab7adf | ||
|
|
db5ef321de | ||
|
|
9f0414aa96 | ||
|
|
b97d166a29 | ||
|
|
c2468acb6b | ||
|
|
4c2a39c1af | ||
|
|
dcb2e68d76 | ||
|
|
e45a2a54c3 | ||
|
|
474b861fd7 | ||
|
|
4eee66dfb9 | ||
|
|
ca0dafc644 | ||
|
|
eb95331de4 | ||
|
|
69e530065f | ||
|
|
39762ced81 | ||
|
|
8720e243e1 | ||
|
|
a19741b61a | ||
|
|
becd07ecb2 | ||
|
|
cfdb7e1a99 | ||
|
|
132c0b1ede | ||
|
|
4e3fb0aae0 | ||
|
|
f3b09e2c66 | ||
|
|
d57bc99f40 | ||
|
|
352fcf1f90 | ||
|
|
0d32d3b10f | ||
|
|
4a331098fa | ||
|
|
177ce2be34 | ||
|
|
674d89acf3 | ||
|
|
67f4530155 | ||
|
|
b39d6bfeaa | ||
|
|
cbd89f8061 | ||
|
|
5bbb55cf85 | ||
|
|
6c77da8142 | ||
|
|
a5451f42ff | ||
|
|
6a0c10aecb | ||
|
|
a8b4f38a57 | ||
|
|
42a02f9fe6 | ||
|
|
8da32f3a39 | ||
|
|
3d0ef01ce6 | ||
|
|
0d3eaa9a38 | ||
|
|
c0c60f6adf | ||
|
|
d79cfdbe4b | ||
|
|
3c7fcf7054 | ||
|
|
1d5a1d25ba | ||
|
|
a83b98fe24 | ||
|
|
92b1616c32 | ||
|
|
78d090100c | ||
|
|
cfa953bba2 | ||
|
|
396f857fc9 | ||
|
|
4cb5415e49 | ||
|
|
b91a30098b | ||
|
|
973e909bc7 | ||
|
|
60b5f0cfce | ||
|
|
124d0b48e2 | ||
|
|
b909324d42 | ||
|
|
234cd25d03 | ||
|
|
24551727b2 | ||
|
|
89c1c5ab01 | ||
|
|
b094d53251 | ||
|
|
87cb5ff53c | ||
|
|
fb49739928 | ||
|
|
841b46db7f | ||
|
|
8e228b5e82 | ||
|
|
d3ecfa9604 | ||
|
|
f5e034faf8 | ||
|
|
0a1a5c2a22 | ||
|
|
fc185af6b9 | ||
|
|
e7ae0c09c5 | ||
|
|
58e2b86575 | ||
|
|
7b7d69a2a0 | ||
|
|
7f6a833280 | ||
|
|
8318a506a7 | ||
|
|
de29d01f9d | ||
|
|
2d42b6c5a6 | ||
|
|
3e87edad52 | ||
|
|
3649f99c9a | ||
|
|
00265131ca | ||
|
|
1080539463 | ||
|
|
2f692f0e0c | ||
|
|
baf75289f2 | ||
|
|
2cebf5fd0e | ||
|
|
0184dafb98 | ||
|
|
83dea6349d | ||
|
|
0a6ce072d1 | ||
|
|
170f4455d5 | ||
|
|
4990763bbf | ||
|
|
8dca9d0531 | ||
|
|
ce28130628 | ||
|
|
44be1556dc | ||
|
|
dd90124331 | ||
|
|
a7f64c4898 | ||
|
|
9594358481 | ||
|
|
08bfdb95c9 | ||
|
|
9819a06e6b | ||
|
|
777d280433 | ||
|
|
9a137aa708 | ||
|
|
34bf39804b | ||
|
|
d836e9dfbe | ||
|
|
cd0487336e | ||
|
|
0c4ff6435f | ||
|
|
e3379f80c6 | ||
|
|
1e9891a521 | ||
|
|
b28a9663a9 | ||
|
|
a3cae9dad6 | ||
|
|
fa64c3ef6c | ||
|
|
b944fd7111 | ||
|
|
b3b7567acd | ||
|
|
6cb8edf763 | ||
|
|
c72247b6dc | ||
|
|
28d6bbcf62 | ||
|
|
55f026c801 | ||
|
|
6c78f97f5a | ||
|
|
b8e6b713f9 | ||
|
|
cfee21a77a | ||
|
|
a5376f148b | ||
|
|
0b399cc1f2 | ||
|
|
13cdc14a67 | ||
|
|
219c18b895 | ||
|
|
79d426c5b6 | ||
|
|
e85528a898 | ||
|
|
78da6f4710 | ||
|
|
4ecd07606e | ||
|
|
fbabf8d83a | ||
|
|
b4a2ed85d8 | ||
|
|
3e8dcb18c4 | ||
|
|
8f93d5cefc | ||
|
|
1e5edecc31 | ||
|
|
18a15d1ca7 | ||
|
|
924677c523 | ||
|
|
e6aee72310 | ||
|
|
d55259fb73 | ||
|
|
b65e4e03db | ||
|
|
d6753694a2 | ||
|
|
ff6d9739ac | ||
|
|
1b9011d078 | ||
|
|
97192f19e3 | ||
|
|
d21964af53 | ||
|
|
94c5478869 | ||
|
|
157bb629e5 | ||
|
|
59afeab08c | ||
|
|
f6d2bcf064 | ||
|
|
2c1f9e90a9 | ||
|
|
4ece33f07b | ||
|
|
b43781dd60 | ||
|
|
6e24e6c85d | ||
|
|
b18a06426e | ||
|
|
3b8db3d1e4 | ||
|
|
9cabf55a9f | ||
|
|
994dd36ca3 | ||
|
|
6b47f8dde7 | ||
|
|
29009c4932 | ||
|
|
bbc4246601 | ||
|
|
18254110b9 | ||
|
|
0837440eff | ||
|
|
1f14cd7f60 | ||
|
|
0938c2f00b | ||
|
|
a07731fbca | ||
|
|
a50a9b1df2 | ||
|
|
2444fa78cf | ||
|
|
c51550b8a4 | ||
|
|
fe6410b0e2 | ||
|
|
f04b8d4145 | ||
|
|
8048715660 | ||
|
|
93e0eb71f2 | ||
|
|
5a8359e167 | ||
|
|
c1aa4eed35 | ||
|
|
eb8fb1fdbb | ||
|
|
e2b900392e | ||
|
|
45aad2c76d | ||
|
|
adaabab5f7 | ||
|
|
eed5330d76 | ||
|
|
802418a8ad | ||
|
|
d5491e40af | ||
|
|
50920b2aec | ||
|
|
c149315f80 | ||
|
|
e6c9f22057 | ||
|
|
929cc5245d | ||
|
|
9330384aac | ||
|
|
9fda4ba6d4 | ||
|
|
bbd09e955f | ||
|
|
ff5a050861 | ||
|
|
65dad93ec6 | ||
|
|
1c37c4861b | ||
|
|
28ca8f5aa6 | ||
|
|
9857a5422c | ||
|
|
f5e46be204 | ||
|
|
68ad3d52a7 | ||
|
|
91589944d2 | ||
|
|
868ee61e14 | ||
|
|
9903ce97b4 | ||
|
|
6a32654770 | ||
|
|
53add3acc1 | ||
|
|
7ecf301e44 | ||
|
|
7ffc9b9f4b | ||
|
|
9f7bc8b78e | ||
|
|
c1db558214 | ||
|
|
686ab1150c | ||
|
|
254fd2085d | ||
|
|
55e042d5f1 | ||
|
|
a331d2950f | ||
|
|
d900d9c094 | ||
|
|
202578e518 | ||
|
|
bbbc0324c0 | ||
|
|
849a6cc523 | ||
|
|
340b9c4c40 | ||
|
|
2f5c34dec2 | ||
|
|
5a02131cb7 | ||
|
|
b713c6dd6b | ||
|
|
f428b293c1 | ||
|
|
26030f63f3 | ||
|
|
c85dac6067 | ||
|
|
0b4ead23f5 | ||
|
|
bef5498cc2 | ||
|
|
03f882a83c | ||
|
|
94eab7a868 | ||
|
|
bbd107ceff | ||
|
|
56c7b6e39c | ||
|
|
0f407f5537 | ||
|
|
dcf4e69c8b | ||
|
|
0522211a9f | ||
|
|
67647fed59 | ||
|
|
9eaa5a0660 | ||
|
|
79f4f38688 | ||
|
|
02af155afb | ||
|
|
9c88025adf | ||
|
|
94bda8f880 | ||
|
|
2229538c82 | ||
|
|
5af3e80876 | ||
|
|
16c1e15f18 | ||
|
|
95361359f0 | ||
|
|
fbd482f486 | ||
|
|
3694a63c2c | ||
|
|
579f7020ca | ||
|
|
fd7810dca4 | ||
|
|
0cce907c5d | ||
|
|
38785af7c0 | ||
|
|
5123b2f434 | ||
|
|
834444936b | ||
|
|
f1d59376c4 | ||
|
|
1cf48cc7ff | ||
|
|
4fb5ba0767 | ||
|
|
436a227a03 | ||
|
|
4d20385201 | ||
|
|
9ba7b5e46a | ||
|
|
97ac58820e | ||
|
|
98c268f396 | ||
|
|
a9e8194913 | ||
|
|
2b6b7f1036 | ||
|
|
4dd75df5e6 | ||
|
|
c7947450ce | ||
|
|
449772b65c | ||
|
|
64f46a074a | ||
|
|
94e5546630 | ||
|
|
a5e629cda2 | ||
|
|
8038173b65 | ||
|
|
fd16e87068 | ||
|
|
7d35b54cda | ||
|
|
766f9710f7 | ||
|
|
6395fb308b | ||
|
|
443d7d3a2f | ||
|
|
091ccc8c12 | ||
|
|
ec98725026 | ||
|
|
a88de000b7 | ||
|
|
aec64f68a3 | ||
|
|
2993df3b05 | ||
|
|
36fb5bd76f | ||
|
|
a5c05472e0 | ||
|
|
0173da5b6a | ||
|
|
d6d037376b | ||
|
|
6d61b917c7 | ||
|
|
f83963b6df | ||
|
|
030b3cb0c1 | ||
|
|
8f3b6db776 | ||
|
|
80721afd52 | ||
|
|
7dfa4f45b0 | ||
|
|
297383887a | ||
|
|
f1b0f0417f | ||
|
|
92a04c2d8f | ||
|
|
7a5c68b898 | ||
|
|
856c63ae39 | ||
|
|
257fc37717 | ||
|
|
2f646b2fea | ||
|
|
093805f165 | ||
|
|
c642933d8b | ||
|
|
d2c3af5c06 | ||
|
|
2ce7d69979 | ||
|
|
b45db75885 | ||
|
|
d8a302fef0 | ||
|
|
b7968aebb4 | ||
|
|
cbba24023b | ||
|
|
701c6c09d0 | ||
|
|
14d0ff971c | ||
|
|
bcd1399e4b | ||
|
|
7d132400cc | ||
|
|
8df1c9bab3 | ||
|
|
b0bf9ea03e | ||
|
|
da510223c1 | ||
|
|
57c51c0073 | ||
|
|
0861118ba0 | ||
|
|
1b9d57b704 | ||
|
|
f4506696cc | ||
|
|
c24f4ab415 | ||
|
|
a31dc7e3ad | ||
|
|
3978260801 | ||
|
|
4c9b772424 | ||
|
|
c8265aea95 | ||
|
|
97f7104d32 | ||
|
|
9abeffa452 | ||
|
|
200115da86 | ||
|
|
13e1522f1a | ||
|
|
882b544c0d | ||
|
|
7ddc07b6f1 | ||
|
|
1c0585baa2 | ||
|
|
72fbd8094f | ||
|
|
98cf184030 | ||
|
|
65abadc621 | ||
|
|
23277bc4fc | ||
|
|
72523cf2ae | ||
|
|
cf5aab2ed4 | ||
|
|
a3b9bcad94 | ||
|
|
f62b555626 | ||
|
|
5be1f4db46 | ||
|
|
b217ddb3d3 | ||
|
|
4dd8ac9760 | ||
|
|
15644bc992 | ||
|
|
1057133b92 | ||
|
|
35e9016e51 | ||
|
|
bea807f5e4 | ||
|
|
7f6165dd37 | ||
|
|
3ce2e1faa0 | ||
|
|
1c0fc4fc30 | ||
|
|
187f8ace46 | ||
|
|
010a536fe6 | ||
|
|
7af7efa477 | ||
|
|
03d091757b | ||
|
|
503d626cab | ||
|
|
31ad80595c | ||
|
|
227fa64532 | ||
|
|
0b0ace4328 | ||
|
|
760cd74c83 | ||
|
|
027101e6e7 | ||
|
|
a9f22ace78 | ||
|
|
316838cc61 | ||
|
|
bf022369db | ||
|
|
531ab02fee | ||
|
|
7413aa2c00 | ||
|
|
14df18bd33 | ||
|
|
b3ca072578 | ||
|
|
46b12f99a8 | ||
|
|
59849458ed | ||
|
|
6beddecc2a | ||
|
|
a963d3e979 | ||
|
|
97699273ae | ||
|
|
efa9153697 | ||
|
|
da85de6222 | ||
|
|
be3486f252 | ||
|
|
02abc5f245 | ||
|
|
9808ed1bb3 | ||
|
|
6891d0c849 | ||
|
|
d593015640 | ||
|
|
f8a29efdaf | ||
|
|
7a582eb598 | ||
|
|
f057ccf6cb | ||
|
|
92b784a524 | ||
|
|
3f14c78994 | ||
|
|
6002d561db | ||
|
|
5b2842b637 | ||
|
|
1b9f53a495 | ||
|
|
4a9195deac | ||
|
|
b27c030b5f | ||
|
|
178c74421c | ||
|
|
0ed098a0ac | ||
|
|
6f57594c5c | ||
|
|
566009475a | ||
|
|
cee7f86d53 | ||
|
|
1eb7049611 | ||
|
|
c912ccfeca | ||
|
|
be8c964782 | ||
|
|
b6fb90d3ed | ||
|
|
df6709cc7e | ||
|
|
27d2ae9599 | ||
|
|
12619ea24e | ||
|
|
65ef0cc75f | ||
|
|
6dea5cece8 | ||
|
|
9d1497f927 | ||
|
|
e4436705a4 | ||
|
|
d69f397704 | ||
|
|
0f42ec395d | ||
|
|
e6476d0473 | ||
|
|
0023ea3487 | ||
|
|
780c03cf3a | ||
|
|
8a8cb10d3d | ||
|
|
d22ebe3835 | ||
|
|
75ce722c84 | ||
|
|
98ffc6e1c4 | ||
|
|
3086c7365c | ||
|
|
307d47c6c8 | ||
|
|
20e6a0e5fe | ||
|
|
b131fc663c | ||
|
|
b2ab7346ec | ||
|
|
d1c92a4340 | ||
|
|
0056250d5d | ||
|
|
1e9f878de4 | ||
|
|
c1dbfcb5f6 | ||
|
|
971a7e5eb8 | ||
|
|
958891d1ef | ||
|
|
bd45145f2a | ||
|
|
e544adafa8 | ||
|
|
b031fa388d | ||
|
|
702aea84a0 | ||
|
|
af21324c3f | ||
|
|
235de96620 | ||
|
|
fb2f267cfd | ||
|
|
0904e57668 | ||
|
|
98bd0c00fe | ||
|
|
1201ccae5d | ||
|
|
250fd30d80 | ||
|
|
808d178f09 | ||
|
|
69813a0dd4 | ||
|
|
49479d3402 | ||
|
|
e38dfa690c | ||
|
|
7872a38e24 | ||
|
|
6f25a29843 | ||
|
|
a716f3d43f | ||
|
|
965fe7bfe2 | ||
|
|
c91afcf595 | ||
|
|
ecbac9cc18 | ||
|
|
50c39fe2e7 | ||
|
|
96c28ed60a | ||
|
|
abfa219d09 | ||
|
|
e36db5c88b | ||
|
|
dac64ab37e | ||
|
|
38a8789d0b | ||
|
|
f5a458502a | ||
|
|
8112df483b | ||
|
|
249e2f6812 | ||
|
|
a12bea08ae | ||
|
|
230cd53943 | ||
|
|
8ede94a63b | ||
|
|
42582ea592 | ||
|
|
0f6fb0cb6a | ||
|
|
9a8d5e5377 | ||
|
|
0a43438e76 | ||
|
|
6901e40f5d | ||
|
|
888f54ed86 | ||
|
|
7d2c685499 | ||
|
|
b754edafbd | ||
|
|
ea390b4046 | ||
|
|
242261b561 | ||
|
|
0fda822640 | ||
|
|
a2dd36dd1a | ||
|
|
12d1a43d8f | ||
|
|
ed2a8d2c38 | ||
|
|
edf0e1314f | ||
|
|
4b68b24ade | ||
|
|
58a2de982e | ||
|
|
6cc47dec86 | ||
|
|
eaaace1e62 | ||
|
|
53fd2214b8 | ||
|
|
45c6b79856 | ||
|
|
9d93c11b31 | ||
|
|
565cc4c936 | ||
|
|
5f6b7e228a | ||
|
|
6bf6419e8f | ||
|
|
a583931cfc | ||
|
|
dfd62ef307 | ||
|
|
16596a9af7 | ||
|
|
0cc10e2109 | ||
|
|
4399eb3ec0 | ||
|
|
a69cad2244 | ||
|
|
fa4278b067 | ||
|
|
6ce4c7553c | ||
|
|
a1e9c1c7fd | ||
|
|
f30a7f7790 | ||
|
|
804949abdd | ||
|
|
5e4f3d9fb6 | ||
|
|
10775e9845 | ||
|
|
610dec100b | ||
|
|
acba13bf6e | ||
|
|
98e176fb43 | ||
|
|
5ede493847 | ||
|
|
082ea0e60d | ||
|
|
044d9aa2be | ||
|
|
70abcf60ef | ||
|
|
d3d6b48fb2 | ||
|
|
5c59c179d6 | ||
|
|
d0c13a180d | ||
|
|
e262fc3008 | ||
|
|
b55c5592f4 | ||
|
|
abff4435e1 | ||
|
|
7610ba5977 | ||
|
|
86c00be798 | ||
|
|
7ae06c350a | ||
|
|
4af09754d1 | ||
|
|
6d6cee883a | ||
|
|
74b1f34a5c | ||
|
|
5466f1cc10 | ||
|
|
238de611d9 | ||
|
|
ba1fa76b28 | ||
|
|
f66b22888b | ||
|
|
c53ff6ef4e | ||
|
|
970b434870 | ||
|
|
74cd4fe758 | ||
|
|
216880db8c | ||
|
|
82f6b07b0c | ||
|
|
640464fd0b | ||
|
|
8e93b47835 | ||
|
|
fe544f5dc2 | ||
|
|
5a0e7e88c6 | ||
|
|
2969bb9144 | ||
|
|
0ae19a322c | ||
|
|
e6520a8fa7 | ||
|
|
beb1314428 | ||
|
|
e9e75a71ac | ||
|
|
c389584a20 | ||
|
|
cfab3e070c | ||
|
|
73fb6acafa | ||
|
|
50eb010352 | ||
|
|
0b035a23cd | ||
|
|
b32b91ff3b | ||
|
|
ae8118bbe0 | ||
|
|
0315d1c100 | ||
|
|
4f067fa44d | ||
|
|
af62e1e5bf | ||
|
|
baeaa20890 | ||
|
|
03e166eac5 | ||
|
|
a095644945 | ||
|
|
addb80744c | ||
|
|
8646e9bdf2 | ||
|
|
3a55d3780f | ||
|
|
2b0783a53e | ||
|
|
746a6b98e5 | ||
|
|
23fe92d83e | ||
|
|
7932f5ff84 | ||
|
|
26b9d92ea0 | ||
|
|
05700e83c4 | ||
|
|
af0f7f287e | ||
|
|
ad1cb41cf4 | ||
|
|
83cc2858ef | ||
|
|
795004daff | ||
|
|
e143c7ffb2 | ||
|
|
8011709780 | ||
|
|
e523044b75 | ||
|
|
c28dc43465 | ||
|
|
62aa2c594e | ||
|
|
c954d45879 | ||
|
|
dda04cb17b | ||
|
|
f239c9ec40 | ||
|
|
76dfa59d76 | ||
|
|
6ed6267f2e | ||
|
|
facf765a30 | ||
|
|
0b156e6e24 | ||
|
|
45be1ce013 | ||
|
|
d4dfe13042 | ||
|
|
06783018c0 | ||
|
|
6fed285454 | ||
|
|
2852e56e24 | ||
|
|
1d2fdffed6 | ||
|
|
e3cd89e534 | ||
|
|
bdccb3677b | ||
|
|
cce6a5b9e7 | ||
|
|
c5e1d241e0 | ||
|
|
31ed5b5854 | ||
|
|
03124e7323 | ||
|
|
70ee3a98c7 | ||
|
|
2dfee525f5 | ||
|
|
b2c3833c13 | ||
|
|
010d6fedd9 | ||
|
|
c3e1afef8a | ||
|
|
11894119f0 | ||
|
|
a1ac241ab5 | ||
|
|
bbadba7c30 | ||
|
|
f1a42a2312 | ||
|
|
2da4551280 | ||
|
|
8c2ff4583c | ||
|
|
48934ef692 | ||
|
|
ca68fcfd21 | ||
|
|
df97e7c6d4 | ||
|
|
b8d47f8e71 | ||
|
|
08a6c7e652 | ||
|
|
377dab30e6 | ||
|
|
4b1433bdbf | ||
|
|
f1407e7881 | ||
|
|
9c8852d10e | ||
|
|
23a6b7eae0 | ||
|
|
4decc95b23 | ||
|
|
d1e7298104 | ||
|
|
a8d5296731 | ||
|
|
2d5f7d1865 | ||
|
|
94351d50da | ||
|
|
19e18ce394 | ||
|
|
2205e8e5cb | ||
|
|
f1dc6f6f6a | ||
|
|
228db85f95 | ||
|
|
1a1d902f91 | ||
|
|
3ad5292b0c | ||
|
|
0b7d3c50ce | ||
|
|
5b98fb2c86 | ||
|
|
63cf266ed7 | ||
|
|
b7f877cf05 | ||
|
|
bb992187cb | ||
|
|
e1fba76efa | ||
|
|
da0b0d9308 | ||
|
|
e5458b3f40 | ||
|
|
b0d3a12f0c | ||
|
|
c343c4687d | ||
|
|
9369f9fa93 | ||
|
|
9687e967a9 | ||
|
|
1fef22020d | ||
|
|
1d0b8277fe | ||
|
|
e277be69a9 | ||
|
|
ee48d61efa | ||
|
|
be22e68934 | ||
|
|
363e6638b8 | ||
|
|
77d70fa8a8 | ||
|
|
54d6590ada | ||
|
|
24b170ce1c | ||
|
|
d2d38c55d9 | ||
|
|
6a517c04f3 | ||
|
|
d7fa9e1b87 | ||
|
|
c810b20c7e | ||
|
|
2c13241622 | ||
|
|
cd93407214 | ||
|
|
98d2efdc80 | ||
|
|
9afe89626b | ||
|
|
65764ac3bd | ||
|
|
35975a03b9 | ||
|
|
5cad60a867 | ||
|
|
9d7cf356f7 | ||
|
|
5a8b4055bd | ||
|
|
fd591e5c3c | ||
|
|
aa548137b1 | ||
|
|
2a052f3116 | ||
|
|
61f2cd90fc | ||
|
|
bec7b4581d | ||
|
|
5eef55f7f0 | ||
|
|
3fd4ae3aad | ||
|
|
59846be69e | ||
|
|
9eaa13e884 | ||
|
|
2260603090 | ||
|
|
2bd6b831ad | ||
|
|
203fb48030 | ||
|
|
657796af78 | ||
|
|
3032940939 | ||
|
|
90f014c09c | ||
|
|
9b6649772d | ||
|
|
3dc91b0dd6 | ||
|
|
71afc7fef6 | ||
|
|
7cdf54696b | ||
|
|
cd7fecaac4 | ||
|
|
498a43e32a | ||
|
|
018ea48691 | ||
|
|
29b9307a09 | ||
|
|
155a23691f | ||
|
|
f47604455e | ||
|
|
b9b7dd43df | ||
|
|
45f147f31a | ||
|
|
45f4be62c7 | ||
|
|
f1aef8e470 | ||
|
|
3cdd4da223 | ||
|
|
977c5d8a71 | ||
|
|
b133075ce9 | ||
|
|
6259f5ce36 | ||
|
|
e23f485473 | ||
|
|
279e09d430 | ||
|
|
42c0b696c8 | ||
|
|
b47b03906f | ||
|
|
6a937f00ea | ||
|
|
e2d62c86d1 | ||
|
|
f9072ecdfa | ||
|
|
8a2b7a6959 | ||
|
|
b0bcc7ab37 | ||
|
|
546bef5ca0 | ||
|
|
d655b46b4f | ||
|
|
5d220ee364 | ||
|
|
b0905c7e63 | ||
|
|
e377c92a9e | ||
|
|
28c0b2c4b4 | ||
|
|
7a68bb86c0 | ||
|
|
e8db5c1b08 | ||
|
|
7b2d3fd7d3 | ||
|
|
4a3f143d90 | ||
|
|
dd39241ab8 | ||
|
|
b4f0d489c6 | ||
|
|
3ea4d95848 | ||
|
|
4331cd5b56 | ||
|
|
daa5108573 | ||
|
|
c3879b79cb | ||
|
|
54f973545c | ||
|
|
e322f07a13 | ||
|
|
5675ce56b1 | ||
|
|
086f541d35 | ||
|
|
5cf6f1bca4 | ||
|
|
830450537d | ||
|
|
9a3bf3ed67 | ||
|
|
aac42bb807 | ||
|
|
7d2fbb3e57 | ||
|
|
a81e69490d | ||
|
|
4cc6cace9a | ||
|
|
da716b3beb | ||
|
|
dffa229e40 | ||
|
|
b018d3d41d | ||
|
|
89a0a6303f | ||
|
|
76bb27e3ab | ||
|
|
62ddc5e628 | ||
|
|
024198c8c7 | ||
|
|
c26fdc549a | ||
|
|
0d97075d54 | ||
|
|
1ff81465ad | ||
|
|
8ec615cd6d | ||
|
|
58699712a6 | ||
|
|
00f24b4cd3 | ||
|
|
5f949f38c0 | ||
|
|
f36c41aa44 | ||
|
|
6b52367852 | ||
|
|
b6a31439a7 | ||
|
|
d1e76a8ff7 | ||
|
|
9cbfe5074c | ||
|
|
417335e894 | ||
|
|
f7085cc8df | ||
|
|
9219484760 | ||
|
|
5533f569b3 | ||
|
|
7e5e009971 | ||
|
|
8ac70863a4 | ||
|
|
335865bda6 | ||
|
|
c3a084b1a6 | ||
|
|
a030155ea9 | ||
|
|
a39861f4e7 | ||
|
|
115cd4f76c | ||
|
|
94c81290e8 | ||
|
|
4e2be18634 | ||
|
|
c8a58e331d | ||
|
|
9ae0d58ee3 | ||
|
|
361681015c | ||
|
|
8afa7456ca | ||
|
|
69429111c5 | ||
|
|
80321f6235 | ||
|
|
70d7eafa1a | ||
|
|
7468d1e0ce | ||
|
|
7cd63ad545 | ||
|
|
442decd201 | ||
|
|
57aca97e92 | ||
|
|
a93c16fea6 | ||
|
|
851e78280a | ||
|
|
d5f642163a | ||
|
|
8d99094189 | ||
|
|
6d085a2cde | ||
|
|
183cfc1de5 | ||
|
|
0f486f49fe | ||
|
|
257f732a37 | ||
|
|
b7729c178b | ||
|
|
8556c36e00 | ||
|
|
b9d848b4cf | ||
|
|
7267ab8175 | ||
|
|
be89891be0 | ||
|
|
5ec5057d0a | ||
|
|
1df89cad82 | ||
|
|
81c146d10d | ||
|
|
9143c12e22 | ||
|
|
b90ee6b210 | ||
|
|
b77e08c1c9 | ||
|
|
90f4dbf1a1 | ||
|
|
db7d243c8f | ||
|
|
ee8a19117e | ||
|
|
99a935dac7 | ||
|
|
dc8db53a45 | ||
|
|
248d89b9cc | ||
|
|
3988715917 | ||
|
|
fb036b75a2 | ||
|
|
979de1afa6 | ||
|
|
d7f5c3019f | ||
|
|
b8dbb4b2c6 | ||
|
|
e713a4f058 | ||
|
|
5f0ad8d41c | ||
|
|
3611b37ba0 | ||
|
|
473e82cb8c | ||
|
|
f57646dde9 | ||
|
|
82e898604d | ||
|
|
f66bc508bb | ||
|
|
0e839c4de3 | ||
|
|
3c0523733f | ||
|
|
56acb429b7 | ||
|
|
e35061937a | ||
|
|
052b1ad46c | ||
|
|
557d51cb41 | ||
|
|
f5f9547e83 | ||
|
|
c7e765a2bc | ||
|
|
84289e3471 | ||
|
|
fadadc732a | ||
|
|
a7b9c81705 | ||
|
|
87f8aaab9b | ||
|
|
726718c7ca | ||
|
|
8e1a5563d5 | ||
|
|
eb66c4e48c | ||
|
|
8e76ad46da | ||
|
|
8627a960c4 | ||
|
|
c0d2aeb525 | ||
|
|
60b4138b44 | ||
|
|
a105c8f0f8 | ||
|
|
06717dedd9 | ||
|
|
e926a52518 | ||
|
|
ec75abee78 | ||
|
|
7e482c0939 | ||
|
|
d68e198447 | ||
|
|
011b24df19 | ||
|
|
3e33116637 | ||
|
|
ae25810f0b | ||
|
|
52f28d3b62 | ||
|
|
ce863d3f04 | ||
|
|
afa85b2adc | ||
|
|
0e73c84a5e | ||
|
|
249a90e38b | ||
|
|
56369d2919 | ||
|
|
173db83bd4 | ||
|
|
b4ee18c8ea | ||
|
|
b6f583a4cd | ||
|
|
074fb80298 | ||
|
|
2fbb012d4f | ||
|
|
fe5c96ddf9 | ||
|
|
636484d859 | ||
|
|
1d0f3b2a5e | ||
|
|
1a09822e91 | ||
|
|
71cf4d4cfe | ||
|
|
4d1ee50590 | ||
|
|
0dad8f4bf3 | ||
|
|
0993b6df74 | ||
|
|
7250cf7941 | ||
|
|
23c62b7853 | ||
|
|
05636c79ec | ||
|
|
e84ff7c5c5 | ||
|
|
756156a448 | ||
|
|
757098ff2d | ||
|
|
64ccf7f8fa | ||
|
|
06c9050fb2 | ||
|
|
48f087777e | ||
|
|
f60f070da2 | ||
|
|
642bee372a | ||
|
|
edc86f6459 | ||
|
|
3b0ca25d60 | ||
|
|
753648b7b0 | ||
|
|
8c1a63f559 | ||
|
|
53902341d6 | ||
|
|
e473f22a11 | ||
|
|
feca94a326 | ||
|
|
296e11a8a9 | ||
|
|
5f83b5b72f | ||
|
|
051b2f91a1 | ||
|
|
8ac32f357f | ||
|
|
ba06a9c119 | ||
|
|
fd1f43602e | ||
|
|
435326e09b | ||
|
|
2af3c6b4f8 | ||
|
|
0c983cce44 | ||
|
|
f65cb92457 | ||
|
|
4a9747272f | ||
|
|
30e1601d74 | ||
|
|
d5bd57c8f5 | ||
|
|
b29e880434 | ||
|
|
115a0d679b | ||
|
|
7598b8ea0a | ||
|
|
1bcd9d9f35 | ||
|
|
ccda16dbd5 | ||
|
|
c081272788 | ||
|
|
9136a712b0 | ||
|
|
087be66174 | ||
|
|
efcc10546e | ||
|
|
73d05cd0dd | ||
|
|
b31b8f664b | ||
|
|
7a00afbe54 | ||
|
|
ae9f468a6d | ||
|
|
2dde4b4850 | ||
|
|
baac5f8a32 | ||
|
|
c89f478f20 | ||
|
|
aa411fdc6c | ||
|
|
7f2e729839 | ||
|
|
d8fdd66aa0 | ||
|
|
1005a0f58d | ||
|
|
9027bc6fd1 | ||
|
|
bbd7ccc556 | ||
|
|
703714bb0d | ||
|
|
9cea519dcc | ||
|
|
cb103d1292 | ||
|
|
7911c7b471 | ||
|
|
b60d3b2502 | ||
|
|
37811a8b1e | ||
|
|
6057b268e5 | ||
|
|
1a64de44ac | ||
|
|
27351b3719 | ||
|
|
cc89ac4383 | ||
|
|
c8d481b785 | ||
|
|
75b69292ec | ||
|
|
6549f5b971 | ||
|
|
3c8cbfe3ce | ||
|
|
cbbc24952a | ||
|
|
40aad03f9b | ||
|
|
e46c18082c | ||
|
|
ecd469a934 | ||
|
|
5cab432303 | ||
|
|
0c760c685e | ||
|
|
1e2d2dbfa4 | ||
|
|
11fcbe7543 | ||
|
|
14ef7f4b73 | ||
|
|
3bfd2caea0 | ||
|
|
3d7cceb3ea | ||
|
|
cb8a1757f8 | ||
|
|
ed9b1ae8e8 | ||
|
|
16f2b6ea84 | ||
|
|
d53d269877 | ||
|
|
bf55992223 | ||
|
|
6d3015c890 | ||
|
|
c5f83d3c3c | ||
|
|
70351252d1 | ||
|
|
eaaa43ea79 | ||
|
|
080380a96a | ||
|
|
c48a4f623f | ||
|
|
0bac4dbb6a | ||
|
|
46cf347e76 | ||
|
|
99fe4a2e98 | ||
|
|
24fb93fe64 | ||
|
|
4aa48f66a9 | ||
|
|
dfb30147a0 | ||
|
|
6428b569a5 | ||
|
|
757ff89af2 | ||
|
|
941d25660c | ||
|
|
42900d9f43 | ||
|
|
83fee5d632 | ||
|
|
cdc0eb4656 | ||
|
|
2da5a3b799 | ||
|
|
9512ba2c44 | ||
|
|
f953de8ee5 | ||
|
|
0b5ad91dff | ||
|
|
0cd9c8ce71 | ||
|
|
86c4cc9c0e | ||
|
|
f9a5a71c42 | ||
|
|
0db13364db | ||
|
|
98a4f19971 | ||
|
|
7b5c7a61ae | ||
|
|
8574d1516e | ||
|
|
9f0664ff06 | ||
|
|
883d760cb7 | ||
|
|
9739094b76 | ||
|
|
6f7182cc9e | ||
|
|
f804ce94fd | ||
|
|
ea102bbd97 | ||
|
|
8763efd025 | ||
|
|
24b33ed89a | ||
|
|
316af17a7c | ||
|
|
93bb928633 | ||
|
|
3327d3dd80 | ||
|
|
537338aa0f | ||
|
|
8863192008 | ||
|
|
82a869487e | ||
|
|
1a3e80436d | ||
|
|
9c7eb2b810 | ||
|
|
e27a2d9c23 | ||
|
|
c0146287af | ||
|
|
d20c735f4b | ||
|
|
d1cfd0f31e | ||
|
|
8108f1a2f3 | ||
|
|
032c2cd954 | ||
|
|
e6f1b0a394 | ||
|
|
e69aaa6233 | ||
|
|
fd4ca0b3d1 | ||
|
|
1f5657da68 | ||
|
|
9eb5cd1fc6 | ||
|
|
8b7a7b8c7a | ||
|
|
6dfdfae7e0 | ||
|
|
436aad14d0 | ||
|
|
b1959c1288 | ||
|
|
9104340b9d | ||
|
|
eb6f907c08 | ||
|
|
ca9ebba25e | ||
|
|
378d24f2c5 | ||
|
|
ae09f8d443 | ||
|
|
64ec1314e8 | ||
|
|
be9bb79ad4 | ||
|
|
dc6f71ec62 | ||
|
|
9439efc753 | ||
|
|
e0f1b9d36e | ||
|
|
acb6268aef | ||
|
|
8d0a28fb99 | ||
|
|
63a28893df | ||
|
|
120a19b21e | ||
|
|
29f17c279d | ||
|
|
d4ef6f237c | ||
|
|
22b0405153 | ||
|
|
5eaf350e4d | ||
|
|
b7429dcce6 | ||
|
|
6cc92c6982 | ||
|
|
f6c9db7482 | ||
|
|
40ab5d5bb7 | ||
|
|
8e9219673a | ||
|
|
4802f849a1 | ||
|
|
f4f1134614 | ||
|
|
8f65c2f0f3 | ||
|
|
c2e572b175 | ||
|
|
327f0619fb | ||
|
|
43507953e8 | ||
|
|
5fe03d31fe | ||
|
|
a768bed3e6 | ||
|
|
a566725f25 | ||
|
|
d28a4523ee | ||
|
|
18d5b7cb6e | ||
|
|
5d287f88b9 | ||
|
|
eca7b41080 | ||
|
|
78a5d961e4 | ||
|
|
6a3a0442c4 | ||
|
|
e29d0b1ffa | ||
|
|
d542592fb5 | ||
|
|
b7338057cc | ||
|
|
3a0727afd2 | ||
|
|
6cf8ebbe45 | ||
|
|
da762395ba | ||
|
|
0f7fe504ab | ||
|
|
799a730812 | ||
|
|
88a00e9751 | ||
|
|
f60cadf82e | ||
|
|
e11560c635 | ||
|
|
07d82867a3 | ||
|
|
d40fad76f5 | ||
|
|
2c3c052d3b | ||
|
|
63064fabb7 | ||
|
|
3b68433274 | ||
|
|
42c9dff41e | ||
|
|
27de4597a6 | ||
|
|
b6b4577496 | ||
|
|
025dc2ee54 | ||
|
|
6214701cc2 | ||
|
|
3034f1ace0 | ||
|
|
880aa78671 | ||
|
|
eedf6b6a11 | ||
|
|
a461f8bb3e | ||
|
|
c86df45376 | ||
|
|
76a7c8023e | ||
|
|
5faa74d19f | ||
|
|
99a40eb6c7 | ||
|
|
8d0e5ab62f | ||
|
|
a665652b11 | ||
|
|
1134cc9f59 | ||
|
|
93a7a4d14a | ||
|
|
9a70a75f31 | ||
|
|
b051c478c4 | ||
|
|
8203266aec | ||
|
|
635a92d18f | ||
|
|
19e99e6e78 | ||
|
|
8321fc3476 | ||
|
|
287b848a65 | ||
|
|
388c9aa2ec | ||
|
|
fa81f87561 | ||
|
|
56a75772b4 | ||
|
|
271e02c0ee | ||
|
|
b32d0c7a6c | ||
|
|
20b4788d0d | ||
|
|
bb2e9c2c2c | ||
|
|
880d97e874 | ||
|
|
57830ce3ed | ||
|
|
cc23a45a9d | ||
|
|
230a7ff47b | ||
|
|
52bec82668 | ||
|
|
fa5bd9297b | ||
|
|
feeba142d8 | ||
|
|
5380cf1a3f | ||
|
|
732e41b9b0 | ||
|
|
e52dab2680 | ||
|
|
65c886f861 | ||
|
|
0901b557a3 | ||
|
|
4a38d41c48 | ||
|
|
91a36883b4 | ||
|
|
f9b34586bb | ||
|
|
2b3e82d158 | ||
|
|
afa5a140a3 | ||
|
|
ab42f6b19a | ||
|
|
ed03f4a53b | ||
|
|
b29ce7b913 | ||
|
|
6ecde8e873 | ||
|
|
349827b496 | ||
|
|
566280ff01 | ||
|
|
48c3e4f591 | ||
|
|
5895d7cae7 | ||
|
|
5d81450339 | ||
|
|
1359f3ea0d | ||
|
|
40be396b0a | ||
|
|
568a04e5b9 | ||
|
|
9dccfe4dc7 | ||
|
|
102c757d25 | ||
|
|
f5420b0768 | ||
|
|
557b7201c5 | ||
|
|
4e6a5574ed | ||
|
|
34d3e2d36e | ||
|
|
a6998d8139 | ||
|
|
b3cdd83200 | ||
|
|
7fa0debde1 | ||
|
|
3ee07604b9 | ||
|
|
949fca5556 | ||
|
|
e62d86c4b0 | ||
|
|
f560805a24 | ||
|
|
bb4b035c38 | ||
|
|
e72bd80476 | ||
|
|
b9a9c638b9 | ||
|
|
0644f58d96 | ||
|
|
edf63a8140 | ||
|
|
ac0a00c47f | ||
|
|
49b963c629 | ||
|
|
951dcf9a51 | ||
|
|
e925033fcc | ||
|
|
4faa9556b4 | ||
|
|
ef01346a39 | ||
|
|
9a8c0776be | ||
|
|
326cd05522 | ||
|
|
53d14b177f | ||
|
|
ff8fc03c8d | ||
|
|
9dad1a7480 | ||
|
|
346397109f | ||
|
|
db7196ece3 | ||
|
|
a10e32c15f | ||
|
|
817b68ea59 | ||
|
|
996bc9853d | ||
|
|
e7b60c1e74 | ||
|
|
b75016a48d | ||
|
|
b9d542dbb3 | ||
|
|
fa03128bfc | ||
|
|
e1c418b25e | ||
|
|
d87dda8323 | ||
|
|
9f8f354e23 | ||
|
|
f242b36c64 | ||
|
|
50917cf31a | ||
|
|
a040ae57ae | ||
|
|
3ac8851e40 | ||
|
|
757a4596be | ||
|
|
51cc3b4271 | ||
|
|
7e05b57fa1 | ||
|
|
145108ea12 | ||
|
|
0f2b1cceab | ||
|
|
e1f4278914 | ||
|
|
6e9f9ae056 | ||
|
|
f6b8b40eb6 | ||
|
|
16d2e29774 | ||
|
|
9a4dbac756 | ||
|
|
c9a6ac31d9 | ||
|
|
9bdddc457f | ||
|
|
90eaccdd0c | ||
|
|
7c4dbb8dbf | ||
|
|
905574a1dc | ||
|
|
551b3d3a3c | ||
|
|
b5063acf60 | ||
|
|
c1c7a15e4f | ||
|
|
279f02862e | ||
|
|
6df760beae | ||
|
|
571dc0a4f6 | ||
|
|
ee38cc61e3 | ||
|
|
89953180d4 | ||
|
|
0ae1379170 | ||
|
|
28bbb4874f | ||
|
|
9af54628dc | ||
|
|
1884c58422 | ||
|
|
e34f6a68e7 | ||
|
|
4fde97cb20 | ||
|
|
92a03d414d | ||
|
|
55bd263a08 | ||
|
|
71c0409a6f | ||
|
|
d2e504a0be | ||
|
|
185690a84c | ||
|
|
57596579e8 | ||
|
|
f9bea43ea7 | ||
|
|
921bd3db0f | ||
|
|
5e50e28b23 | ||
|
|
ed6c492c72 | ||
|
|
7cb2c8b273 | ||
|
|
9556984b7d | ||
|
|
08045ed4d0 | ||
|
|
f65b8744cf | ||
|
|
8dcdc6bfc7 | ||
|
|
905f2be6b4 | ||
|
|
492ba5b929 | ||
|
|
c3ddbba3f9 | ||
|
|
b3d761e29c | ||
|
|
1a27d0b35e | ||
|
|
7a37a09e16 | ||
|
|
b3e1663602 | ||
|
|
24a8d58626 | ||
|
|
ee8f7cf1ea | ||
|
|
1d89ba13a8 | ||
|
|
cf01987632 | ||
|
|
cfa7f285c6 | ||
|
|
6a546bfcdd | ||
|
|
c94d19f6dc | ||
|
|
f509a8da73 | ||
|
|
c684a85a57 | ||
|
|
83fe7f1160 | ||
|
|
a9e3053c86 | ||
|
|
f72b52c6c0 | ||
|
|
741ecff25e | ||
|
|
6712e42cc5 | ||
|
|
37e72936f8 | ||
|
|
c5558bdca7 | ||
|
|
feda65f915 | ||
|
|
1095529fc4 | ||
|
|
d6d508068a | ||
|
|
612e5fca81 | ||
|
|
ee9916d950 | ||
|
|
00e0ab5c99 | ||
|
|
385b97d284 | ||
|
|
c2539c7a3c | ||
|
|
49a4fe17b2 | ||
|
|
8c0b5dafe2 | ||
|
|
1e82124bdf | ||
|
|
f07b9d5336 | ||
|
|
4dbcdc4711 | ||
|
|
e300525db2 | ||
|
|
7f4b1bacaa | ||
|
|
51ac4fd1f9 | ||
|
|
f75a38e338 | ||
|
|
0251b34a12 | ||
|
|
5352bc67ac | ||
|
|
d1be36eefb | ||
|
|
d3b3e2528c | ||
|
|
680601a0b9 | ||
|
|
3a03f34e59 | ||
|
|
2a885a7dee | ||
|
|
9ed2b8a9d6 | ||
|
|
461844976b | ||
|
|
cbfbab8af8 | ||
|
|
6fb58522f2 | ||
|
|
281d4c6864 | ||
|
|
fcf5761229 | ||
|
|
8844268d97 | ||
|
|
e1851239e1 | ||
|
|
09a04721a6 | ||
|
|
54da49d459 | ||
|
|
df162fa9b7 | ||
|
|
5287baf0dd | ||
|
|
9ab6f3e648 | ||
|
|
bbe198f1cd | ||
|
|
2c0cdcc92e | ||
|
|
07ba3afa9f | ||
|
|
6df30b1f86 | ||
|
|
91680b830e | ||
|
|
c29d3a5e98 | ||
|
|
8d14992275 | ||
|
|
d32269fdd2 | ||
|
|
0d5075a770 | ||
|
|
24089289c7 | ||
|
|
64520fd8de | ||
|
|
eeee9b79a1 | ||
|
|
6750050aba | ||
|
|
5be69d4892 | ||
|
|
3a9e412db8 | ||
|
|
995e096741 | ||
|
|
c5faee82f0 | ||
|
|
2bf5f57bf6 | ||
|
|
6c19b5d557 | ||
|
|
66e496d810 | ||
|
|
1fc3cf07dd | ||
|
|
1a894dfdca | ||
|
|
f119856254 | ||
|
|
462ed459e6 | ||
|
|
8e240fd4e3 | ||
|
|
1745dc1f3e | ||
|
|
c9b9f8bd18 | ||
|
|
222f6cf707 | ||
|
|
cba1b581b0 | ||
|
|
c013cee248 | ||
|
|
e765634d67 | ||
|
|
5ec5240251 | ||
|
|
7053a488fd | ||
|
|
86a44dab45 | ||
|
|
24df7c8851 | ||
|
|
82326e0cb1 | ||
|
|
0dbdf666a2 | ||
|
|
33a66930b7 | ||
|
|
bb59c29327 | ||
|
|
139f2f0945 | ||
|
|
9484c8eb63 | ||
|
|
1e8aba76f8 | ||
|
|
6d603a68fb | ||
|
|
24bdff269e | ||
|
|
16d123c9c0 | ||
|
|
c76c9f4743 | ||
|
|
ae6500ede6 | ||
|
|
c6702535c6 | ||
|
|
df40f2f726 | ||
|
|
124fda933a | ||
|
|
c23c9b4ebb | ||
|
|
982322b3cb | ||
|
|
9306bddf1c | ||
|
|
d4a377524a | ||
|
|
5e7f91ab3e | ||
|
|
c4ceb94e79 | ||
|
|
ae10d90aca | ||
|
|
4fc53e9763 | ||
|
|
5f76b3901c | ||
|
|
13784f398f | ||
|
|
e446b22bba | ||
|
|
b8bbfa961c | ||
|
|
5aec49cb38 | ||
|
|
ec37cc5b2c | ||
|
|
ef202812e6 | ||
|
|
43919be03e | ||
|
|
58e89908d8 | ||
|
|
388773cead | ||
|
|
3c13966867 | ||
|
|
b354e92e7c | ||
|
|
22788ff3a7 | ||
|
|
b0f1d99bdc | ||
|
|
c38cab65fb | ||
|
|
75b852f90b | ||
|
|
cce16c6284 | ||
|
|
7dbead77c2 | ||
|
|
c08a8c0e89 | ||
|
|
f9ac65a0fd | ||
|
|
4942cd0588 | ||
|
|
614c3650f5 | ||
|
|
ba4f689b01 | ||
|
|
2f70659466 | ||
|
|
e669ae625e | ||
|
|
fcfa335b6b | ||
|
|
2042f0e822 | ||
|
|
cef435452c | ||
|
|
e004250346 | ||
|
|
87af9cdf8d | ||
|
|
7d968edc43 | ||
|
|
3359a1b099 | ||
|
|
927d4915a0 | ||
|
|
e6fed64e09 | ||
|
|
ad9ac8929b | ||
|
|
a808790b1d | ||
|
|
688c0911a2 | ||
|
|
6c7c1303f7 | ||
|
|
00f07dbbf6 | ||
|
|
222f230fc9 | ||
|
|
d229554fdd | ||
|
|
cdca1530a7 | ||
|
|
ff6ed95e5a | ||
|
|
dc6fba261b | ||
|
|
aedd8eb367 | ||
|
|
3cd2d69bd4 | ||
|
|
07e6c3f6a0 | ||
|
|
cde662694a | ||
|
|
60e36f77fa | ||
|
|
eb04cb4024 | ||
|
|
abf93f277f | ||
|
|
dafb60feb4 | ||
|
|
1197f3645d | ||
|
|
ab1d4cd209 | ||
|
|
0f12d5f0be | ||
|
|
569fd80244 | ||
|
|
012accf773 | ||
|
|
b0e1bf40a2 | ||
|
|
15d8758bc2 | ||
|
|
e91cacdb71 | ||
|
|
e94e3b9fd1 | ||
|
|
f0b0462380 | ||
|
|
722b06322d | ||
|
|
60ecdbd5d2 | ||
|
|
550e159b36 | ||
|
|
638820fc66 | ||
|
|
b2ded0e0e1 | ||
|
|
81b6d7ebe9 | ||
|
|
ae35f7a5d5 | ||
|
|
436d56301e | ||
|
|
03ac6d6ff0 | ||
|
|
04b962c924 | ||
|
|
f717f8d4e5 | ||
|
|
6676fea21a | ||
|
|
a6e21f0374 | ||
|
|
7e388b2b3b | ||
|
|
f119bdb32b | ||
|
|
b38663e917 | ||
|
|
ebd49686eb | ||
|
|
5d8c7a24ec | ||
|
|
3d9076f175 | ||
|
|
58469001da | ||
|
|
997005474d | ||
|
|
fbf299054e | ||
|
|
171a968d37 | ||
|
|
de5493ba3a | ||
|
|
370ca79fde | ||
|
|
1dd7d56ba8 | ||
|
|
0409a23c23 | ||
|
|
b8514f9b27 | ||
|
|
7f6946f97a | ||
|
|
f49f261444 | ||
|
|
bb188f5b26 | ||
|
|
0cf2b2aabe | ||
|
|
eba18d78a7 | ||
|
|
fb4dd2b996 | ||
|
|
1dca31e25e | ||
|
|
be849e8489 | ||
|
|
305011f465 | ||
|
|
1fbc89088d | ||
|
|
39248dc782 | ||
|
|
10481286d7 | ||
|
|
6805da7c62 | ||
|
|
7e2973961c | ||
|
|
a9a4325a76 | ||
|
|
0ffa2ac47e | ||
|
|
3d49f61dd5 | ||
|
|
d70cd913ec | ||
|
|
a36d8df23b | ||
|
|
c866b93ceb | ||
|
|
c9d048ab5f | ||
|
|
252f77a599 | ||
|
|
3f51551e23 | ||
|
|
4411b8594b | ||
|
|
c84f2e8c4c | ||
|
|
f3a0867c79 | ||
|
|
9e5335a29b | ||
|
|
8dd12a6609 | ||
|
|
337da07002 | ||
|
|
ae6a97165b | ||
|
|
bccaa5e2ad | ||
|
|
cf3f01034c | ||
|
|
6a56edbeba | ||
|
|
bcd2d58818 | ||
|
|
7ffc0e059d | ||
|
|
fbdcc13833 | ||
|
|
97ebc66c05 | ||
|
|
8ce1bc42b3 | ||
|
|
6bdc44e4bd | ||
|
|
9bfba6cddd | ||
|
|
f744618f39 | ||
|
|
1fbc625d3e | ||
|
|
6b89dc5695 | ||
|
|
e68c07876a | ||
|
|
b04201c5de | ||
|
|
d0122af735 | ||
|
|
abb6a34388 | ||
|
|
6cdfc0123d | ||
|
|
ef108bc8d3 | ||
|
|
2a369ce3ae | ||
|
|
5cca1fd470 | ||
|
|
812946c290 | ||
|
|
e278e2c093 | ||
|
|
b32db477fd | ||
|
|
92a686c740 | ||
|
|
a9cd1b695c | ||
|
|
a07e86ec30 | ||
|
|
0edf78ba92 | ||
|
|
cb96cc636b | ||
|
|
991408752c | ||
|
|
d952cdee08 | ||
|
|
5c39804f55 | ||
|
|
e488dd7c0a | ||
|
|
e2d9c11817 | ||
|
|
6a2b1c36db | ||
|
|
774423c260 | ||
|
|
8fdc5e0509 | ||
|
|
b56d3508ca | ||
|
|
e60e3dda85 | ||
|
|
9200a04272 | ||
|
|
e8dc7e9bb0 | ||
|
|
f4e2aad4ad | ||
|
|
206de36a01 | ||
|
|
609eb533dd | ||
|
|
6eb6a78b1d | ||
|
|
d90d790e77 | ||
|
|
2b46b5f7bf | ||
|
|
01e65baea6 | ||
|
|
9cba51d49a | ||
|
|
ebf030f08b | ||
|
|
3c5e1a001d | ||
|
|
852818d97e | ||
|
|
32f2b49764 | ||
|
|
dbe3876450 | ||
|
|
1e704c34e8 | ||
|
|
1a146ff521 | ||
|
|
946431f301 | ||
|
|
d088ddbb5e | ||
|
|
a8f704b63f | ||
|
|
fedb0025c1 | ||
|
|
cb6a66c595 | ||
|
|
aecfebcc61 | ||
|
|
287f8cd93d | ||
|
|
dd97ff0b74 | ||
|
|
3b096f68be | ||
|
|
aff3c2be33 | ||
|
|
fd7dcda8bd | ||
|
|
a7a9bb3578 | ||
|
|
0de93e51cb | ||
|
|
ccb9c029f9 | ||
|
|
afec02c51a | ||
|
|
d4ee75a9e7 | ||
|
|
82c5d84111 | ||
|
|
36564f02cd | ||
|
|
829fbf5463 | ||
|
|
73c737fdad | ||
|
|
53745bcf7e | ||
|
|
5487b095dc | ||
|
|
e3b94afd24 | ||
|
|
f1b3118ebf | ||
|
|
4833e928e1 | ||
|
|
36062f8456 | ||
|
|
f599fa4218 | ||
|
|
6881decdfc | ||
|
|
c66ec9ee4c | ||
|
|
332e3c4bca | ||
|
|
cf3306f433 | ||
|
|
a63ce4f9dc | ||
|
|
8b0e67afc0 | ||
|
|
38525ee1e7 | ||
|
|
c20b546b36 | ||
|
|
d969c433a0 | ||
|
|
15bfb086d5 | ||
|
|
38f5cdbcab | ||
|
|
638c44070a | ||
|
|
c10d0f0a09 | ||
|
|
1bf5202b21 | ||
|
|
3cf6072df5 | ||
|
|
d25d6420a6 | ||
|
|
27768025b7 | ||
|
|
71335bf2a1 | ||
|
|
aee5495831 | ||
|
|
46fb7dc7bf | ||
|
|
0c5b10df2f | ||
|
|
2d8f5a34fd | ||
|
|
d4b1e2b5e0 | ||
|
|
579dd09c3d | ||
|
|
9e148f67ed | ||
|
|
11606fe94e | ||
|
|
b49086af5c | ||
|
|
0506c4d654 | ||
|
|
2c88d75a8c | ||
|
|
d7330d867e | ||
|
|
7df76d1b1e | ||
|
|
48a24cfe7f | ||
|
|
236e9dec99 | ||
|
|
a4e47e27ad | ||
|
|
72ec2f4c2b | ||
|
|
30e0ea5f2d | ||
|
|
e2236b277b | ||
|
|
21d48e80de | ||
|
|
10bfccc89c | ||
|
|
56c565c319 | ||
|
|
9a72d9f302 | ||
|
|
e7afd4489e | ||
|
|
76e79577ed | ||
|
|
eb87a1a3eb | ||
|
|
576acd5ef8 | ||
|
|
9457b3b758 | ||
|
|
98d0dbcf55 | ||
|
|
c965e71474 | ||
|
|
91bf0f6176 | ||
|
|
1a2f9c633a | ||
|
|
e05bcb58c5 | ||
|
|
9e7d6951c7 | ||
|
|
b1d124a6b8 | ||
|
|
824d286d99 | ||
|
|
c6bbd3443a | ||
|
|
c6f72c0784 | ||
|
|
271dfc91fa | ||
|
|
ea1f197a54 | ||
|
|
b1fca0f04d | ||
|
|
8bc6b9126f | ||
|
|
48c40eee70 | ||
|
|
55b6c74b3c | ||
|
|
7946578cf0 | ||
|
|
5fb14b6266 | ||
|
|
67cb2d092f | ||
|
|
6b11693531 | ||
|
|
55b6506fcd | ||
|
|
303b67215b | ||
|
|
0c53be010e | ||
|
|
30bc967c4c | ||
|
|
72db20b827 | ||
|
|
2ff528ccc0 | ||
|
|
4fe944c489 | ||
|
|
9ac5880f67 | ||
|
|
78b1e45e5d | ||
|
|
814faff73e | ||
|
|
aa9b57ed4d | ||
|
|
9009cd66f9 | ||
|
|
cd5b536cea | ||
|
|
1c11018cd5 | ||
|
|
a62f7042f7 | ||
|
|
b98c2af9f7 | ||
|
|
71d2f38772 | ||
|
|
b0c46892f1 | ||
|
|
05115772ce | ||
|
|
f1c9932933 | ||
|
|
64d33a1bd9 | ||
|
|
7c773c8631 | ||
|
|
74f427d15f | ||
|
|
50205a232a | ||
|
|
36c607059a | ||
|
|
e22a0ebb2c | ||
|
|
73b7fdf8cd | ||
|
|
1a2458a9c6 | ||
|
|
1861921efa | ||
|
|
47bf8d0aa6 | ||
|
|
7f228583da | ||
|
|
bd0f1f2f4e | ||
|
|
df055e0d00 | ||
|
|
101c263d78 | ||
|
|
5e39bca9de | ||
|
|
169c935592 | ||
|
|
1b876f7004 | ||
|
|
852e7c634f | ||
|
|
26bb61959c | ||
|
|
93724ff8c3 | ||
|
|
6acffc4609 | ||
|
|
d7025f0171 | ||
|
|
f1d5e61649 | ||
|
|
237712ac12 | ||
|
|
2621285164 | ||
|
|
9b66d5a22c | ||
|
|
29fa361dba | ||
|
|
6fa686802d | ||
|
|
c7b9dd52ad | ||
|
|
a3f57fe99c | ||
|
|
f174001cc8 | ||
|
|
02acfe2abe | ||
|
|
7371c8962a | ||
|
|
7c6abe446f | ||
|
|
0a0acd171d | ||
|
|
5a81f41770 | ||
|
|
bf3d6d4e9d | ||
|
|
9611f608f2 | ||
|
|
6c805a37a3 | ||
|
|
19161dd6d7 | ||
|
|
6e8997c8a2 | ||
|
|
4236225a34 | ||
|
|
6c5ff85048 | ||
|
|
9606bd9f91 | ||
|
|
443942b078 | ||
|
|
f241121c98 | ||
|
|
bf33d60bc6 | ||
|
|
326d00182d | ||
|
|
0b44bd5b54 | ||
|
|
3652fbe0d8 | ||
|
|
a531481e69 | ||
|
|
44c0326c8c | ||
|
|
820b79d8d4 | ||
|
|
c98cb16ac9 | ||
|
|
680188af80 | ||
|
|
19ca84ac21 | ||
|
|
a98b10e885 | ||
|
|
dc4926cd90 | ||
|
|
c3aa68e7c9 | ||
|
|
7bc78376e2 | ||
|
|
62fc668f78 | ||
|
|
275dfc0081 | ||
|
|
614859ca8d | ||
|
|
b2292e38fc | ||
|
|
7ba30a7d9a | ||
|
|
8519c28bd1 | ||
|
|
c7fe318214 | ||
|
|
a38ad9b724 | ||
|
|
3706d53375 | ||
|
|
3f3fbed33d | ||
|
|
8749103578 | ||
|
|
2ad6968db7 | ||
|
|
59448b1d77 | ||
|
|
f334d3d7a4 | ||
|
|
526d86d523 | ||
|
|
a583334034 | ||
|
|
623fb16762 | ||
|
|
57538065e9 | ||
|
|
0929663420 | ||
|
|
1573428847 | ||
|
|
6eb8f595c4 | ||
|
|
c4612885de | ||
|
|
80a6a1df32 | ||
|
|
5147b1d13f | ||
|
|
f2f1c19081 | ||
|
|
0bd62bdb59 | ||
|
|
332d679a4e | ||
|
|
9819f365c5 | ||
|
|
81024b8b04 | ||
|
|
2642b22bed | ||
|
|
3d98971bdf | ||
|
|
a6032b5d92 | ||
|
|
c53634a12b | ||
|
|
99971cbe97 | ||
|
|
c35702abb2 | ||
|
|
605c1dcc71 | ||
|
|
c2c1f5a9e4 | ||
|
|
e12e7375aa | ||
|
|
906410ba3b | ||
|
|
f6b97366ad | ||
|
|
6bfdf79469 | ||
|
|
b3cc9c6330 | ||
|
|
000931e9d1 | ||
|
|
bd18d200b8 | ||
|
|
21bf5c8eb0 | ||
|
|
75c35f024a | ||
|
|
97dd87b285 | ||
|
|
d149c81450 | ||
|
|
77b8085f24 | ||
|
|
bdaa295814 | ||
|
|
7be45f44c0 | ||
|
|
daafe3ee7a | ||
|
|
a267682937 | ||
|
|
908c18430b | ||
|
|
3715efcaf1 | ||
|
|
25c9642c23 | ||
|
|
f218cd8f5c | ||
|
|
d6c864e9cf | ||
|
|
2e89b9a724 | ||
|
|
0306121451 | ||
|
|
9d7b896cb9 | ||
|
|
8a86f718ee | ||
|
|
50f03b5872 | ||
|
|
04c4cc2624 | ||
|
|
94a5004073 | ||
|
|
26c310d313 | ||
|
|
69d8c0459a | ||
|
|
ab996bb2c7 | ||
|
|
824cec46b8 | ||
|
|
2fe56c879c | ||
|
|
fd0739b227 | ||
|
|
f455729f90 | ||
|
|
b15d7927fd | ||
|
|
d588167646 | ||
|
|
941928961d | ||
|
|
d01dbc1a63 | ||
|
|
a37f3a2f88 | ||
|
|
aab111ecae | ||
|
|
17bfa8c7e2 | ||
|
|
50e2a33842 | ||
|
|
3aa71c98d7 | ||
|
|
c369005328 | ||
|
|
b044f3238d | ||
|
|
4f9f4b9e68 | ||
|
|
34043afe65 | ||
|
|
e0301ab2b2 | ||
|
|
8867b7199e | ||
|
|
665da6127d | ||
|
|
444939ac3d | ||
|
|
01af0f9905 | ||
|
|
8193e983dd | ||
|
|
e6cc9187b4 | ||
|
|
dab222e71e | ||
|
|
8320e4fa04 | ||
|
|
fc9665b01c | ||
|
|
a88d428efe | ||
|
|
f709474cb9 | ||
|
|
7d3f6ed733 | ||
|
|
117eb3a5fe | ||
|
|
2122939fda | ||
|
|
87d02f9531 | ||
|
|
d7ea0c3e87 | ||
|
|
f31637f2a5 | ||
|
|
cf84fef532 | ||
|
|
e4e67cf101 | ||
|
|
2e77ebc106 | ||
|
|
96aff4448b | ||
|
|
8a35ef5994 | ||
|
|
7faac53571 | ||
|
|
0d43c9333b | ||
|
|
33dc1eac6d | ||
|
|
5d958fa905 | ||
|
|
d41029cc98 | ||
|
|
bdcc08443c | ||
|
|
eca91c1d9e | ||
|
|
6587b211e5 | ||
|
|
bc9f9e05ab | ||
|
|
c1504cf257 | ||
|
|
e43aa77c64 | ||
|
|
b3cbdad038 | ||
|
|
49e40e85aa | ||
|
|
30bb3be057 | ||
|
|
8f601140b4 | ||
|
|
6f776a4bd1 | ||
|
|
f1e0da0dcf | ||
|
|
92526d96dd | ||
|
|
31fedc1d3d | ||
|
|
2010c98d9e | ||
|
|
f5ae72bbd4 | ||
|
|
aaa505cee6 | ||
|
|
b5abfb6bf1 | ||
|
|
3c14710c42 | ||
|
|
003f41345c | ||
|
|
5bd43fd287 | ||
|
|
8c1cbf2570 | ||
|
|
aca2eb7e15 | ||
|
|
9c744d84cf | ||
|
|
72149f800f | ||
|
|
834d0a9805 | ||
|
|
1763fc9fbc | ||
|
|
10d196ef89 | ||
|
|
568c0b52f7 | ||
|
|
1aa78ab433 | ||
|
|
7e7bab74e9 | ||
|
|
10abd70357 | ||
|
|
38ede49aee | ||
|
|
7df5b1b882 | ||
|
|
c034d201ca | ||
|
|
11409df21c | ||
|
|
6024b19c3e | ||
|
|
4418f2050d | ||
|
|
c318e73481 | ||
|
|
784ce32e71 | ||
|
|
e256ca428c | ||
|
|
8dd3513c09 | ||
|
|
5bcd596a4a | ||
|
|
de0b8f1b07 | ||
|
|
ad63171e12 | ||
|
|
dc7496bfff | ||
|
|
3d9bb9d1d4 | ||
|
|
c1b3cc7abb | ||
|
|
a597fed0db | ||
|
|
59ecf4ed61 | ||
|
|
f7b08261f4 | ||
|
|
0dba824f2d | ||
|
|
ac2f3c809c | ||
|
|
e87b156928 | ||
|
|
b2b2e422a8 | ||
|
|
efb7fe45bd | ||
|
|
fcaa8ecabe | ||
|
|
050574602b | ||
|
|
db1fde0176 | ||
|
|
6d342c6940 | ||
|
|
18f2e6a625 | ||
|
|
f11a8c607a | ||
|
|
41ae9399a8 | ||
|
|
157f451ee5 | ||
|
|
466c7703e5 | ||
|
|
6008291057 | ||
|
|
40980d6c4d | ||
|
|
cae4562350 | ||
|
|
6825cecfb6 | ||
|
|
0066bccf29 | ||
|
|
74435e7ae1 | ||
|
|
a1bf20e98c | ||
|
|
6c8b511f05 | ||
|
|
b2bd020d24 | ||
|
|
f684148721 | ||
|
|
b0c1610922 | ||
|
|
98f89b16ba | ||
|
|
1303e660bb | ||
|
|
976cc7a0a0 | ||
|
|
6bd6fb609d | ||
|
|
7c143fcd0b | ||
|
|
0653eb8fac | ||
|
|
6586f87fe3 | ||
|
|
4d77eb4256 | ||
|
|
25986457ed | ||
|
|
65f9d583d7 | ||
|
|
5e7aee4d21 | ||
|
|
70160f9a34 | ||
|
|
fcbc096cee | ||
|
|
74d16085b3 | ||
|
|
96c516fe18 | ||
|
|
a1a84fee3a | ||
|
|
1c3d3d4681 | ||
|
|
0316420813 | ||
|
|
4a65731cc1 | ||
|
|
250a9916ed | ||
|
|
b32e479a5b | ||
|
|
a913ef382f | ||
|
|
ece7869f0c | ||
|
|
11d20dd6d5 | ||
|
|
e4d6039a8b | ||
|
|
53ff921458 | ||
|
|
18123b5cbd | ||
|
|
c01820a867 | ||
|
|
4df532924f | ||
|
|
80c0275647 | ||
|
|
1edef1c7d6 | ||
|
|
93fe009737 | ||
|
|
28fbcad77b | ||
|
|
12a225d078 | ||
|
|
f9977df835 | ||
|
|
e067566a9e | ||
|
|
23e66a2168 | ||
|
|
b9d757df0f | ||
|
|
4eb967aa20 | ||
|
|
efd80d629b | ||
|
|
96ecb04052 | ||
|
|
22f1d07cf8 | ||
|
|
5e6871a341 | ||
|
|
e3767816d7 | ||
|
|
643e13296b | ||
|
|
442a103d24 | ||
|
|
16e8afc976 | ||
|
|
162ad239b8 | ||
|
|
824e578dd1 | ||
|
|
813f0945e4 | ||
|
|
7ac0c3780d | ||
|
|
90d7795ea6 | ||
|
|
a9f1bd094d | ||
|
|
981c63b8a2 | ||
|
|
dc8551cf4f | ||
|
|
fe9a5c870c | ||
|
|
394af40bbd | ||
|
|
75b30cc810 | ||
|
|
0ed96b3896 | ||
|
|
c7d98bfb26 | ||
|
|
be2ddde905 | ||
|
|
40431f8e76 | ||
|
|
7f82a62490 | ||
|
|
36d1b9a728 | ||
|
|
6b0342c90f | ||
|
|
df744d20d5 | ||
|
|
87b1ca040d | ||
|
|
d19bc7250d | ||
|
|
25a9eef9db | ||
|
|
3c7c2affc2 | ||
|
|
a04e425f08 | ||
|
|
dd8f4af859 | ||
|
|
25e1bc7e94 | ||
|
|
008346a6fb | ||
|
|
12fa51aebc | ||
|
|
68cff445e5 | ||
|
|
a2a8c425a9 | ||
|
|
b07f5baf79 | ||
|
|
91898f9128 | ||
|
|
2f5b52e7cb | ||
|
|
3b236ab4db | ||
|
|
667f34d884 | ||
|
|
cb6bb4aaf3 | ||
|
|
843a8a6862 | ||
|
|
e9b4b1ca62 | ||
|
|
31937f11ac | ||
|
|
2c35e744d9 | ||
|
|
4ec9edc394 | ||
|
|
391683f351 | ||
|
|
859ea64768 | ||
|
|
fedd061f2c | ||
|
|
cbb1a1437c | ||
|
|
255c3b255e | ||
|
|
c8bdd07403 | ||
|
|
64c1d4cc0b | ||
|
|
6fb3d8c881 | ||
|
|
b8072ea4a5 | ||
|
|
32e801d858 | ||
|
|
bde33ce121 | ||
|
|
ef745a50f8 | ||
|
|
4f48d55436 | ||
|
|
532920f1be | ||
|
|
a44f6081e1 | ||
|
|
169e0b5a0b | ||
|
|
935f2eca54 | ||
|
|
3da998e002 | ||
|
|
8a83570bcf | ||
|
|
851d42c547 | ||
|
|
f3148fab05 | ||
|
|
d1a4224d37 | ||
|
|
471f387760 | ||
|
|
cf65253d11 | ||
|
|
a2cc463a1d | ||
|
|
e52d328ca7 | ||
|
|
8845f96c54 | ||
|
|
c77a5378a8 | ||
|
|
7306e7eea4 | ||
|
|
20b98f5d0a | ||
|
|
96fa30cd94 | ||
|
|
17cef20f0a | ||
|
|
3b9eface0d | ||
|
|
3cecc71e7a | ||
|
|
bab9d910cf | ||
|
|
70ef700e48 | ||
|
|
47f220c2dc | ||
|
|
31f6e0f51f | ||
|
|
63e85fe70a | ||
|
|
866a723450 | ||
|
|
5aaa073000 | ||
|
|
3e18de01c5 | ||
|
|
edf700943b | ||
|
|
65c07fc394 | ||
|
|
a642e22343 | ||
|
|
51be1e664e | ||
|
|
a4bdb953e3 | ||
|
|
b62b6802e1 | ||
|
|
17829900a8 | ||
|
|
6c2bf81899 | ||
|
|
2f6dcd9473 | ||
|
|
713bf07827 | ||
|
|
bcacb28703 | ||
|
|
c91b9d3655 | ||
|
|
0e4f9c8f09 | ||
|
|
9a47218256 | ||
|
|
0ecb7d9a5f | ||
|
|
b5e1c3035c | ||
|
|
3e2cb06c3b | ||
|
|
1cd2b86e37 | ||
|
|
b204aa02c8 | ||
|
|
e8b0a87fc9 | ||
|
|
4d8313b050 | ||
|
|
02a625aa66 | ||
|
|
c7b1920ba5 | ||
|
|
9b18bf34a9 | ||
|
|
36361882c2 | ||
|
|
320fece486 | ||
|
|
3060c0f37d | ||
|
|
2155be5a78 | ||
|
|
1555d3f1f1 | ||
|
|
c2cc4253f6 | ||
|
|
0a4b91ac1a | ||
|
|
df26e58917 | ||
|
|
cf0b85c2a1 | ||
|
|
2dbe11183e | ||
|
|
b416dbd8a7 | ||
|
|
04dee84a05 | ||
|
|
9573f722b5 | ||
|
|
ac8b2d7cd4 | ||
|
|
b8ac4a341c | ||
|
|
924ff21d94 | ||
|
|
311510de91 | ||
|
|
8ac0f7bb79 | ||
|
|
07ef929e2c | ||
|
|
3d25b74f9f | ||
|
|
76c880defe | ||
|
|
34f70068ee | ||
|
|
72f946ab9f | ||
|
|
a588030150 | ||
|
|
727a497d2f | ||
|
|
8a3e97eaf9 | ||
|
|
bc2eae423a | ||
|
|
5b37c52650 | ||
|
|
06a5c678fa | ||
|
|
e660eceb15 | ||
|
|
3ce60afa07 | ||
|
|
86e8994f9d | ||
|
|
4e8b227d1f | ||
|
|
603ef22d60 | ||
|
|
69e0914f36 | ||
|
|
6cc8156b98 | ||
|
|
d62d3d2187 | ||
|
|
8bcdc1006d | ||
|
|
34b71c05d1 | ||
|
|
81fcb6d24e | ||
|
|
c16b730dac | ||
|
|
1e069e7ec5 | ||
|
|
15f865c2cb | ||
|
|
41706ec840 | ||
|
|
e9c4edc4c4 | ||
|
|
a944a70878 | ||
|
|
ee8e450442 | ||
|
|
f74289e210 | ||
|
|
a2dda9de89 | ||
|
|
9c6d5d81e4 | ||
|
|
bd7d060fbd | ||
|
|
2b16c0d505 | ||
|
|
de4ed1bf66 | ||
|
|
3403bbf3c3 | ||
|
|
a337306e61 | ||
|
|
bb75fff6b3 | ||
|
|
c92b80bdf2 | ||
|
|
31a2ebb668 | ||
|
|
f45248058f | ||
|
|
91131a4213 | ||
|
|
29dad159f7 | ||
|
|
a871744d8b | ||
|
|
314a35980d | ||
|
|
13152519f2 | ||
|
|
bc47cd30a7 | ||
|
|
5ff58deb6a | ||
|
|
7b36e25164 | ||
|
|
a16adc037a | ||
|
|
dbf4d655ca | ||
|
|
01318541c4 | ||
|
|
586b82a559 | ||
|
|
cb2579cabf | ||
|
|
14ba75e5f0 | ||
|
|
06a369682d | ||
|
|
a35e2dd080 | ||
|
|
eafe66a8fd | ||
|
|
886f7dbf12 | ||
|
|
3e95fb9b1a | ||
|
|
9706e59030 | ||
|
|
22b8adcd04 | ||
|
|
582792433c | ||
|
|
71fc852c37 | ||
|
|
1a5baaa5ec | ||
|
|
9741fa1860 | ||
|
|
9e7aa6a887 | ||
|
|
98f12bfb7e | ||
|
|
f465383588 | ||
|
|
01594f96a2 | ||
|
|
ec99d02ecd | ||
|
|
765895c015 | ||
|
|
f3cc7c5823 | ||
|
|
ec391b94c9 | ||
|
|
cf10a8663f | ||
|
|
93ef70fcd9 | ||
|
|
512d9b9479 | ||
|
|
294e6b7afa | ||
|
|
c1b76f2546 | ||
|
|
5fb008f375 | ||
|
|
973b18f5cf | ||
|
|
4c3731c501 | ||
|
|
69f3fc301d | ||
|
|
c0a85d12dc | ||
|
|
61da95a7fd | ||
|
|
20af210e72 | ||
|
|
ba3e678463 | ||
|
|
33639f7719 | ||
|
|
61767f12d2 | ||
|
|
dbb15a2a55 | ||
|
|
43b956508f | ||
|
|
b9c7753494 | ||
|
|
b5859bd764 | ||
|
|
b55ed3fe64 | ||
|
|
7f26642f48 | ||
|
|
00303e2abc | ||
|
|
fffe9bc623 | ||
|
|
34f5547f65 | ||
|
|
3264919a19 | ||
|
|
92b245ca9f | ||
|
|
6c85a96d09 | ||
|
|
b9a6504452 | ||
|
|
fb71e7476d | ||
|
|
ea5d1b2bc6 | ||
|
|
e10e7b06e0 | ||
|
|
5ca9cea438 | ||
|
|
b165eefc3d | ||
|
|
c8a1bb3ede | ||
|
|
f92ecb942d | ||
|
|
8c7aceb686 | ||
|
|
24ba0c950d | ||
|
|
ce9bdff4eb | ||
|
|
381fb3d258 | ||
|
|
d59fa1b4ad | ||
|
|
c0d13a5eae | ||
|
|
d83be1bc19 | ||
|
|
17cd00084a | ||
|
|
85322e2b16 | ||
|
|
0285d644df | ||
|
|
961be84ebb | ||
|
|
18caebd78a | ||
|
|
40ffbf1a51 | ||
|
|
7ede683049 | ||
|
|
7a156532c7 | ||
|
|
7f746fd3ac | ||
|
|
62bb7c9cc2 | ||
|
|
4612874f3f | ||
|
|
168276468c | ||
|
|
1b271b45fd | ||
|
|
a4dcb0fc37 | ||
|
|
f2d5938a82 | ||
|
|
fdd9d0cb78 | ||
|
|
cceba559c1 | ||
|
|
fdc71d709f | ||
|
|
b4d09330bb | ||
|
|
3181aeb3ed | ||
|
|
31ac8d05f9 | ||
|
|
cb6ab22841 | ||
|
|
8b52f7132b | ||
|
|
f4bb391064 | ||
|
|
ae606d5520 | ||
|
|
1d207195e5 | ||
|
|
0de9a46c98 | ||
|
|
23e39d932f | ||
|
|
5632646b1f | ||
|
|
23b3bbe909 | ||
|
|
3149bb43af | ||
|
|
545a2b0b07 | ||
|
|
452f0bf6b4 | ||
|
|
97a7e0efeb | ||
|
|
bbc3a45386 | ||
|
|
6707b41b0e | ||
|
|
a0d175579f | ||
|
|
466a0b2487 | ||
|
|
63da8a77e3 | ||
|
|
1d503e98c8 | ||
|
|
bee019d5c5 | ||
|
|
37b4d6da4f | ||
|
|
ee3e69b42e | ||
|
|
367c49bf95 | ||
|
|
12c65b9791 | ||
|
|
aa3e79c7c1 | ||
|
|
0be0683f88 | ||
|
|
99a385ea85 | ||
|
|
efa6445c4d | ||
|
|
7dc3b4536d | ||
|
|
4f7194f174 | ||
|
|
f6472fcfb5 | ||
|
|
f1d49fc108 | ||
|
|
faed48dfd1 | ||
|
|
2b789a6858 | ||
|
|
e17b19d53b | ||
|
|
e453553465 | ||
|
|
3251a03fcc | ||
|
|
9ec1b33be9 | ||
|
|
602bd9420e | ||
|
|
a6a3af235d | ||
|
|
9f9984d5b5 | ||
|
|
6c193fc844 | ||
|
|
5f60bdcc31 | ||
|
|
13715df678 | ||
|
|
9bef5b84b0 | ||
|
|
bd7684a638 | ||
|
|
703e2260fe | ||
|
|
51beab54be | ||
|
|
44a924278c | ||
|
|
86ac4bb08c | ||
|
|
3e9116c21f | ||
|
|
b8c0427dc2 | ||
|
|
f0664d287a | ||
|
|
37d2a40389 | ||
|
|
4068a70c7d | ||
|
|
ab1faa6fc0 | ||
|
|
f2ec6ba3cd | ||
|
|
ab36cf800d | ||
|
|
38f62863ac | ||
|
|
6651cdff93 | ||
|
|
06b6d11d1f | ||
|
|
49066dff94 | ||
|
|
34cd58f448 | ||
|
|
816598c564 | ||
|
|
88738244d7 | ||
|
|
588fbb605f | ||
|
|
58aceedfaa | ||
|
|
1683903f5b | ||
|
|
858c03efa9 | ||
|
|
132e840d87 | ||
|
|
106a010e2e | ||
|
|
f2ca679d1b | ||
|
|
d71f80ddbf | ||
|
|
2a049ef721 | ||
|
|
1cf6832fc9 | ||
|
|
12972f8c0e | ||
|
|
523de56058 | ||
|
|
cf4a941c9c | ||
|
|
bc9fbe601c | ||
|
|
f3f5f7db64 | ||
|
|
ba76f7a208 | ||
|
|
6f5bcaf854 | ||
|
|
6776d9e2a4 | ||
|
|
a07d3e65b7 | ||
|
|
020a9ff691 | ||
|
|
bdbb649dba | ||
|
|
397bd6c968 | ||
|
|
9756ef08c5 | ||
|
|
50f06a83e9 | ||
|
|
b285319f6b | ||
|
|
f381428425 | ||
|
|
379c9f955e | ||
|
|
cb37f64d8b | ||
|
|
aa0ddad108 | ||
|
|
318fac8c8f | ||
|
|
4acd9f7c5f | ||
|
|
e2992f4be0 | ||
|
|
037b32498a | ||
|
|
e12a869ae2 | ||
|
|
da116055ff | ||
|
|
f757cafcd8 | ||
|
|
8dac164ec2 | ||
|
|
2dde269b71 | ||
|
|
8357d930c1 | ||
|
|
c74eca0683 | ||
|
|
e0656f3e4e | ||
|
|
072c3c0f38 | ||
|
|
a007979ede | ||
|
|
f4a0004964 | ||
|
|
8688ce31e2 | ||
|
|
b9763bc458 | ||
|
|
f0d2a12e47 | ||
|
|
67fc71aac9 | ||
|
|
3ac41ef799 | ||
|
|
4608ebd5ac | ||
|
|
71bc035396 | ||
|
|
76bc9877ef | ||
|
|
1fddb15831 | ||
|
|
7d71e8e7e3 | ||
|
|
f3d8d365a3 | ||
|
|
af56d7ed58 | ||
|
|
6817eb686e | ||
|
|
ff5d7728a2 | ||
|
|
6c5e9971f9 | ||
|
|
a8c41fddf4 | ||
|
|
50a0e911c4 | ||
|
|
07760a32d4 | ||
|
|
c8d9142bab | ||
|
|
1c7413c4b6 | ||
|
|
d9b6494f20 | ||
|
|
52739b7c0f | ||
|
|
57dfc20089 | ||
|
|
30fed4aed0 | ||
|
|
c418a03d9f | ||
|
|
ee34ccaf3a | ||
|
|
a63ebc3be0 | ||
|
|
cea5528074 | ||
|
|
a3aacb6d9e | ||
|
|
349eb9f1b9 | ||
|
|
641aec7da0 | ||
|
|
8897d6c382 | ||
|
|
04cb0976d6 | ||
|
|
9d9609aec7 | ||
|
|
80ea72377f | ||
|
|
f2e3d83883 | ||
|
|
a3535d86d0 | ||
|
|
94e7f841ac | ||
|
|
1e6299b643 | ||
|
|
a77de91298 | ||
|
|
48a2934cdb | ||
|
|
04b56975f4 | ||
|
|
59bb3c8679 | ||
|
|
d144b8445a | ||
|
|
fe82b3562a | ||
|
|
26da8f6a96 | ||
|
|
70c6278c5f | ||
|
|
5635d1b7fe | ||
|
|
75b042aa57 | ||
|
|
7c51262d01 | ||
|
|
0efeb07e1c | ||
|
|
2f63d1d250 | ||
|
|
11fffbf03e | ||
|
|
46181492f4 | ||
|
|
78e03ca3a7 | ||
|
|
462e9c3405 | ||
|
|
6b5fae2227 | ||
|
|
aa6a238206 | ||
|
|
529a275043 | ||
|
|
3dbaf8d3d9 | ||
|
|
a9839ca08e | ||
|
|
60cdbf636d | ||
|
|
dc6a7a0a52 | ||
|
|
8cd208d339 | ||
|
|
3d3d0a9e4c | ||
|
|
a03e3203a9 | ||
|
|
d4cdbd2cf7 | ||
|
|
c5b40d1dd6 | ||
|
|
18b945136a | ||
|
|
f44f74874e | ||
|
|
34df795c7e | ||
|
|
6e8aabbb50 | ||
|
|
3a95512d8a | ||
|
|
48e5001c8b | ||
|
|
c70d2a536b | ||
|
|
02db0877e7 | ||
|
|
16cea13a34 | ||
|
|
2803bd43bc | ||
|
|
bad5ce5c73 | ||
|
|
5d0a296c5f | ||
|
|
145b66a47e | ||
|
|
c8ebf0b9a2 | ||
|
|
e609483188 | ||
|
|
3160183947 | ||
|
|
8af65f26be | ||
|
|
d9e181f9ac | ||
|
|
a767d8fc02 | ||
|
|
9e9b2a5974 | ||
|
|
3f34968ec0 | ||
|
|
7edb86cd48 | ||
|
|
0ea6634944 | ||
|
|
ba499f7ac9 | ||
|
|
50fabbc93c | ||
|
|
443c98bdfd | ||
|
|
77e8d57a69 | ||
|
|
21a5d04561 | ||
|
|
4a8408df8c | ||
|
|
f378576367 | ||
|
|
0506764ccd | ||
|
|
99b67906d5 | ||
|
|
15033872c4 | ||
|
|
493cc3d4bb | ||
|
|
04b49c0e53 | ||
|
|
0fed6b9dd6 | ||
|
|
2fb81d2e35 | ||
|
|
e116754ef3 | ||
|
|
91cfe3254f | ||
|
|
49e4fa4509 | ||
|
|
7f9c3267ca | ||
|
|
518aa20009 | ||
|
|
a9912d2b3d | ||
|
|
d5ab5707e1 | ||
|
|
1de29f0bd7 | ||
|
|
2dfc4fb45a | ||
|
|
0db9c51205 | ||
|
|
2845571662 | ||
|
|
1df0a9a7f9 | ||
|
|
17181b6682 | ||
|
|
f481ad915a | ||
|
|
af67097989 | ||
|
|
27a0bcc7a6 | ||
|
|
6c902db1ff | ||
|
|
20c1ebdeb3 | ||
|
|
587841308a | ||
|
|
3215a0b101 | ||
|
|
3d66cd15ad | ||
|
|
d750a4a2b3 | ||
|
|
b0f83a4458 | ||
|
|
d137e22574 | ||
|
|
a51483f2de | ||
|
|
fc1bed7295 | ||
|
|
e26321a369 | ||
|
|
ea6491f16c | ||
|
|
1c8233f848 | ||
|
|
a724afb7ad | ||
|
|
852bad51ea | ||
|
|
e539138eec | ||
|
|
bbffb7b5a8 | ||
|
|
ef4b703dfb | ||
|
|
504468f873 | ||
|
|
ad8fd76a99 | ||
|
|
0869c6b59f | ||
|
|
5ae035ee2c | ||
|
|
6e03196310 | ||
|
|
03fd66de41 | ||
|
|
8187fbda5b | ||
|
|
88ffffa4ca | ||
|
|
a54416ab5b | ||
|
|
154211b1c5 | ||
|
|
97fe72f279 | ||
|
|
1517877ab8 | ||
|
|
1ea9f39c54 | ||
|
|
b9a6275451 | ||
|
|
fec45247ea | ||
|
|
17af2aa52b | ||
|
|
6fad359277 | ||
|
|
00ef33df6e | ||
|
|
2071b1b4ac | ||
|
|
c81b59af14 | ||
|
|
59fe4bbbe0 | ||
|
|
ee2e197f58 | ||
|
|
4a03ef17e6 | ||
|
|
f213c07dbd | ||
|
|
f32a1ef5e2 | ||
|
|
f2e470c5ae | ||
|
|
de6299d14b | ||
|
|
900933bc0e | ||
|
|
e8a5df1dbf | ||
|
|
7ac4240ae1 | ||
|
|
fedcaa1d22 | ||
|
|
c5d3f123ef | ||
|
|
d45deb6a17 | ||
|
|
79dc878e26 | ||
|
|
8cd59c25b3 | ||
|
|
7d67025fe0 | ||
|
|
b50dc5e47c | ||
|
|
f74d123b00 | ||
|
|
6dafff0962 | ||
|
|
9d68c6c207 | ||
|
|
d015f1fad5 | ||
|
|
b57b9533c6 | ||
|
|
5df4aef783 | ||
|
|
a6f36feced | ||
|
|
3f90d169fe | ||
|
|
daa0169543 | ||
|
|
f56afef35d | ||
|
|
7a92e9546c | ||
|
|
6db96de985 | ||
|
|
c6d9960f65 | ||
|
|
84299a46e7 | ||
|
|
f67434bb94 | ||
|
|
687be18c06 | ||
|
|
ab348fa197 | ||
|
|
e17a983e85 | ||
|
|
cb76e3948d | ||
|
|
799e7ddba3 | ||
|
|
8de1154cf3 | ||
|
|
50c6d2ab72 | ||
|
|
ae024675a2 | ||
|
|
b4677e45b0 | ||
|
|
584973075d | ||
|
|
ff51cd70ef | ||
|
|
a23bdf8eeb | ||
|
|
dc70d35140 | ||
|
|
89aaf97bee | ||
|
|
307d71dce4 | ||
|
|
92567ff995 | ||
|
|
97d71f71cc | ||
|
|
ea8d512137 | ||
|
|
dfc8d8bfc4 | ||
|
|
3cd9ee9a6b | ||
|
|
d8566153e2 | ||
|
|
de4dcd8827 | ||
|
|
0178ff3780 | ||
|
|
4a93039087 | ||
|
|
4d2c933900 | ||
|
|
58f0041dc7 | ||
|
|
2ad74c50db | ||
|
|
e8f807aaa1 | ||
|
|
7272a0db78 | ||
|
|
c935e60a91 | ||
|
|
0840feaeda | ||
|
|
e023cc6b0f | ||
|
|
78b239f7d8 | ||
|
|
acdea16fce | ||
|
|
21af7e1499 | ||
|
|
64875cfa7a | ||
|
|
f8e57eedf9 | ||
|
|
daeb766f4a | ||
|
|
0805a1dd62 | ||
|
|
3484b3e9cd | ||
|
|
e61a7bf8d3 | ||
|
|
3a6dfcc224 | ||
|
|
97c2014ae6 | ||
|
|
c2b792d471 | ||
|
|
859853b021 | ||
|
|
4055d3d351 | ||
|
|
24e5568b3c | ||
|
|
60712a97f8 | ||
|
|
e38398c532 | ||
|
|
ff6c4e0712 | ||
|
|
f1cbb6b076 | ||
|
|
b001f7d4de | ||
|
|
cd62a4294b | ||
|
|
527b7373bb | ||
|
|
81054bdacf | ||
|
|
3da0ef2966 | ||
|
|
9c6a9b8ca1 | ||
|
|
98dcd01267 | ||
|
|
88fda79468 | ||
|
|
9878cc9cae | ||
|
|
39ad0ad1e4 | ||
|
|
cbd6bdc4f4 | ||
|
|
11bc47120d | ||
|
|
4f2f9cadf5 | ||
|
|
707ce19908 | ||
|
|
27a456753e | ||
|
|
b179237526 | ||
|
|
d6a8c83ab8 | ||
|
|
1bddf8d311 | ||
|
|
253420e4b4 | ||
|
|
4d37453971 | ||
|
|
e673f160b6 | ||
|
|
255ea644d6 | ||
|
|
9c4cae3635 | ||
|
|
bf66348fdc | ||
|
|
cf06900a88 | ||
|
|
f2022dc6c7 | ||
|
|
9b44d9a836 | ||
|
|
6041554ae1 | ||
|
|
3e32565ff1 | ||
|
|
32b073f951 | ||
|
|
a458576f80 | ||
|
|
f8fdb7a5a9 | ||
|
|
023c00246a | ||
|
|
746f172821 | ||
|
|
505b977956 | ||
|
|
806b859571 | ||
|
|
112d007f84 | ||
|
|
ae8fba0876 | ||
|
|
b382a84d0a | ||
|
|
e1ab785589 | ||
|
|
f5eb5a914b | ||
|
|
7c44dac650 | ||
|
|
110f481e6d | ||
|
|
9e017f6026 | ||
|
|
ae281d64cd | ||
|
|
90a24105a0 | ||
|
|
bb2d467ded | ||
|
|
a2723467a6 | ||
|
|
ff829955b4 | ||
|
|
1e116890a5 | ||
|
|
6c939f3387 | ||
|
|
36653416fe | ||
|
|
24406783c4 | ||
|
|
024b9d9cc4 | ||
|
|
9e52ea923f | ||
|
|
8e80132972 | ||
|
|
37996a76dd | ||
|
|
045f612c4d | ||
|
|
6c77d55640 | ||
|
|
e5dd834e1e | ||
|
|
104e759a2d | ||
|
|
dd05b9966e | ||
|
|
4ad79864ad | ||
|
|
17b23ed962 | ||
|
|
e205134dff | ||
|
|
e99f543f20 | ||
|
|
fa3963aa1d | ||
|
|
ae6aab6d21 | ||
|
|
4d1bb9c105 | ||
|
|
35b4942253 | ||
|
|
c8287f21a5 | ||
|
|
3ddf668491 | ||
|
|
05b8a68f8b | ||
|
|
26d31dd632 | ||
|
|
e4404f975f | ||
|
|
b5f6b684ce | ||
|
|
9324e82329 | ||
|
|
0ca09ff18a | ||
|
|
84b67367a0 | ||
|
|
4c15083264 | ||
|
|
c51ed59baa | ||
|
|
fc2cfb4f34 | ||
|
|
844eba752d | ||
|
|
3d44cc1d64 | ||
|
|
11cdacf01c | ||
|
|
d7bb16b43f | ||
|
|
0b725eabb1 | ||
|
|
9b0674f688 | ||
|
|
77835d3651 | ||
|
|
7b114d42b9 | ||
|
|
32c0d313b7 | ||
|
|
99f4786947 | ||
|
|
f0cbcbe706 | ||
|
|
c09bb4f4ae | ||
|
|
bc9b1c0a94 | ||
|
|
b515d59933 | ||
|
|
2badd03aa4 | ||
|
|
c102b3a251 | ||
|
|
7c9c69f18b | ||
|
|
8ee6ca8648 | ||
|
|
978a089480 | ||
|
|
c40066ceed | ||
|
|
7706cdf90b | ||
|
|
1b4339f1de | ||
|
|
13f86a9de1 | ||
|
|
172c3d86ed | ||
|
|
cb3050ec1e | ||
|
|
765a4dd00c | ||
|
|
5def274b45 | ||
|
|
cfb34efa37 | ||
|
|
9f6282a589 | ||
|
|
c384336941 | ||
|
|
ac27800818 | ||
|
|
0ba6fc3d7f | ||
|
|
d1e1f42879 | ||
|
|
c3be01383b | ||
|
|
7621dd45da | ||
|
|
d782c7d399 | ||
|
|
2cacddefbb | ||
|
|
492f13cf8c | ||
|
|
92fc1b07a1 | ||
|
|
4bc0c8b892 | ||
|
|
e4333c4b22 | ||
|
|
1ec9183ddc | ||
|
|
d6b9a8a220 | ||
|
|
2624bf542e | ||
|
|
1fa8ba769d | ||
|
|
f5738b897e | ||
|
|
6e245b465d | ||
|
|
40049f4dcd | ||
|
|
462ccd7cfb | ||
|
|
93b06ef2c9 | ||
|
|
e3e2478fc5 | ||
|
|
62d4ece07e | ||
|
|
93cdb1aa97 | ||
|
|
818190b3fe | ||
|
|
0ddf4d49a3 | ||
|
|
1ec5873be8 | ||
|
|
7a004166bc | ||
|
|
253fa5bfdd | ||
|
|
ab3852803f | ||
|
|
b3be055cff | ||
|
|
9d61d775de | ||
|
|
420a3cf85f | ||
|
|
1caebb47a0 | ||
|
|
a5da8e760e | ||
|
|
0ca2cfe99c | ||
|
|
7b8ee512a2 | ||
|
|
e147991431 | ||
|
|
467e172e30 | ||
|
|
ded4671b58 | ||
|
|
867f0d38ef | ||
|
|
41a5ab65b2 | ||
|
|
2c3cd1c387 | ||
|
|
7807b53311 | ||
|
|
87765d268e | ||
|
|
42b109f0cd | ||
|
|
f89e041342 | ||
|
|
18ff4a5305 | ||
|
|
bc0b310bed | ||
|
|
956eef5478 | ||
|
|
949219cb2e | ||
|
|
a7232ca752 | ||
|
|
00a405a008 | ||
|
|
c397fb23d9 | ||
|
|
3505408029 | ||
|
|
d44da9d8ad | ||
|
|
706330b213 | ||
|
|
48ecb15a9d | ||
|
|
2aa24fd479 | ||
|
|
9638824143 | ||
|
|
9e849eaeb3 | ||
|
|
e72bb4bee2 | ||
|
|
50ead03720 | ||
|
|
f2a0aaddf3 | ||
|
|
9ccab61460 | ||
|
|
74a01b3f12 | ||
|
|
2aebc67d3f | ||
|
|
a60db6ed41 | ||
|
|
146d750088 | ||
|
|
e1d1f468d5 | ||
|
|
94532a0baa | ||
|
|
787d972c07 | ||
|
|
9e9e048363 | ||
|
|
56d62c5ff0 | ||
|
|
164bedb75f | ||
|
|
d2a474cff1 | ||
|
|
ea9f77930b | ||
|
|
a9399bb9bb | ||
|
|
ad39ae737a | ||
|
|
2869fd4dd8 | ||
|
|
ea209808d1 | ||
|
|
6af8ae3618 | ||
|
|
f4e4f9ab83 | ||
|
|
309bce5616 | ||
|
|
70166b6bc1 | ||
|
|
0a8cd45254 | ||
|
|
6024b955e2 | ||
|
|
038bd40fed | ||
|
|
4eb01d9dfb | ||
|
|
9a3985e28d | ||
|
|
cb5ef22943 | ||
|
|
0b682a04d8 | ||
|
|
0d2207ae6e | ||
|
|
e69cc742c5 | ||
|
|
69f632d345 | ||
|
|
befd81c405 | ||
|
|
d0c2572673 | ||
|
|
bf7aead61e | ||
|
|
e56b600d50 | ||
|
|
07ebec72f0 | ||
|
|
e8b54ddd63 | ||
|
|
57abe360e8 | ||
|
|
6045fb05e7 | ||
|
|
6f977f748d | ||
|
|
8f0b24b1ca | ||
|
|
82f0a901f6 | ||
|
|
b0c5a56f69 | ||
|
|
dfc9b09aa5 | ||
|
|
a396cf2ab5 | ||
|
|
e35d697cab | ||
|
|
f4387d5a12 | ||
|
|
898bc25fbd | ||
|
|
999f388881 | ||
|
|
d5db28228f | ||
|
|
eb2aece5b5 | ||
|
|
6783d70a82 | ||
|
|
845bc7c9dd | ||
|
|
bd473dbf84 | ||
|
|
58278a58d8 | ||
|
|
649f11883e | ||
|
|
b62498596a | ||
|
|
f78de35730 | ||
|
|
68b4ec09ff | ||
|
|
8a427d7e72 | ||
|
|
59192fd5c4 | ||
|
|
0b9a45da38 | ||
|
|
a3d1485ace | ||
|
|
586cfcea97 | ||
|
|
4c14bbc123 | ||
|
|
b69eb8be08 | ||
|
|
3a243125a9 | ||
|
|
7a0360a84b | ||
|
|
e1e3fed0d9 | ||
|
|
0e674c0765 | ||
|
|
fc6a103956 | ||
|
|
d6c8181164 | ||
|
|
af42cff7d7 | ||
|
|
b7fdbbc7f1 | ||
|
|
38d220017f | ||
|
|
52036bd7b2 | ||
|
|
8ea9efd159 | ||
|
|
52a1391d38 | ||
|
|
c3ddda6981 | ||
|
|
e7b69e7cfe | ||
|
|
196d964d0d | ||
|
|
5ae2e23158 | ||
|
|
b868f3f9a4 | ||
|
|
18e31344ae | ||
|
|
2a0d462842 | ||
|
|
07f722113b | ||
|
|
e8a7907e01 | ||
|
|
0765fc1f71 | ||
|
|
d95ea5144e | ||
|
|
769c49b480 | ||
|
|
b94041a9df | ||
|
|
34804e8d47 | ||
|
|
57c0b04b54 | ||
|
|
ac4b4ae553 | ||
|
|
9e3540a7b4 | ||
|
|
2a2983d59c | ||
|
|
bf50c6ac1f | ||
|
|
dbfe2dc467 | ||
|
|
086916c45e | ||
|
|
6ebddd88ab | ||
|
|
6d6796459b | ||
|
|
99632c43f8 | ||
|
|
37e27ee719 | ||
|
|
a3cf1aea8c | ||
|
|
458595ef81 | ||
|
|
54fa3bf613 | ||
|
|
077800e12a | ||
|
|
d29af11295 | ||
|
|
cf2c53b190 | ||
|
|
3e44c3fb58 | ||
|
|
7a8db78c51 | ||
|
|
e75b819ea0 | ||
|
|
36b1aa2b0e | ||
|
|
7004b6bd63 | ||
|
|
31f1a90789 | ||
|
|
7ca8b99502 | ||
|
|
92b49d01a9 | ||
|
|
5e317304f3 | ||
|
|
032c63cf3e | ||
|
|
5b2a2678ad | ||
|
|
ef58c6537b | ||
|
|
5b6480a097 | ||
|
|
9b27f11bde | ||
|
|
1fb8b9ae44 | ||
|
|
f35549818c | ||
|
|
ebdcd42ec7 | ||
|
|
a5acc38ae6 | ||
|
|
5e1231ee36 | ||
|
|
4561b679d6 | ||
|
|
93de20242b | ||
|
|
9c0312befb | ||
|
|
1fb330d490 | ||
|
|
0b8662aa84 | ||
|
|
977bc5f355 | ||
|
|
a7033f67df | ||
|
|
182d8aa5dd | ||
|
|
0b2bf6d58f | ||
|
|
6f5035a827 | ||
|
|
68ac3e58f6 | ||
|
|
138b240b04 | ||
|
|
56fefd1ce3 | ||
|
|
e9afb7b48a | ||
|
|
00da0c544a | ||
|
|
dec32273fd | ||
|
|
41782bb1cb | ||
|
|
0bdd1449f3 | ||
|
|
6fd2263f14 | ||
|
|
4de68e74b6 | ||
|
|
6c786cfe4a | ||
|
|
ce33a3618a | ||
|
|
b2c8ff4ae4 | ||
|
|
b73af4d025 | ||
|
|
24b446157d | ||
|
|
85ebf731c8 | ||
|
|
6bde7ab01b | ||
|
|
6a632a3113 | ||
|
|
d12f9b1433 | ||
|
|
e69c5e7554 | ||
|
|
d80e213a6a | ||
|
|
4efd715318 | ||
|
|
c152b1ac59 | ||
|
|
634a03169d | ||
|
|
dac3aad973 | ||
|
|
dd5000f682 | ||
|
|
13e0f80c66 | ||
|
|
612c6f9a7f | ||
|
|
6bfe0b0bad | ||
|
|
7bfd0857f4 | ||
|
|
f7b4ccb352 | ||
|
|
3f73fdd642 | ||
|
|
3f5fae6445 | ||
|
|
13193e9478 | ||
|
|
498047439d | ||
|
|
d992bb7fc6 | ||
|
|
95c6d61a67 | ||
|
|
ad258789d2 | ||
|
|
9f3cbf8a7a | ||
|
|
29f9a21fc6 | ||
|
|
c424d9483e | ||
|
|
9487443617 | ||
|
|
c04fcb87e8 | ||
|
|
20ed7fb63d | ||
|
|
3818790371 | ||
|
|
a2c2bedede | ||
|
|
e7a5f1823a | ||
|
|
8009c3e7d0 | ||
|
|
76accc9930 | ||
|
|
39d58d0f1a | ||
|
|
0af82950bf | ||
|
|
a22662fcd4 | ||
|
|
a53b09dec6 | ||
|
|
18bed70307 | ||
|
|
e1deedb6f6 | ||
|
|
8d500020a4 | ||
|
|
c1a77ef4a5 | ||
|
|
ae54e14453 | ||
|
|
d9dcc96fe9 | ||
|
|
7045ea5b6d | ||
|
|
c2210c09bd | ||
|
|
69e7e0cbdd | ||
|
|
adec5ebf5f | ||
|
|
bb7418419f | ||
|
|
cd369cbc6a | ||
|
|
0f04e28921 | ||
|
|
656ad21c00 | ||
|
|
dd967af42e | ||
|
|
98b69fad31 | ||
|
|
2ac5527d47 | ||
|
|
906cd84501 | ||
|
|
bcdd3606b7 | ||
|
|
2d6b8ab6b9 | ||
|
|
07bf868c29 | ||
|
|
b63fa7170a | ||
|
|
7518ee96d0 | ||
|
|
b1355dbab0 | ||
|
|
a1ad328b5b | ||
|
|
f8e94235ae | ||
|
|
033ffebb14 | ||
|
|
9a52f9b547 | ||
|
|
0d4d5ee13a | ||
|
|
2165f21455 | ||
|
|
253090e526 | ||
|
|
bb06b47a39 | ||
|
|
6e6bde4a8b | ||
|
|
57f1f87a41 | ||
|
|
704af911e7 | ||
|
|
4046a38b79 | ||
|
|
c44562bfdc | ||
|
|
1d571da777 | ||
|
|
8da419c462 | ||
|
|
089862e7eb | ||
|
|
6b91a53b1e | ||
|
|
535716116c | ||
|
|
ae4bf31d91 | ||
|
|
bb28f7d00e | ||
|
|
64d7bc5a89 | ||
|
|
aec7bde69b | ||
|
|
158b41b105 | ||
|
|
17d537e215 | ||
|
|
b5d335b039 | ||
|
|
317e829b6e | ||
|
|
83f76c0717 | ||
|
|
cb05738986 | ||
|
|
6b006d9b50 | ||
|
|
c11d754402 | ||
|
|
ea8861f30e | ||
|
|
f3f071efc7 | ||
|
|
ff05a1da03 | ||
|
|
f1fc938465 | ||
|
|
fc5cc91291 | ||
|
|
6b23754bf1 | ||
|
|
b8f8fa37a4 | ||
|
|
6fd4a2c135 | ||
|
|
f82cc5739e | ||
|
|
b4efb798cb | ||
|
|
8b67bb23d1 | ||
|
|
a4e66ff41c | ||
|
|
761017e751 | ||
|
|
7844ef3dca | ||
|
|
658c9bfa8e | ||
|
|
662c6bf418 | ||
|
|
a16aeefc31 | ||
|
|
b7d07c8ddf | ||
|
|
019bddd74c | ||
|
|
7651e8f2ca | ||
|
|
c8d2436b83 | ||
|
|
234a04211f | ||
|
|
1cf0408e63 | ||
|
|
ea43fb8d71 | ||
|
|
10d0cb77a9 | ||
|
|
e21014035e | ||
|
|
53ebc01c97 | ||
|
|
91fbe9427d | ||
|
|
f5a1707a27 | ||
|
|
a43f9bf51d | ||
|
|
503c796c22 | ||
|
|
b274b93365 | ||
|
|
acebb9e3d5 | ||
|
|
4decfa9054 | ||
|
|
0c0a65b102 | ||
|
|
dd2d0b1447 | ||
|
|
4c1ca54982 | ||
|
|
91fc653efa | ||
|
|
2a5aeec62f | ||
|
|
014a596416 | ||
|
|
3325f707c5 | ||
|
|
3b9cbb3cc9 | ||
|
|
88b295e6f2 | ||
|
|
10e160a38e | ||
|
|
63353eb2c3 | ||
|
|
c9edfa04e5 | ||
|
|
37a115262e | ||
|
|
52a0c49995 | ||
|
|
4915f529f4 | ||
|
|
e678036b45 | ||
|
|
ab1ba97841 | ||
|
|
dd94858214 | ||
|
|
60a276d457 | ||
|
|
a4e3a5cfe1 | ||
|
|
db23334b77 | ||
|
|
8b498aab5c | ||
|
|
2a07071bda | ||
|
|
eaef40a02d | ||
|
|
dc72dfdb8b | ||
|
|
b73c590c0d | ||
|
|
4f47919c1b | ||
|
|
c71183c1af | ||
|
|
6d6f077219 | ||
|
|
ae5006d18d | ||
|
|
f0a9a5aa68 | ||
|
|
c1b9f17a7e | ||
|
|
94039b3002 | ||
|
|
2da833ffad | ||
|
|
8f7ea9b528 | ||
|
|
a923202e6a | ||
|
|
71e8f373bb | ||
|
|
a5a8d74fac | ||
|
|
3ef5f2ddd8 | ||
|
|
517bee8165 | ||
|
|
1d50d1cf8f | ||
|
|
b185819bc1 | ||
|
|
781d7659ce | ||
|
|
c0b781b28f | ||
|
|
48e8ab7875 | ||
|
|
2d37548495 | ||
|
|
313198146d | ||
|
|
2233c0b72e | ||
|
|
4522f22338 | ||
|
|
fd743e0cbf | ||
|
|
a58ecd435d | ||
|
|
9352ec44ed | ||
|
|
109dce7358 | ||
|
|
947b735bb9 | ||
|
|
22c7889f13 | ||
|
|
b244406d84 | ||
|
|
e662c994ff | ||
|
|
b10d59f3cc | ||
|
|
d3dbe1e866 | ||
|
|
e70fc389c5 | ||
|
|
e8e6b50d1b | ||
|
|
47f262c6d4 | ||
|
|
d7b1f3f036 | ||
|
|
5ca1d020e2 | ||
|
|
39bd104635 | ||
|
|
4c8d89b778 | ||
|
|
87ba633cd5 | ||
|
|
cf6b7e0a5b | ||
|
|
35d7d95260 | ||
|
|
bf0dbeb096 | ||
|
|
e2abf66c51 | ||
|
|
366ed4b175 | ||
|
|
ac9212652e | ||
|
|
9b6a82d2da | ||
|
|
35c3dc500e | ||
|
|
7c0bff6102 | ||
|
|
7370474b17 | ||
|
|
12cdbcb198 | ||
|
|
3d5916b662 | ||
|
|
e657904a8b | ||
|
|
797e91b9e0 | ||
|
|
22180dfc2a | ||
|
|
c2d509d8a1 | ||
|
|
cd86e139ba | ||
|
|
0f620b1cbc | ||
|
|
24265d7ce7 | ||
|
|
da8818b77f | ||
|
|
fad5bbdf9d | ||
|
|
a71aee39f5 | ||
|
|
6660097d09 | ||
|
|
7f4714c584 | ||
|
|
db72390eea | ||
|
|
0669022fc3 | ||
|
|
cf93d7a7d6 | ||
|
|
f5b4d40c55 | ||
|
|
bfad5b3dfe | ||
|
|
4f7c42fb02 | ||
|
|
8a1e1edc46 | ||
|
|
d5ef03ec84 | ||
|
|
6eb2266559 | ||
|
|
3b391ba5f3 | ||
|
|
931fb3cb0d | ||
|
|
6acbdfda41 | ||
|
|
70c24e1562 | ||
|
|
b327f8d6e4 | ||
|
|
74e07b39e9 | ||
|
|
16dc7ae1ab | ||
|
|
20f6b052b3 | ||
|
|
11bcf17528 | ||
|
|
c81d999f39 | ||
|
|
7d59663252 | ||
|
|
dc1196af41 | ||
|
|
5b39b0e721 | ||
|
|
06e4d65bd1 | ||
|
|
1439f4aa32 | ||
|
|
ecfde89665 | ||
|
|
bc910e0998 | ||
|
|
923badd5e4 | ||
|
|
998ef41e92 | ||
|
|
f1e08f35c4 | ||
|
|
492327d60d | ||
|
|
3739b02739 | ||
|
|
24580323db | ||
|
|
383eb066a7 | ||
|
|
9b921c659c | ||
|
|
59ed888c34 | ||
|
|
a665a57931 | ||
|
|
c5574988cd | ||
|
|
0224cc3ac5 | ||
|
|
fe5a6cb281 | ||
|
|
ec3216fff6 | ||
|
|
13fb87ec7e | ||
|
|
63d5193d3c | ||
|
|
13e8d8aca5 | ||
|
|
5225a76fb4 | ||
|
|
6f934e4fc7 | ||
|
|
60ce6d5bb3 | ||
|
|
fc638d6712 | ||
|
|
956381efff | ||
|
|
c5f23dfa9b | ||
|
|
fb1a4c1e61 | ||
|
|
227cad4bcf | ||
|
|
de0639eabf | ||
|
|
145a95e68a | ||
|
|
01a69804d3 | ||
|
|
8fd8f4a503 | ||
|
|
77e54e4896 | ||
|
|
f576c140c1 | ||
|
|
f174e099d0 | ||
|
|
2a4bf9297d | ||
|
|
9d052f6e83 | ||
|
|
5c5b18ce34 | ||
|
|
e42fa4c1a2 | ||
|
|
03e884d6ff | ||
|
|
3a6f674afd | ||
|
|
7cd1dcd25e | ||
|
|
47979e3b09 | ||
|
|
d5e7717055 | ||
|
|
044a9fc032 | ||
|
|
f52e614806 | ||
|
|
0ef9503467 | ||
|
|
b8739828c4 | ||
|
|
56321c57a8 | ||
|
|
0d0b771622 | ||
|
|
bf279ae936 | ||
|
|
ca169a811d | ||
|
|
3bafc15ab2 | ||
|
|
64b1a4c52f | ||
|
|
e381153133 | ||
|
|
f937f7636d | ||
|
|
1c60b82be6 | ||
|
|
b03d690c10 | ||
|
|
42390a9e4f | ||
|
|
a215fd3d88 | ||
|
|
37e2c90d77 | ||
|
|
06c2acc7b5 | ||
|
|
a8d444db26 | ||
|
|
668a9facfc | ||
|
|
a9d50cc86b | ||
|
|
ada927079a | ||
|
|
8571099aa5 | ||
|
|
c3e0dbdad5 | ||
|
|
43fbb8446a | ||
|
|
e71a1fd360 | ||
|
|
eb920b8302 | ||
|
|
28fe00acb5 | ||
|
|
4a88f44930 | ||
|
|
de9137f94e | ||
|
|
66d9fe9f88 | ||
|
|
1be1f87f5f | ||
|
|
5a36e3b37d | ||
|
|
6cf5143c0c | ||
|
|
401511b61e | ||
|
|
b0e24e92bf | ||
|
|
1eed3d37e7 | ||
|
|
6e0a0a035a | ||
|
|
65d9ac8b37 | ||
|
|
9bac4d8c20 | ||
|
|
4bfda1bf62 | ||
|
|
2d2e9b4ff6 | ||
|
|
88e9b94f85 | ||
|
|
cb252deb8b | ||
|
|
0d394bf24f | ||
|
|
87faa050bb | ||
|
|
dba7e1ac40 | ||
|
|
3503cc4ccb | ||
|
|
246614a92e | ||
|
|
8bad17a91e | ||
|
|
8390d4539f | ||
|
|
ca384a52c7 | ||
|
|
4823ce4dda | ||
|
|
062a5c3e0d | ||
|
|
eaac7bb4e2 | ||
|
|
31ea309738 | ||
|
|
10c96919cb | ||
|
|
2e60f1a6f1 | ||
|
|
eafa86f1a8 | ||
|
|
8a2b0d509d | ||
|
|
368d132baa | ||
|
|
a5bd1d8317 | ||
|
|
efc02db950 | ||
|
|
9dccadc4d3 | ||
|
|
63e9748638 | ||
|
|
c87f18d684 | ||
|
|
f7caf9348b | ||
|
|
e8ab28ed3e | ||
|
|
74bca61a5e | ||
|
|
e0e7f7e534 | ||
|
|
5338b282f3 | ||
|
|
cc1c15e51f | ||
|
|
a951a65545 | ||
|
|
7f0c1b2d6d | ||
|
|
2f480d0588 | ||
|
|
d7e7b983ae | ||
|
|
4481d269b5 | ||
|
|
29c54f0247 | ||
|
|
64fae45ce9 | ||
|
|
f5d0cbf00b | ||
|
|
aca8ecf662 | ||
|
|
8d75493104 | ||
|
|
514df2316b | ||
|
|
6adb86bb82 | ||
|
|
9325f5aa58 | ||
|
|
66c9beddc1 | ||
|
|
60596f7871 | ||
|
|
7948c23500 | ||
|
|
221be0fd9c | ||
|
|
9f1b0df5df | ||
|
|
5bd27254dc | ||
|
|
a27c35a707 | ||
|
|
d82c2fab99 | ||
|
|
7283bfe777 | ||
|
|
caa3c8fd39 | ||
|
|
aa4c56ffbc | ||
|
|
2ea9958776 | ||
|
|
19335a6c99 | ||
|
|
28316f596f | ||
|
|
4100e45446 | ||
|
|
ae81888929 | ||
|
|
c60f2e15c0 | ||
|
|
ddbbd198e7 | ||
|
|
ba5cf2bff5 | ||
|
|
191db73137 | ||
|
|
6c111af657 | ||
|
|
5a09b795c9 | ||
|
|
f467eab103 | ||
|
|
f5b472653f | ||
|
|
26b3960b85 | ||
|
|
0ee02364a6 | ||
|
|
a7c1037b22 | ||
|
|
72c3908171 | ||
|
|
329828d598 | ||
|
|
90ed6cbf19 | ||
|
|
91e1614bfc | ||
|
|
5fc7abb4f8 | ||
|
|
9e6cd64216 | ||
|
|
f430be15a8 | ||
|
|
f2a112ca95 | ||
|
|
dc5462ac2a | ||
|
|
55c4dfba0b | ||
|
|
510efc3f05 | ||
|
|
9c2e3f9242 | ||
|
|
8391ee38c2 | ||
|
|
67837424df | ||
|
|
bcf7db6f7b | ||
|
|
bacf60535b | ||
|
|
69b78c3642 | ||
|
|
86cd2406f2 | ||
|
|
523ae4d082 | ||
|
|
5f74a8209b | ||
|
|
8abb5b7378 | ||
|
|
22fa387db5 | ||
|
|
549e054b24 | ||
|
|
ca97dd0de2 | ||
|
|
5db21127a6 | ||
|
|
f61f572f72 | ||
|
|
776bd1c91f | ||
|
|
7d4aaa42c2 | ||
|
|
ee3133bc64 | ||
|
|
01f2d65f66 | ||
|
|
ea571da98f | ||
|
|
84a8f2967f | ||
|
|
0a77f7c6d7 | ||
|
|
94b00594c6 | ||
|
|
030a6e2b0c | ||
|
|
97acf3255e | ||
|
|
2bcb27e8c4 | ||
|
|
f825a1f20d | ||
|
|
581120b0cc | ||
|
|
4d667e68c9 | ||
|
|
487c0ad25c | ||
|
|
2d7755d9f3 | ||
|
|
958ea167ee | ||
|
|
150a834b38 | ||
|
|
70016e7c6a | ||
|
|
312ebf03f3 | ||
|
|
c9baf941f1 | ||
|
|
331dd31c4a | ||
|
|
036effed32 | ||
|
|
ed621415c1 | ||
|
|
d62958c944 | ||
|
|
a43c3ca59c | ||
|
|
f468d577e1 | ||
|
|
072b5e69ac | ||
|
|
f9a4767bfa | ||
|
|
86c3a92a47 | ||
|
|
745a3a0b70 | ||
|
|
332b12ce05 | ||
|
|
23d55e53f3 | ||
|
|
fdc789c88d | ||
|
|
5c88243c45 | ||
|
|
37036b1834 | ||
|
|
fab9665cc5 | ||
|
|
8cc6a1037c | ||
|
|
f064edb6a2 | ||
|
|
5889d8ec24 | ||
|
|
5f1d04fe3b | ||
|
|
816a826901 | ||
|
|
acdf585e1d | ||
|
|
cfcbc21263 | ||
|
|
b97bdd0c45 | ||
|
|
ebc2753f19 | ||
|
|
15dd322da4 | ||
|
|
36baa73eca | ||
|
|
5a8d470524 | ||
|
|
9b78034176 | ||
|
|
8e69fac06b | ||
|
|
d316178f63 | ||
|
|
6a15f7b567 | ||
|
|
50ba2a10c5 | ||
|
|
0fa43c4bed | ||
|
|
4e1e7b490f | ||
|
|
389e6c6129 | ||
|
|
33ad3b5137 | ||
|
|
291f668e0a | ||
|
|
a253e1b256 | ||
|
|
577b220df7 | ||
|
|
1b1bdb0168 | ||
|
|
6cbb0dcd19 | ||
|
|
9b0283892d | ||
|
|
7035ff1c77 | ||
|
|
cecedd6d9d | ||
|
|
c398ddb77f | ||
|
|
67b3daf778 | ||
|
|
02cede8e41 | ||
|
|
fa3642d229 | ||
|
|
aa5a3cc9b7 | ||
|
|
06c80b1016 | ||
|
|
3958f589b0 | ||
|
|
6e0f6931ae | ||
|
|
9938daf5fb | ||
|
|
4e595bde80 | ||
|
|
fdd8bfd49a | ||
|
|
3c303fab3a | ||
|
|
da31ace091 | ||
|
|
b697c18c79 | ||
|
|
bb7bca8a14 | ||
|
|
8265e94496 | ||
|
|
cb2ef69941 | ||
|
|
41348eca17 | ||
|
|
a1edf5a5cd | ||
|
|
4a2cc02914 | ||
|
|
31784c7b21 | ||
|
|
788455f038 | ||
|
|
897221e22f | ||
|
|
e27ff04ced | ||
|
|
318e832203 | ||
|
|
f85616ba65 | ||
|
|
bd902c0407 | ||
|
|
d23ea8a53e | ||
|
|
d44d23c937 | ||
|
|
d603374a94 | ||
|
|
b9d34f057f | ||
|
|
2d833e4049 | ||
|
|
b4d02ac980 | ||
|
|
fbae6d302c | ||
|
|
8fef9e282a | ||
|
|
8e62c7b624 | ||
|
|
508638e471 | ||
|
|
81a0a2ffca | ||
|
|
6ea9bd260a | ||
|
|
85c4ce43bd | ||
|
|
adec767d87 | ||
|
|
82b035ad3c | ||
|
|
b8206031c6 | ||
|
|
41a949ed00 | ||
|
|
db7331918a | ||
|
|
465d510fdf | ||
|
|
96acc66756 | ||
|
|
069aa31988 | ||
|
|
73015f3d68 | ||
|
|
d031214499 | ||
|
|
55bfd2c0a4 | ||
|
|
81b170368f | ||
|
|
e4ddc5c91f | ||
|
|
d104220b80 | ||
|
|
a84e2be162 | ||
|
|
7030436933 | ||
|
|
d43bc59903 | ||
|
|
7b85ddaaf0 | ||
|
|
82b613b2f0 | ||
|
|
63be1e3d72 | ||
|
|
81c43341a8 | ||
|
|
09513c53b9 | ||
|
|
30916b02da | ||
|
|
5c0b61c13a | ||
|
|
a2f7c723d3 | ||
|
|
5690163436 | ||
|
|
a703e0a18f | ||
|
|
5e9e41f886 | ||
|
|
45f7ce7c13 | ||
|
|
39280f423d | ||
|
|
9c586d8c96 | ||
|
|
8102a56f75 | ||
|
|
7a524544e1 | ||
|
|
6bff06a10d | ||
|
|
e13018e328 | ||
|
|
bf439844bb | ||
|
|
2002b410f1 | ||
|
|
98b455c61e | ||
|
|
df277ff08b | ||
|
|
3b48496d22 | ||
|
|
f36ceb6a77 | ||
|
|
f149c900d4 | ||
|
|
ef76690abe | ||
|
|
19c0489f4a | ||
|
|
1aabfa5aba | ||
|
|
8807903aaf | ||
|
|
d0a21a6594 | ||
|
|
cac438db8b | ||
|
|
6d29c4caa2 | ||
|
|
8561e3a2f0 | ||
|
|
cb889d3aed | ||
|
|
af933501fa | ||
|
|
e417fcf63b | ||
|
|
5327c8c43e | ||
|
|
015531040c | ||
|
|
980e0f0280 | ||
|
|
b96c84c7a4 | ||
|
|
6b20706e3b | ||
|
|
ae5b8eee4a | ||
|
|
f1a777f46e | ||
|
|
b0bbae10cf | ||
|
|
af0ae0fb54 | ||
|
|
a067382825 | ||
|
|
350d600324 | ||
|
|
b1c16342ef | ||
|
|
b9db1ff4f8 | ||
|
|
2f7d370560 | ||
|
|
306a824d2c | ||
|
|
a40a98819c | ||
|
|
3014318dae | ||
|
|
e64355a7dd | ||
|
|
ad40fd500b | ||
|
|
f44389c679 | ||
|
|
bdf43c9310 | ||
|
|
29c7c7b758 | ||
|
|
838c3e6dad | ||
|
|
63a52c4bfb | ||
|
|
2bc8768d6e | ||
|
|
b459e2268a | ||
|
|
f07c141109 | ||
|
|
64ff46c42a | ||
|
|
de38e4f0c8 | ||
|
|
f40add0b7e | ||
|
|
8444f315a8 | ||
|
|
553e920004 | ||
|
|
6d5c221044 | ||
|
|
93263c70d2 | ||
|
|
510db06073 | ||
|
|
3a91f6c738 | ||
|
|
fd735815ab | ||
|
|
c5e315aa62 | ||
|
|
30f8adde69 | ||
|
|
b1c204cebc | ||
|
|
98c231d4b8 | ||
|
|
4119d848b7 | ||
|
|
16e8c9dcce | ||
|
|
30b9c3157d | ||
|
|
e529e083b2 | ||
|
|
204da46100 | ||
|
|
1e8316b32c | ||
|
|
b0d747dba1 | ||
|
|
d8750ae21a | ||
|
|
e096cda41b | ||
|
|
a7523a0c96 | ||
|
|
4d74476f65 | ||
|
|
043950fd64 | ||
|
|
a338851674 | ||
|
|
82082b411b | ||
|
|
8488beed78 | ||
|
|
11bca9538a | ||
|
|
17a423e59a | ||
|
|
51352be623 | ||
|
|
88df58456d | ||
|
|
e241d23add | ||
|
|
9ff21a199d | ||
|
|
60c2c8fb2b | ||
|
|
693abb954d | ||
|
|
c5eb518c5d | ||
|
|
5800478b8b | ||
|
|
57b0b97b23 | ||
|
|
c36b354df4 | ||
|
|
e915731667 | ||
|
|
03751d9104 | ||
|
|
21b94d84cb | ||
|
|
b34fd00186 | ||
|
|
986b42044e | ||
|
|
c8be1f6c58 | ||
|
|
db7a88b092 | ||
|
|
b04ff2ac65 | ||
|
|
f3f8acf053 | ||
|
|
ee00fda0f3 | ||
|
|
2bc18328e6 | ||
|
|
1ff95cfcf5 | ||
|
|
35b59e6473 | ||
|
|
2da68acc8f | ||
|
|
2dc432734e | ||
|
|
b1f2785a72 | ||
|
|
6d00a83a4c | ||
|
|
4dd5d111a2 | ||
|
|
3856d76b9e | ||
|
|
966a978c9d | ||
|
|
84eab2dc22 | ||
|
|
87d208df8f | ||
|
|
e7acbb48bc | ||
|
|
393470f1e9 | ||
|
|
8abd9ebf86 | ||
|
|
6dcee770a7 | ||
|
|
422c521f15 | ||
|
|
09842835f7 | ||
|
|
6a868106fb | ||
|
|
300fa6f35b | ||
|
|
bcfdd76fd7 | ||
|
|
524d6a5f17 | ||
|
|
c8a7e3a082 | ||
|
|
78b4aea833 | ||
|
|
b1779cb175 | ||
|
|
7e98966eda | ||
|
|
a05d21be83 | ||
|
|
30837fbc31 | ||
|
|
d39eeb6f6c | ||
|
|
6ef6e59db7 | ||
|
|
3acb0e2164 | ||
|
|
9ba4c16d74 | ||
|
|
3da1ef465d | ||
|
|
4e49220641 | ||
|
|
d22a5ec86d | ||
|
|
0755ad3a2d | ||
|
|
da1ccfa52c | ||
|
|
cd473deac1 | ||
|
|
1d14ef1f32 | ||
|
|
9e8ea6e828 | ||
|
|
4fa1991440 | ||
|
|
180c3d3cb0 | ||
|
|
85dd9ac02e | ||
|
|
29e63417e2 | ||
|
|
b40d9158fe | ||
|
|
9ad1163392 | ||
|
|
11ebb195fc | ||
|
|
cac3c6f6f2 | ||
|
|
931d90f013 | ||
|
|
e0845051ba | ||
|
|
82433f72a0 | ||
|
|
4ac5450edb | ||
|
|
68110225ca | ||
|
|
595ed43d77 | ||
|
|
38659ebfc9 | ||
|
|
66171d7d0a | ||
|
|
385ca07c02 | ||
|
|
ed016f43f9 | ||
|
|
8075762f6e | ||
|
|
1b1a510a71 | ||
|
|
6f6cf73c6d | ||
|
|
8b4f0b54ce | ||
|
|
7f9c34d034 | ||
|
|
8806494cc3 | ||
|
|
2f1ff91e28 | ||
|
|
8876f424b9 | ||
|
|
cb6b5af039 | ||
|
|
ccb2aa33f0 | ||
|
|
8fe32aa753 | ||
|
|
9d66db8cc0 | ||
|
|
472f486347 | ||
|
|
fe7c509e9f | ||
|
|
7f6e7eec2f | ||
|
|
bb32c0aa5e | ||
|
|
4074d0fa30 | ||
|
|
67b5b7922c | ||
|
|
91a913e4c1 | ||
|
|
52c15f9cdc | ||
|
|
4c48b087bb | ||
|
|
99fe81c166 | ||
|
|
6e814ad602 | ||
|
|
0b2461ebdd | ||
|
|
ee59e8783e | ||
|
|
bf45f34450 | ||
|
|
c7d14d4b5b | ||
|
|
789f10b7b3 | ||
|
|
65b95f5857 | ||
|
|
140d7506a5 | ||
|
|
83385acb41 | ||
|
|
3992a25c88 | ||
|
|
834184c746 | ||
|
|
21d201cae4 | ||
|
|
9e2491e42d | ||
|
|
8a7c775654 | ||
|
|
22fb9e8176 | ||
|
|
23023c412b | ||
|
|
9a5a63cc70 | ||
|
|
d6149a46ac | ||
|
|
dae0a4a61d | ||
|
|
ac42b7733c | ||
|
|
0bbf4b2fa4 | ||
|
|
c56f6ad2a9 | ||
|
|
15e6238a3c | ||
|
|
71433f39ae | ||
|
|
4ba5e766c6 | ||
|
|
b6a7bbb898 | ||
|
|
fd838eacad | ||
|
|
f80030b3b6 | ||
|
|
e269b8b9cb | ||
|
|
3a4a6d211e | ||
|
|
87259cb2d9 | ||
|
|
de58d66027 | ||
|
|
82d4e0f66e | ||
|
|
2256b432f4 | ||
|
|
c075b4eb6c | ||
|
|
179747f224 | ||
|
|
49137870ea | ||
|
|
f279276828 | ||
|
|
5206425338 | ||
|
|
9fc584763c | ||
|
|
2fc103b0ad | ||
|
|
df64d7c93c | ||
|
|
0cd4882bb5 | ||
|
|
836241406b | ||
|
|
3e1908f5ed | ||
|
|
27b415c010 | ||
|
|
1fa2d69b8a | ||
|
|
072b505aff | ||
|
|
6e5972e6ee | ||
|
|
0a8e8c950b | ||
|
|
9e95ccb1f6 | ||
|
|
206adc200c | ||
|
|
50c99b46e3 | ||
|
|
05ef2453a6 | ||
|
|
613424dff5 | ||
|
|
a92b061b97 | ||
|
|
2153b15b38 | ||
|
|
107a52eb9c | ||
|
|
a9c2fd48be | ||
|
|
952f903b4f | ||
|
|
f007b2aa16 | ||
|
|
075a4f4792 | ||
|
|
fd38ba7327 | ||
|
|
dd0238bd19 | ||
|
|
e1e5a9a79d | ||
|
|
b076824f1b | ||
|
|
7515f0eb4b | ||
|
|
9c03903442 | ||
|
|
9e26470826 | ||
|
|
ab3b5ef074 | ||
|
|
6372dd600c | ||
|
|
77ec6b3ca2 | ||
|
|
99a3e77bd7 | ||
|
|
165ab509df | ||
|
|
90f0634b85 | ||
|
|
08c5a1c438 | ||
|
|
d69480e40e | ||
|
|
c77d934480 | ||
|
|
a456e4afc3 | ||
|
|
f31ab43bc2 | ||
|
|
bdaccee162 | ||
|
|
10d1a4abfe | ||
|
|
42e0104496 | ||
|
|
efbbd87f5c | ||
|
|
cca83ca04e | ||
|
|
45b33a8218 | ||
|
|
c5278ed38d | ||
|
|
d578b32de5 | ||
|
|
ecc07904a4 | ||
|
|
5d0b0282f0 | ||
|
|
a556b2fa78 | ||
|
|
cc54bada48 | ||
|
|
63b9852671 | ||
|
|
983022d90d | ||
|
|
5f5477d7b3 | ||
|
|
ba3e49f886 | ||
|
|
22542f1713 | ||
|
|
5a60f49e8f | ||
|
|
866908cd36 | ||
|
|
df8b3b8b99 | ||
|
|
7ccdceb851 | ||
|
|
a1121095a7 | ||
|
|
9b0e6cddfe | ||
|
|
102fda35e7 | ||
|
|
cfd4f039a1 | ||
|
|
0d9d0a6de3 | ||
|
|
5d9f381b57 | ||
|
|
11d84380a1 | ||
|
|
4e3fa28635 | ||
|
|
6e222dcc1d | ||
|
|
2533e2941a | ||
|
|
38d8f69b9d | ||
|
|
4ed36d1379 | ||
|
|
76f9adbfa1 | ||
|
|
4b98540bfb | ||
|
|
73c059955d | ||
|
|
14609d89de | ||
|
|
aaeb6088e2 | ||
|
|
44de3a96e4 | ||
|
|
1d471ab04c | ||
|
|
ff51785037 | ||
|
|
b4494e18e3 | ||
|
|
14a49c0f15 | ||
|
|
a93207ba69 | ||
|
|
21096f1284 | ||
|
|
4aec286d2c | ||
|
|
222bb1fb94 | ||
|
|
9ed32ecb7d | ||
|
|
7948fd577c | ||
|
|
734b4eb1e3 | ||
|
|
1f9ea04aa3 | ||
|
|
019a6972c4 | ||
|
|
a2d1cfbb71 | ||
|
|
2235f66c97 | ||
|
|
c625688889 | ||
|
|
fd1c656b06 | ||
|
|
c8fd3fc5e2 | ||
|
|
5705d35553 | ||
|
|
ad8c38b316 | ||
|
|
175d90e9f5 | ||
|
|
b16b9dc41d | ||
|
|
4618753f81 | ||
|
|
9712342290 | ||
|
|
acf18c239c | ||
|
|
68b44ada9d | ||
|
|
26c2751848 | ||
|
|
1d92165c46 | ||
|
|
f16c694426 | ||
|
|
f47e708733 | ||
|
|
e71c437b3e | ||
|
|
36ec780bb3 | ||
|
|
511ee4b070 | ||
|
|
50896da1b7 | ||
|
|
0bf8abba0c | ||
|
|
e085b42a12 | ||
|
|
d905c2ce8c | ||
|
|
c03a176e07 | ||
|
|
93fecf375d | ||
|
|
6454eb33f6 | ||
|
|
f34ebc00d6 | ||
|
|
0656f5c724 | ||
|
|
b62c79cc88 | ||
|
|
1bc670317b | ||
|
|
3c4a3fc9f1 | ||
|
|
a4fbc3aa22 | ||
|
|
936d59f695 | ||
|
|
4b7cd0c3a0 | ||
|
|
2c2f004af9 | ||
|
|
359334daa7 | ||
|
|
b6b4238830 | ||
|
|
1477f8b353 | ||
|
|
f371c153ec | ||
|
|
0d66dae341 | ||
|
|
a81fb00c90 | ||
|
|
459924400c | ||
|
|
bb6b2e5edd | ||
|
|
57b0bfcefb | ||
|
|
99f57a9251 | ||
|
|
4e73df64be | ||
|
|
8ceee5ad00 | ||
|
|
104a5af83a | ||
|
|
88b53db488 | ||
|
|
348a43ff9a | ||
|
|
4dbbd1cccb | ||
|
|
d76f524735 | ||
|
|
5301272b30 | ||
|
|
8da87bb4b4 | ||
|
|
6174173a92 | ||
|
|
b5cb663dae | ||
|
|
0114413ba8 | ||
|
|
4e09f9886a | ||
|
|
abb59cc7b1 | ||
|
|
54bd888790 | ||
|
|
e1e77f4863 | ||
|
|
9fba1b019d | ||
|
|
4d59608a78 | ||
|
|
e5f5111460 | ||
|
|
2267ea6a70 | ||
|
|
318f8f047a | ||
|
|
c380a1e15b | ||
|
|
b8566cba3f | ||
|
|
7913729ca9 | ||
|
|
5b718c0898 | ||
|
|
cc91d35f7c | ||
|
|
17f7e2548a | ||
|
|
675bcff951 | ||
|
|
dc6c190a6f | ||
|
|
4b126d0bd2 | ||
|
|
84db51dd9a | ||
|
|
4755aa4ba3 | ||
|
|
e261540b93 | ||
|
|
cc878e0dcb | ||
|
|
586d519546 | ||
|
|
d0d81458fe | ||
|
|
b411d2f622 | ||
|
|
42ea96ece2 | ||
|
|
e721107509 | ||
|
|
f1b2cc43cf | ||
|
|
4888412fd0 | ||
|
|
b7363b8dcd | ||
|
|
ac4b0a0a95 | ||
|
|
efb7db29a9 | ||
|
|
9265e9faeb | ||
|
|
488c217bc4 | ||
|
|
afc445693d | ||
|
|
4f38701ef8 | ||
|
|
78cf9e7486 | ||
|
|
96546d9613 | ||
|
|
dab37f35c8 | ||
|
|
3f53dd7f8e | ||
|
|
c261401dd6 | ||
|
|
dd3c499a13 | ||
|
|
1f042b564b | ||
|
|
878bf63a41 | ||
|
|
9115f5f62e | ||
|
|
5bcab05743 | ||
|
|
7a2e9381ab | ||
|
|
a039d8f2c6 | ||
|
|
83cadcceca | ||
|
|
f6ea584a8e | ||
|
|
9b4c20b746 | ||
|
|
f9c3ac07fd | ||
|
|
1ce8f4b469 | ||
|
|
b515305bbd | ||
|
|
636428645e | ||
|
|
0392b7e816 | ||
|
|
30a285e84d | ||
|
|
3234a4d470 | ||
|
|
9e8c5a6a54 | ||
|
|
bcb520155f | ||
|
|
c58542b3ec | ||
|
|
aa82f9d35e | ||
|
|
51e394dd97 | ||
|
|
451e9c2214 | ||
|
|
16fe3c3ff5 | ||
|
|
03e96d9728 | ||
|
|
9c87a3951c | ||
|
|
8dafa7f1aa | ||
|
|
8fd1f1b2f9 | ||
|
|
86038e9713 | ||
|
|
83f20da730 | ||
|
|
96ee73872a | ||
|
|
68cb63878b | ||
|
|
c71eef258d | ||
|
|
e5071aae87 | ||
|
|
fe6a0f27a3 | ||
|
|
b4b10df22c | ||
|
|
8ee2b40a43 | ||
|
|
84f2af6226 | ||
|
|
47d89535a5 | ||
|
|
cd113c6d7e | ||
|
|
7eac33b069 | ||
|
|
3301c7a1b5 | ||
|
|
f5d915f224 | ||
|
|
2e92013ace | ||
|
|
90afba408f | ||
|
|
000c01f40b | ||
|
|
bf70f6731c | ||
|
|
534d890dcb | ||
|
|
a38c1717ba | ||
|
|
1d4540abda | ||
|
|
d6ad164dd8 | ||
|
|
fd4c95f6a3 | ||
|
|
48ef15f4c6 | ||
|
|
baeca7cbed | ||
|
|
bb2933603d | ||
|
|
8f2650dccd | ||
|
|
189d525a72 | ||
|
|
a0f69b8ca1 | ||
|
|
9d70ddf79a | ||
|
|
fb804e7f85 | ||
|
|
51c9a1f0a7 | ||
|
|
3dd8003e36 | ||
|
|
4a604c81f2 | ||
|
|
acf700d14b | ||
|
|
79a7eade35 | ||
|
|
3f6664529c | ||
|
|
3967856633 | ||
|
|
f616911146 | ||
|
|
051c752c7a | ||
|
|
7f6b059120 | ||
|
|
225f868a54 | ||
|
|
856074c76f | ||
|
|
bd1155a12a | ||
|
|
73a36857ec | ||
|
|
95540c5672 | ||
|
|
aafcd4f305 | ||
|
|
69d8cb921f | ||
|
|
f0f292d62e | ||
|
|
216848a80d | ||
|
|
cf54ab0e22 | ||
|
|
5799d96e96 | ||
|
|
5e8f12eb0a | ||
|
|
b2c155542b | ||
|
|
682d07a7ee | ||
|
|
c211ff0f60 | ||
|
|
0b42c80ff4 | ||
|
|
226758dbb4 | ||
|
|
ee627187d9 | ||
|
|
6cf1a53188 | ||
|
|
3535c5274b | ||
|
|
90d6ebf236 | ||
|
|
bfe4b94cd6 | ||
|
|
dc90aa55f0 | ||
|
|
acf7b9d801 | ||
|
|
ca969c4553 | ||
|
|
e45e7f683f | ||
|
|
5f0000bf38 |
{kind=link}
{kind=link}
+12
-4
@@ -1,4 +1,12 @@
|
||||
test/tmp
|
||||
psol/
|
||||
psol-*.tar.gz
|
||||
*.*.*.*.tar.gz
|
||||
Makefile
|
||||
!third_party/libjpeg_turbo/yasm/source/config/linux/Makefile
|
||||
*.mk
|
||||
!install/**/*.mk
|
||||
*.Makefile
|
||||
client.timestamp
|
||||
hooks.timestamp
|
||||
build/gyp_helper.pyc
|
||||
build/landmine_utils.pyc
|
||||
out/
|
||||
tools/closure/
|
||||
!devel/Makefile
|
||||
|
||||
+113
@@ -0,0 +1,113 @@
|
||||
# The two httpds are the longest syncs, so we'd like to start them first.
|
||||
[submodule "third_party/httpd/src"]
|
||||
path = third_party/httpd/src
|
||||
url = git://git.apache.org/httpd.git
|
||||
[submodule "third_party/httpd24/src"]
|
||||
path = third_party/httpd24/src
|
||||
url = git://git.apache.org/httpd.git
|
||||
[submodule "third_party/brotli/src"]
|
||||
path = third_party/brotli/src
|
||||
url = https://github.com/google/brotli.git
|
||||
[submodule "third_party/giflib"]
|
||||
path = third_party/giflib
|
||||
url = https://github.com/pagespeed/giflib.git
|
||||
[submodule "third_party/closure_library"]
|
||||
path = third_party/closure_library
|
||||
url = https://github.com/google/closure-library.git
|
||||
[submodule "third_party/aprutil/src"]
|
||||
path = third_party/aprutil/src
|
||||
url = git://git.apache.org/apr-util.git
|
||||
[submodule "third_party/re2/src"]
|
||||
path = third_party/re2/src
|
||||
url = https://github.com/google/re2.git
|
||||
[submodule "third_party/icu"]
|
||||
path = third_party/icu
|
||||
url = https://github.com/pagespeed/icu.git
|
||||
[submodule "third_party/libjpeg_turbo/src"]
|
||||
path = third_party/libjpeg_turbo/src
|
||||
url = https://chromium.googlesource.com/chromium/deps/libjpeg_turbo
|
||||
# For gyp generated makefiles.
|
||||
ignore = untracked
|
||||
[submodule "third_party/libjpeg_turbo/yasm/source/patched-yasm"]
|
||||
path = third_party/libjpeg_turbo/yasm/source/patched-yasm
|
||||
url = https://chromium.googlesource.com/chromium/deps/yasm/patched-yasm
|
||||
[submodule "third_party/libpng/src"]
|
||||
path = third_party/libpng/src
|
||||
url = https://github.com/glennrp/libpng.git
|
||||
[submodule "third_party/hiredis/src"]
|
||||
path = third_party/hiredis/src
|
||||
url = https://github.com/redis/hiredis.git
|
||||
[submodule "third_party/apr/src"]
|
||||
path = third_party/apr/src
|
||||
url = git://git.apache.org/apr.git
|
||||
[submodule "third_party/optipng"]
|
||||
path = third_party/optipng
|
||||
url = https://github.com/pagespeed/optipng.git
|
||||
[submodule "third_party/libwebp"]
|
||||
path = third_party/libwebp
|
||||
url = https://chromium.googlesource.com/webm/libwebp.git
|
||||
[submodule "third_party/serf/src"]
|
||||
path = third_party/serf/src
|
||||
url = https://git.apache.org/serf.git
|
||||
[submodule "third_party/grpc/src"]
|
||||
path = third_party/grpc/src
|
||||
url = https://github.com/grpc/grpc.git
|
||||
[submodule "third_party/protobuf/src"]
|
||||
path = third_party/protobuf/src
|
||||
url = https://github.com/google/protobuf.git
|
||||
[submodule "third_party/modp_b64"]
|
||||
path = third_party/modp_b64
|
||||
url = https://chromium.googlesource.com/chromium/src/third_party/modp_b64
|
||||
# For gyp generated makefiles.
|
||||
ignore = untracked
|
||||
[submodule "third_party/boringssl/src"]
|
||||
path = third_party/boringssl/src
|
||||
url = https://boringssl.googlesource.com/boringssl.git
|
||||
[submodule "third_party/zlib"]
|
||||
path = third_party/zlib
|
||||
url = https://github.com/pagespeed/zlib.git
|
||||
[submodule "third_party/chromium/src/base"]
|
||||
path = third_party/chromium/src/base
|
||||
url = https://chromium.googlesource.com/chromium/src/base
|
||||
# For gyp generated makefiles.
|
||||
ignore = untracked
|
||||
[submodule "third_party/chromium/src/build"]
|
||||
path = third_party/chromium/src/build
|
||||
url = https://chromium.googlesource.com/chromium/src/build
|
||||
[submodule "third_party/chromium/src/googleurl"]
|
||||
path = third_party/chromium/src/googleurl
|
||||
url = https://chromium.googlesource.com/external/google-url
|
||||
[submodule "third_party/google-sparsehash/src"]
|
||||
path = third_party/google-sparsehash/src
|
||||
url = https://github.com/google/sparsehash.git
|
||||
[submodule "third_party/domain_registry_provider"]
|
||||
path = third_party/domain_registry_provider
|
||||
url = https://github.com/pagespeed/domain-registry-provider.git
|
||||
[submodule "third_party/jsoncpp/src"]
|
||||
path = third_party/jsoncpp/src
|
||||
url = https://github.com/open-source-parsers/jsoncpp.git
|
||||
[submodule "third_party/gflags/arch"]
|
||||
path = third_party/gflags/arch
|
||||
url = https://chromium.googlesource.com/external/webrtc/trunk/third_party/gflags
|
||||
[submodule "third_party/gflags/src"]
|
||||
path = third_party/gflags/src
|
||||
url = https://chromium.googlesource.com/external/gflags/src
|
||||
[submodule "testing/gtest"]
|
||||
path = testing/gtest
|
||||
url = https://github.com/google/googletest.git
|
||||
[submodule "testing/gmock"]
|
||||
path = testing/gmock
|
||||
url = https://github.com/google/googlemock.git
|
||||
[submodule "tools/clang"]
|
||||
path = tools/clang
|
||||
url = https://chromium.googlesource.com/chromium/src/tools/clang
|
||||
[submodule "tools/gyp"]
|
||||
path = tools/gyp
|
||||
url = https://chromium.googlesource.com/external/gyp
|
||||
# For building a development apache.
|
||||
[submodule "third_party/nghttp2"]
|
||||
path = third_party/nghttp2
|
||||
url = https://github.com/nghttp2/nghttp2
|
||||
[submodule "third_party/mod_fcgid"]
|
||||
path = third_party/mod_fcgid
|
||||
url = https://github.com/pagespeed/mod_fcgid.git
|
||||
+40
@@ -0,0 +1,40 @@
|
||||
language: c++
|
||||
sudo: required
|
||||
compiler:
|
||||
- gcc
|
||||
|
||||
git:
|
||||
# It takes a while to clone our submodules, so we'd like to use --jobs to
|
||||
# speed it up. Here we prevent travis from using git clone --recursive, so
|
||||
# below in before_install we can manually update including --jobs.
|
||||
submodules: false
|
||||
|
||||
before_install:
|
||||
# Unfortunately, the version of git we get by default is too low to support
|
||||
# --jobs on subdmodule, so update git before pulling in the submodules.
|
||||
- sudo add-apt-repository -y ppa:git-core/ppa
|
||||
- sudo apt-get update -q
|
||||
- sudo apt-get install -q -y git
|
||||
- git submodule update --init --recursive --jobs=6
|
||||
|
||||
env:
|
||||
global:
|
||||
- MAKEFLAGS=-j3
|
||||
matrix:
|
||||
- BIT_FLAG=
|
||||
# This would do another build for 32-bit, but we're already borderline
|
||||
# too slow on faster 64-bit, so skip this for now.
|
||||
# - BIT_FLAG=--32bit
|
||||
|
||||
script:
|
||||
# Travis will time out our build if doesn't output anything for > 10 mintes,
|
||||
# but --verbose sometimes outputs more than 4 MB of data, which will also
|
||||
# cause our build to be killed. travis_wait allows the command to be silent
|
||||
# for longer, but has the downside of not producing output if we timeout. See:
|
||||
# https://docs.travis-ci.com/user/common-build-problems/#Build-times-out-because-no-output-was-received
|
||||
# For now, stick with --verbose and keep an eye on the logs.
|
||||
- install/build_release.sh --verbose --skip_psol --debug $BIT_FLAG
|
||||
|
||||
notifications:
|
||||
email:
|
||||
- pagespeed-ci@googlegroups.com
|
||||
@@ -1,38 +1,36 @@
|
||||

|
||||
# mod_pagespeed
|
||||

|
||||
|
||||
ngx_pagespeed speeds up your site and reduces page load time by automatically
|
||||
applying web performance best practices to pages and associated assets (CSS,
|
||||
JavaScript, images) without requiring you to modify your existing content or
|
||||
workflow. Features include:
|
||||
|CI|Status|
|
||||
|---|---|
|
||||
|Travis|[](https://travis-ci.org/pagespeed/mod_pagespeed)|
|
||||
|Jenkins (CentOS5)|[](http://104.154.17.78:8080/job/mod_pagespeed)|
|
||||
|
||||
- Image optimization: stripping meta-data, dynamic resizing, recompression
|
||||
- CSS & JavaScript minification, concatenation, inlining, and outlining
|
||||
- Small resource inlining
|
||||
- Deferring image and JavaScript loading
|
||||
- HTML rewriting
|
||||
- Cache lifetime extension
|
||||
- and
|
||||
[more](https://developers.google.com/speed/docs/mod_pagespeed/config_filters)
|
||||
`mod_pagespeed` is an open-source Apache module created by Google to help Make the Web Faster by rewriting web pages to reduce latency and bandwidth.
|
||||
|
||||
To see ngx_pagespeed in action, with example pages for each of the
|
||||
optimizations, see our <a href="http://ngxpagespeed.com">demonstration site</a>.
|
||||
mod_pagespeed releases are available as [precompiled linux packages](https://modpagespeed.com/doc/download) or as [source](https://modpagespeed.com/doc/build_mod_pagespeed_from_source). (See [Release Notes](https://modpagespeed.com/doc/release_notes) for information about bugs fixed)
|
||||
|
||||
## How to build
|
||||
mod_pagespeed is an open-source Apache module which automatically applies web performance best practices to pages, and associated assets (CSS, JavaScript, images) without requiring that you modify your existing content or workflow.
|
||||
|
||||
Follow the steps on <a
|
||||
href="https://developers.google.com/speed/pagespeed/module/build_ngx_pagespeed_from_source">build
|
||||
ngx_pagespeed from source</a>.
|
||||
mod_pagespeed is built on PageSpeed Optimization Libraries, deployed across 100,000+ web-sites, and provided by popular hosting and CDN providers such as DreamHost, GoDaddy, EdgeCast, and others. There are 40+ available optimizations filters, which include:
|
||||
|
||||
## How to use
|
||||
- Image optimization, compression, and resizing
|
||||
- CSS & JavaScript concatenation, minification, and inlining
|
||||
- Cache extension, domain sharding, and domain rewriting
|
||||
- Deferred loading of JavaScript and image resources
|
||||
- and many others...
|
||||
|
||||
Follow the steps on <a
|
||||
href="https://developers.google.com/speed/pagespeed/module/configuration">PageSpeed
|
||||
configuration</a>.
|
||||
[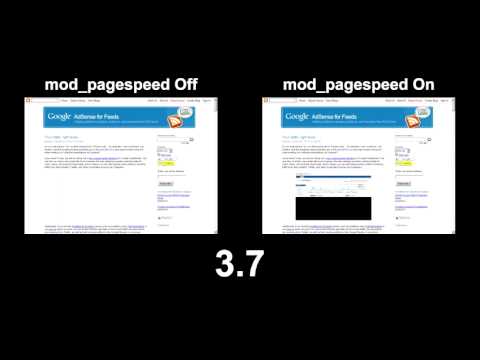](http://www.youtube.com/watch?v=8moGR2qf994)
|
||||
|
||||
For feedback, questions, and to follow
|
||||
the progress of the project:
|
||||
| Try it | [modpagespeed.com](https://modpagespeed.com) |
|
||||
|--- |--- |
|
||||
| Read about it |https://developers.google.com/speed/pagespeed/module |
|
||||
| Download it | https://modpagespeed.com/doc/download |
|
||||
| Check announcements |https://groups.google.com/group/mod-pagespeed-announce |
|
||||
| Discuss it | https://groups.google.com/group/mod-pagespeed-discuss |
|
||||
|FAQ | https://modpagespeed.com/doc/faq |
|
||||
|
||||
- [ngx-pagespeed-discuss mailing
|
||||
list](https://groups.google.com/forum/#!forum/ngx-pagespeed-discuss)
|
||||
- [ngx-pagespeed-announce mailing
|
||||
list](https://groups.google.com/forum/#!forum/ngx-pagespeed-announce)
|
||||
|
||||
Curious to learn more about mod_pagespeed? Check out our GDL episode below, which covers the history of the project, an architectural overview of how mod_pagespeed works under the hood, and a number of operational tips and best practices for deploying mod_pagespeed.
|
||||
|
||||
[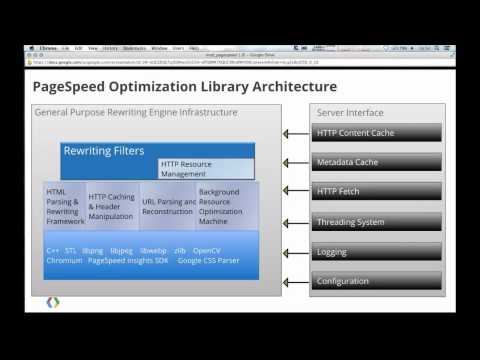](http://www.youtube.com/watch?v=6uCAdQSHhmA)
|
||||
|
||||
@@ -0,0 +1,63 @@
|
||||
# Copyright (c) 2009 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
# Base was branched from the chromium version to reduce the number of
|
||||
# dependencies of this package. Specifically, we would like to avoid
|
||||
# depending on the chrome directory, which contains the chrome version
|
||||
# and branding information.
|
||||
# TODO(morlovich): push this refactoring to chronium trunk.
|
||||
|
||||
{
|
||||
'variables': {
|
||||
'chromium_code': 1,
|
||||
'chromium_root': '<(DEPTH)/third_party/chromium/src',
|
||||
},
|
||||
'includes': [
|
||||
'base.gypi',
|
||||
],
|
||||
'targets': [
|
||||
{
|
||||
# This is the subset of files from base that should not be used with a
|
||||
# dynamic library. Note that this library cannot depend on base because
|
||||
# base depends on base_static.
|
||||
'target_name': 'base_static',
|
||||
'type': 'static_library',
|
||||
'sources': [
|
||||
'<(chromium_root)/base/base_switches.cc',
|
||||
'<(chromium_root)/base/base_switches.h',
|
||||
'<(chromium_root)/base/win/pe_image.cc',
|
||||
'<(chromium_root)/base/win/pe_image.h',
|
||||
],
|
||||
'include_dirs': [
|
||||
'<(chromium_root)',
|
||||
'<(DEPTH)',
|
||||
],
|
||||
},
|
||||
{
|
||||
'target_name': 'base_unittests',
|
||||
'type': 'executable',
|
||||
'sources': [
|
||||
'<(chromium_root)/base/string_piece_unittest.cc',
|
||||
'<(chromium_root)/base/win/win_util_unittest.cc',
|
||||
],
|
||||
'dependencies': [
|
||||
'base',
|
||||
'base_static',
|
||||
'<(DEPTH)/testing/gmock.gyp:gmock',
|
||||
'<(DEPTH)/testing/gtest.gyp:gtest',
|
||||
'<(DEPTH)/testing/gtest.gyp:gtest_main',
|
||||
],
|
||||
'include_dirs': [
|
||||
'<(DEPTH)',
|
||||
],
|
||||
'conditions': [
|
||||
['OS != "win"', {
|
||||
'sources!': [
|
||||
'<(chromium_root)/base/win_util_unittest.cc',
|
||||
],
|
||||
}],
|
||||
],
|
||||
},
|
||||
],
|
||||
}
|
||||
+298
@@ -0,0 +1,298 @@
|
||||
# Copyright (c) 2009 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
{
|
||||
'target_defaults': {
|
||||
'variables': {
|
||||
'base_target': 0,
|
||||
'chromium_root': '<(DEPTH)/third_party/chromium/src',
|
||||
'conditions': [
|
||||
# The default stack_trace_posix.cc is not compatible with NaCL newlib
|
||||
# toolchain, so we provide a stubbed version when building for NaCL.
|
||||
[ 'build_nacl==1', {
|
||||
'stack_trace_posix_cc': 'nacl_stubs/stack_trace_posix.cc',
|
||||
}, {
|
||||
'stack_trace_posix_cc': '<(chromium_root)/base/debug/stack_trace_posix.cc',
|
||||
}],
|
||||
],
|
||||
},
|
||||
'target_conditions': [
|
||||
# This part is shared between the targets defined below. Only files and
|
||||
# settings relevant for building the Win64 target should be added here.
|
||||
# All the rest should be added to the 'base' target below.
|
||||
['base_target==1', {
|
||||
'sources': [
|
||||
'<(chromium_root)/build/build_config.h',
|
||||
'<(chromium_root)/base/third_party/dmg_fp/dmg_fp.h',
|
||||
'<(chromium_root)/base/third_party/dmg_fp/g_fmt.cc',
|
||||
'<(chromium_root)/base/third_party/dmg_fp/dtoa_wrapper.cc',
|
||||
'<(chromium_root)/base/third_party/icu/icu_utf.cc',
|
||||
'<(chromium_root)/base/third_party/icu/icu_utf.h',
|
||||
'<(chromium_root)/base/third_party/nspr/prtime.cc',
|
||||
'<(chromium_root)/base/third_party/nspr/prtime.h',
|
||||
'<(chromium_root)/base/at_exit.cc',
|
||||
'<(chromium_root)/base/at_exit.h',
|
||||
'<(chromium_root)/base/atomicops.h',
|
||||
'<(chromium_root)/base/atomicops_internals_x86_gcc.cc',
|
||||
'<(chromium_root)/base/atomicops_internals_x86_msvc.h',
|
||||
'<(chromium_root)/base/callback.h',
|
||||
'<(chromium_root)/base/callback_internal.h',
|
||||
'<(chromium_root)/base/callback_internal.cc',
|
||||
'<(chromium_root)/base/command_line.cc',
|
||||
'<(chromium_root)/base/command_line.h',
|
||||
'<(chromium_root)/base/cpu_patched.cc',
|
||||
'<(chromium_root)/base/cpu.h',
|
||||
'<(chromium_root)/base/debug/alias.cc',
|
||||
'<(chromium_root)/base/debug/alias.h',
|
||||
'<(chromium_root)/base/debug/debugger.cc',
|
||||
'<(chromium_root)/base/debug/debugger.h',
|
||||
'<(chromium_root)/base/debug/debugger_posix.cc',
|
||||
'<(chromium_root)/base/debug/debugger_win.cc',
|
||||
'<(chromium_root)/base/debug/profiler.cc',
|
||||
'<(chromium_root)/base/debug/profiler.h',
|
||||
'<(chromium_root)/base/debug/stack_trace.cc',
|
||||
'<(chromium_root)/base/debug/stack_trace.h',
|
||||
'<(stack_trace_posix_cc)',
|
||||
'<(chromium_root)/base/debug/stack_trace_win.cc',
|
||||
'<(chromium_root)/base/files/file_path.cc',
|
||||
'<(chromium_root)/base/files/file_path.h',
|
||||
'<(chromium_root)/base/files/file_path_constants.cc',
|
||||
'<(chromium_root)/base/json/json_parser.cc',
|
||||
'<(chromium_root)/base/json/json_parser.h',
|
||||
'<(chromium_root)/base/json/json_reader.cc',
|
||||
'<(chromium_root)/base/json/json_reader.h',
|
||||
'<(chromium_root)/base/json/json_writer.cc',
|
||||
'<(chromium_root)/base/json/json_writer.h',
|
||||
'<(chromium_root)/base/json/string_escape.cc',
|
||||
'<(chromium_root)/base/json/string_escape.h',
|
||||
'<(chromium_root)/base/lazy_instance.cc',
|
||||
'<(chromium_root)/base/lazy_instance.h',
|
||||
'<(chromium_root)/base/logging.cc',
|
||||
'<(chromium_root)/base/logging.h',
|
||||
'<(chromium_root)/base/logging_win.cc',
|
||||
'<(chromium_root)/base/logging_win.h',
|
||||
'<(chromium_root)/base/location.cc',
|
||||
'<(chromium_root)/base/memory/ref_counted.cc',
|
||||
'<(chromium_root)/base/memory/ref_counted.h',
|
||||
'<(chromium_root)/base/memory/singleton.cc',
|
||||
'<(chromium_root)/base/memory/singleton.h',
|
||||
'<(chromium_root)/base/mac/foundation_util.h',
|
||||
'mac/foundation_util.mm',
|
||||
'<(chromium_root)/base/pickle.cc',
|
||||
'<(chromium_root)/base/pickle.h',
|
||||
'<(chromium_root)/base/process.h',
|
||||
'process_util.cc',
|
||||
'<(chromium_root)/base/safe_strerror_posix.cc',
|
||||
'<(chromium_root)/base/safe_strerror_posix.h',
|
||||
'<(chromium_root)/base/strings/string_number_conversions.cc',
|
||||
'<(chromium_root)/base/strings/string_number_conversions.h',
|
||||
'<(chromium_root)/base/strings/string_piece.cc',
|
||||
'<(chromium_root)/base/strings/string_piece.h',
|
||||
'<(chromium_root)/base/strings/string_split.cc',
|
||||
'<(chromium_root)/base/strings/string_split.h',
|
||||
'<(chromium_root)/base/strings/string_util.cc',
|
||||
'<(chromium_root)/base/strings/string_util.h',
|
||||
'<(chromium_root)/base/strings/string_util_constants.cc',
|
||||
'<(chromium_root)/base/strings/string_util_win.h',
|
||||
'<(chromium_root)/base/strings/stringprintf.cc',
|
||||
'<(chromium_root)/base/strings/stringprintf.h',
|
||||
'<(chromium_root)/base/strings/sys_string_conversions.h',
|
||||
'<(chromium_root)/base/strings/sys_string_conversions_mac.mm',
|
||||
'<(chromium_root)/base/strings/sys_string_conversions_posix.cc',
|
||||
'<(chromium_root)/base/strings/sys_string_conversions_win.cc',
|
||||
'<(chromium_root)/base/strings/utf_string_conversion_utils.cc',
|
||||
'<(chromium_root)/base/strings/utf_string_conversion_utils.h',
|
||||
'<(chromium_root)/base/strings/utf_string_conversions.cc',
|
||||
'<(chromium_root)/base/strings/utf_string_conversions.h',
|
||||
'<(chromium_root)/base/synchronization/cancellation_flag.cc',
|
||||
'<(chromium_root)/base/synchronization/cancellation_flag.h',
|
||||
'<(chromium_root)/base/synchronization/condition_variable.h',
|
||||
'<(chromium_root)/base/synchronization/condition_variable_posix.cc',
|
||||
'<(chromium_root)/base/synchronization/condition_variable_win.cc',
|
||||
'<(chromium_root)/base/synchronization/lock.cc',
|
||||
'<(chromium_root)/base/synchronization/lock.h',
|
||||
'<(chromium_root)/base/synchronization/lock_impl.h',
|
||||
'<(chromium_root)/base/synchronization/lock_impl_posix.cc',
|
||||
'<(chromium_root)/base/synchronization/lock_impl_win.cc',
|
||||
'<(chromium_root)/base/synchronization/spin_wait.h',
|
||||
'<(chromium_root)/base/synchronization/waitable_event.h',
|
||||
'<(chromium_root)/base/synchronization/waitable_event_posix.cc',
|
||||
'<(chromium_root)/base/synchronization/waitable_event_watcher.h',
|
||||
'<(chromium_root)/base/synchronization/waitable_event_watcher_posix.cc',
|
||||
'<(chromium_root)/base/synchronization/waitable_event_watcher_win.cc',
|
||||
'<(chromium_root)/base/synchronization/waitable_event_win.cc',
|
||||
'<(chromium_root)/base/threading/platform_thread.h',
|
||||
'<(chromium_root)/base/threading/platform_thread_linux.cc',
|
||||
'<(chromium_root)/base/threading/platform_thread_mac.mm',
|
||||
'<(chromium_root)/base/threading/platform_thread_posix.cc',
|
||||
'<(chromium_root)/base/threading/platform_thread_win.cc',
|
||||
'<(chromium_root)/base/threading/thread_collision_warner.cc',
|
||||
'<(chromium_root)/base/threading/thread_collision_warner.h',
|
||||
'<(chromium_root)/base/threading/thread_id_name_manager.cc',
|
||||
'<(chromium_root)/base/threading/thread_id_name_manager.h',
|
||||
'<(chromium_root)/base/threading/thread_local.h',
|
||||
'<(chromium_root)/base/threading/thread_local_posix.cc',
|
||||
'<(chromium_root)/base/threading/thread_local_storage.cc',
|
||||
'<(chromium_root)/base/threading/thread_local_storage.h',
|
||||
'<(chromium_root)/base/threading/thread_local_storage_posix.cc',
|
||||
'<(chromium_root)/base/threading/thread_local_storage_win.cc',
|
||||
'<(chromium_root)/base/threading/thread_local_win.cc',
|
||||
'<(chromium_root)/base/threading/thread_restrictions.cc',
|
||||
'<(chromium_root)/base/threading/thread_restrictions.h',
|
||||
'<(chromium_root)/base/time/time.cc',
|
||||
'<(chromium_root)/base/time/time.h',
|
||||
'<(chromium_root)/base/time/time_mac.cc',
|
||||
'<(chromium_root)/base/time/time_posix.cc',
|
||||
'<(chromium_root)/base/time/time_win.cc',
|
||||
'<(chromium_root)/base/tracked_objects.cc',
|
||||
'<(chromium_root)/base/tracked_objects.h',
|
||||
'<(chromium_root)/base/values.cc',
|
||||
'<(chromium_root)/base/values.h',
|
||||
'<(chromium_root)/base/vlog.cc',
|
||||
'<(chromium_root)/base/vlog.h',
|
||||
'<(chromium_root)/base/win/registry.cc',
|
||||
'<(chromium_root)/base/win/registry.h',
|
||||
'<(chromium_root)/base/win/scoped_handle.cc',
|
||||
'<(chromium_root)/base/win/scoped_handle.h',
|
||||
'<(chromium_root)/base/win/win_util.cc',
|
||||
'<(chromium_root)/base/win/win_util.h',
|
||||
'<(chromium_root)/base/win/windows_version.cc',
|
||||
'<(chromium_root)/base/profiler/tracked_time.h',
|
||||
'<(chromium_root)/base/profiler/tracked_time.cc',
|
||||
'<(chromium_root)/base/profiler/alternate_timer.h',
|
||||
'<(chromium_root)/base/profiler/alternate_timer.cc',
|
||||
'<(chromium_root)/base/win/windows_version.h',
|
||||
],
|
||||
'include_dirs': [
|
||||
'<(chromium_root)',
|
||||
'<(DEPTH)',
|
||||
],
|
||||
# These warnings are needed for the files in third_party\dmg_fp.
|
||||
'msvs_disabled_warnings': [
|
||||
4244, 4554, 4018, 4102,
|
||||
],
|
||||
'mac_framework_dirs': [
|
||||
'$(SDKROOT)/System/Library/Frameworks/ApplicationServices.framework/Frameworks',
|
||||
],
|
||||
'conditions': [
|
||||
[ 'OS != "linux" and OS != "freebsd" and OS != "openbsd" and OS != "solaris"', {
|
||||
'sources!': [
|
||||
'<(chromium_root)/base/atomicops_internals_x86_gcc.cc',
|
||||
],
|
||||
},],
|
||||
['OS != "win"', {
|
||||
'sources/': [ ['exclude', '^win/'] ],
|
||||
},
|
||||
],
|
||||
[ 'OS == "win"', {
|
||||
'sources!': [
|
||||
'<(chromium_root)/base/strings/string16.cc',
|
||||
],
|
||||
},],
|
||||
],
|
||||
}],
|
||||
],
|
||||
},
|
||||
'targets': [
|
||||
# Older assemblers don't recognize the xgetbv opcode, and require explicit
|
||||
# bytes instead. These can be found by searching the web; example:
|
||||
# http://lxr.free-electrons.com/source/arch/x86/include/asm/xcr.h#L31
|
||||
{
|
||||
'target_name': 'cpu_patched',
|
||||
'type': 'none',
|
||||
'sources': [
|
||||
'<(chromium_root)/base/cpu.cc',
|
||||
'<(chromium_root)/base/cpu_patched.cc',
|
||||
],
|
||||
'actions': [
|
||||
{
|
||||
'action_name': 'Patch cpu.cc',
|
||||
'inputs': [
|
||||
'<(chromium_root)/base/cpu.cc',
|
||||
],
|
||||
'outputs': [
|
||||
'<(chromium_root)/base/cpu_patched.cc',
|
||||
],
|
||||
'action': [
|
||||
'bash', '-c',
|
||||
'sed \'s/"xgetbv"/".byte 0x0f, 0x01, 0xd0"/\' <@(_inputs) > <@(_outputs)'
|
||||
],
|
||||
'message': 'Attempting to generate patched <@(_outputs) from <@(_inputs)',
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
'target_name': 'base',
|
||||
'type': '<(component)',
|
||||
'variables': {
|
||||
'base_target': 1,
|
||||
},
|
||||
'dependencies': [
|
||||
'base_static',
|
||||
'cpu_patched',
|
||||
'<(DEPTH)/third_party/modp_b64/modp_b64.gyp:modp_b64',
|
||||
'<(chromium_root)/base/third_party/dynamic_annotations/dynamic_annotations.gyp:dynamic_annotations',
|
||||
],
|
||||
# TODO(gregoryd): direct_dependent_settings should be shared with the
|
||||
# 64-bit target, but it doesn't work due to a bug in gyp
|
||||
'direct_dependent_settings': {
|
||||
'include_dirs': [
|
||||
'<(chromium_root)',
|
||||
'<(DEPTH)',
|
||||
],
|
||||
},
|
||||
'conditions': [
|
||||
[ 'OS == "linux"', {
|
||||
'cflags': [
|
||||
'-Wno-write-strings',
|
||||
'-Wno-error',
|
||||
],
|
||||
'conditions': [
|
||||
[ 'build_nacl==0', {
|
||||
# We do not need clock_gettime() when building for NaCL newlib.
|
||||
'link_settings': {
|
||||
'libraries': [
|
||||
# We need rt for clock_gettime().
|
||||
'-lrt',
|
||||
],
|
||||
},
|
||||
}],
|
||||
],
|
||||
}],
|
||||
[ 'OS == "mac"', {
|
||||
'link_settings': {
|
||||
'libraries': [
|
||||
'$(SDKROOT)/System/Library/Frameworks/AppKit.framework',
|
||||
'$(SDKROOT)/System/Library/Frameworks/Carbon.framework',
|
||||
'$(SDKROOT)/System/Library/Frameworks/CoreFoundation.framework',
|
||||
'$(SDKROOT)/System/Library/Frameworks/Foundation.framework',
|
||||
'$(SDKROOT)/System/Library/Frameworks/IOKit.framework',
|
||||
'$(SDKROOT)/System/Library/Frameworks/Security.framework',
|
||||
],
|
||||
},
|
||||
},],
|
||||
[ 'build_nacl==1', {
|
||||
'defines': [
|
||||
# A super-hack. prtime.cc (and possibly other sources) call
|
||||
# timegm, which is a non-standard function that's
|
||||
# unavailable when compiling using NaCl newlib. mktime is
|
||||
# essentially a drop-in replacement for timegm, modulo time
|
||||
# zone issues, however NaCL will default to UTC which is the
|
||||
# expected behavior for timegm, so the two should behave
|
||||
# identically.
|
||||
'timegm=mktime',
|
||||
],
|
||||
}],
|
||||
],
|
||||
'sources': [
|
||||
'<(chromium_root)/base/base64.cc',
|
||||
'<(chromium_root)/base/base64.h',
|
||||
'<(chromium_root)/base/md5.cc',
|
||||
'<(chromium_root)/base/md5.h',
|
||||
'<(chromium_root)/base/strings/string16.cc',
|
||||
'<(chromium_root)/base/strings/string16.h',
|
||||
],
|
||||
},
|
||||
],
|
||||
}
|
||||
@@ -0,0 +1,35 @@
|
||||
// Copyright 2013 Google Inc. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
// Chromium's foundation_util.cc pulls a lot of mac related functions into the
|
||||
// base package. We don't need them, so strip down all the code.
|
||||
|
||||
#include "base/mac/foundation_util.h"
|
||||
|
||||
namespace base {
|
||||
namespace mac {
|
||||
|
||||
void* CFTypeRefToNSObjectAutorelease(CFTypeRef cf_object) {
|
||||
// When GC is on, NSMakeCollectable marks cf_object for GC and autorelease
|
||||
// is a no-op.
|
||||
//
|
||||
// In the traditional GC-less environment, NSMakeCollectable is a no-op,
|
||||
// and cf_object is autoreleased, balancing out the caller's ownership claim.
|
||||
//
|
||||
// NSMakeCollectable returns nil when used on a NULL object.
|
||||
return [NSMakeCollectable(cf_object) autorelease];
|
||||
}
|
||||
|
||||
} // namespace mac
|
||||
} // namespace base
|
||||
@@ -0,0 +1,23 @@
|
||||
// Copyright (c) 2011 The Chromium Authors. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style license that can be
|
||||
// found in the LICENSE file.
|
||||
//
|
||||
// NaCL newlib is not compatible with the default
|
||||
// stack_trace_posix.cc. So we provide this stubbed out version for
|
||||
// use when building for NaCL.
|
||||
|
||||
#ifndef __native_client__
|
||||
#error This file should only be used when compiling for Native Client.
|
||||
#endif
|
||||
|
||||
#include "base/debug/stack_trace.h"
|
||||
|
||||
namespace base {
|
||||
namespace debug {
|
||||
|
||||
StackTrace::StackTrace() {}
|
||||
void StackTrace::PrintBacktrace() const {}
|
||||
void StackTrace::OutputToStream(std::ostream* os) const {}
|
||||
|
||||
} // namespace debug
|
||||
} // namespace base
|
||||
@@ -0,0 +1,29 @@
|
||||
// Copyright 2013 Google Inc. All Rights Reserved.
|
||||
//
|
||||
// Licensed under the Apache License, Version 2.0 (the "License");
|
||||
// you may not use this file except in compliance with the License.
|
||||
// You may obtain a copy of the License at
|
||||
//
|
||||
// http://www.apache.org/licenses/LICENSE-2.0
|
||||
//
|
||||
// Unless required by applicable law or agreed to in writing, software
|
||||
// distributed under the License is distributed on an "AS IS" BASIS,
|
||||
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
// See the License for the specific language governing permissions and
|
||||
// limitations under the License.
|
||||
|
||||
// Chromium's process.cc pulls a lot of file related functions into the
|
||||
// base package. We don't need them, so strip down all the code.
|
||||
|
||||
#include "base/logging.h"
|
||||
#include "base/process/process.h"
|
||||
|
||||
namespace base {
|
||||
|
||||
// Returns the id of the current process.
|
||||
ProcessId GetCurrentProcId() {
|
||||
DCHECK(false); // we don't actually expect this to be called.
|
||||
return 0;
|
||||
}
|
||||
|
||||
} // namespace base
|
||||
@@ -0,0 +1,13 @@
|
||||
The following files in this directory were copied from chromium's repository at
|
||||
revision 256281 (https://src.chromium.org/svn/trunk/src/build/?p=256281).
|
||||
|
||||
compiler_version.py (with local bugfix decribed at the top)
|
||||
filename_rules.gypi
|
||||
get_landmines.py
|
||||
grit_action.gypi
|
||||
gyp_chromium (with minor local modifications described at the top)
|
||||
gyp_helper.py
|
||||
java.gypi
|
||||
landmine_utils.py
|
||||
landmines.py
|
||||
release.gypi
|
||||
@@ -0,0 +1,72 @@
|
||||
# Copyright 2009 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
{
|
||||
'targets': [
|
||||
{
|
||||
'target_name': 'All',
|
||||
'type': 'none',
|
||||
'xcode_create_dependents_test_runner': 1,
|
||||
'dependencies': [
|
||||
'mod_pagespeed',
|
||||
'test',
|
||||
'js_minify',
|
||||
'pagespeed_automatic',
|
||||
],},
|
||||
{
|
||||
'target_name': 'mod_pagespeed',
|
||||
'type': 'none',
|
||||
'dependencies': [
|
||||
'../net/instaweb/instaweb.gyp:instaweb_rewriter',
|
||||
'../net/instaweb/instaweb_apr.gyp:*',
|
||||
'../net/instaweb/mod_pagespeed.gyp:mod_pagespeed',
|
||||
'install.gyp:*',
|
||||
],
|
||||
'conditions': [
|
||||
['use_system_apache_dev==0', {
|
||||
'dependencies+': [
|
||||
'../net/instaweb/mod_pagespeed.gyp:mod_pagespeed_ap24',
|
||||
],
|
||||
}],
|
||||
]},
|
||||
{
|
||||
'target_name': 'pagespeed_automatic',
|
||||
'type': 'none',
|
||||
'dependencies': [
|
||||
'../net/instaweb/test.gyp:pagespeed_automatic_test',
|
||||
'../net/instaweb/instaweb.gyp:automatic_util',
|
||||
],},
|
||||
{
|
||||
'target_name': 'test',
|
||||
'type': 'none',
|
||||
'xcode_create_dependents_test_runner': 1,
|
||||
'dependencies': [
|
||||
'../net/instaweb/instaweb.gyp:*',
|
||||
'../net/instaweb/instaweb_core.gyp:*',
|
||||
'../net/instaweb/instaweb_apr.gyp:*',
|
||||
'../net/instaweb/test.gyp:mod_pagespeed_test',
|
||||
'../net/instaweb/test.gyp:mod_pagespeed_speed_test',
|
||||
'install.gyp:*',
|
||||
'<(DEPTH)/pagespeed/kernel.gyp:redis_cache_cluster_setup',
|
||||
]
|
||||
},
|
||||
{
|
||||
'target_name': 'js_minify',
|
||||
'type': 'none',
|
||||
'dependencies': [
|
||||
'../net/instaweb/instaweb.gyp:js_minify',
|
||||
],
|
||||
},
|
||||
],
|
||||
}
|
||||
@@ -0,0 +1,41 @@
|
||||
# Copyright 2013 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
# This file is meant to be included into an action to provide an action that
|
||||
# combines a directory of shared libraries and an incomplete APK into a
|
||||
# standalone APK.
|
||||
#
|
||||
# To use this, create a gyp action with the following form:
|
||||
# {
|
||||
# 'action_name': 'some descriptive action name',
|
||||
# 'variables': {
|
||||
# 'inputs': [ 'input_path1', 'input_path2' ],
|
||||
# 'input_apk_path': '<(unsigned_apk_path)',
|
||||
# 'output_apk_path': '<(unsigned_standalone_apk_path)',
|
||||
# 'libraries_top_dir': '<(libraries_top_dir)',
|
||||
# },
|
||||
# 'includes': [ 'relative/path/to/create_standalone_apk_action.gypi' ],
|
||||
# },
|
||||
|
||||
{
|
||||
'message': 'Creating standalone APK: <(output_apk_path)',
|
||||
'variables': {
|
||||
'inputs': [],
|
||||
},
|
||||
'inputs': [
|
||||
'<(DEPTH)/build/android/gyp/util/build_utils.py',
|
||||
'<(DEPTH)/build/android/gyp/create_standalone_apk.py',
|
||||
'<(input_apk_path)',
|
||||
'>@(inputs)',
|
||||
],
|
||||
'outputs': [
|
||||
'<(output_apk_path)',
|
||||
],
|
||||
'action': [
|
||||
'python', '<(DEPTH)/build/android/gyp/create_standalone_apk.py',
|
||||
'--libraries-top-dir=<(libraries_top_dir)',
|
||||
'--input-apk-path=<(input_apk_path)',
|
||||
'--output-apk-path=<(output_apk_path)',
|
||||
],
|
||||
}
|
||||
@@ -0,0 +1,56 @@
|
||||
# Copyright 2013 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
# This file is meant to be included into an action to provide a rule that dexes
|
||||
# compiled java files. If proguard_enabled == "true" and CONFIGURATION_NAME ==
|
||||
# "Release", then it will dex the proguard_enabled_input_path instead of the
|
||||
# normal dex_input_paths/dex_generated_input_paths.
|
||||
#
|
||||
# To use this, create a gyp target with the following form:
|
||||
# {
|
||||
# 'action_name': 'some name for the action'
|
||||
# 'actions': [
|
||||
# 'variables': {
|
||||
# 'dex_input_paths': [ 'files to dex (when proguard is not used) and add to input paths' ],
|
||||
# 'dex_generated_input_dirs': [ 'dirs that contain generated files to dex' ],
|
||||
#
|
||||
# # For targets that use proguard:
|
||||
# 'proguard_enabled': 'true',
|
||||
# 'proguard_enabled_input_path': 'path to dex when using proguard',
|
||||
# },
|
||||
# 'includes': [ 'relative/path/to/dex_action.gypi' ],
|
||||
# ],
|
||||
# },
|
||||
#
|
||||
|
||||
{
|
||||
'message': 'Creating dex file: <(output_path)',
|
||||
'variables': {
|
||||
'dex_input_paths': [],
|
||||
'dex_generated_input_dirs': [],
|
||||
'proguard_enabled%': 'false',
|
||||
'proguard_enabled_input_path%': '',
|
||||
'dex_no_locals%': 0,
|
||||
},
|
||||
'inputs': [
|
||||
'<(DEPTH)/build/android/gyp/util/build_utils.py',
|
||||
'<(DEPTH)/build/android/gyp/util/md5_check.py',
|
||||
'<(DEPTH)/build/android/gyp/dex.py',
|
||||
'>@(dex_input_paths)',
|
||||
],
|
||||
'outputs': [
|
||||
'<(output_path)',
|
||||
],
|
||||
'action': [
|
||||
'python', '<(DEPTH)/build/android/gyp/dex.py',
|
||||
'--dex-path=<(output_path)',
|
||||
'--android-sdk-tools=<(android_sdk_tools)',
|
||||
'--configuration-name=<(CONFIGURATION_NAME)',
|
||||
'--proguard-enabled=<(proguard_enabled)',
|
||||
'--proguard-enabled-input-path=<(proguard_enabled_input_path)',
|
||||
'--no-locals=<(dex_no_locals)',
|
||||
'>@(dex_input_paths)',
|
||||
'>@(dex_generated_input_dirs)',
|
||||
]
|
||||
}
|
||||
@@ -0,0 +1,40 @@
|
||||
# Copyright 2013 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
# This file is meant to be included into an action to provide an action that
|
||||
# signs and zipaligns an APK.
|
||||
#
|
||||
# To use this, create a gyp action with the following form:
|
||||
# {
|
||||
# 'action_name': 'some descriptive action name',
|
||||
# 'variables': {
|
||||
# 'input_apk_path': 'relative/path/to/input.apk',
|
||||
# 'output_apk_path': 'relative/path/to/output.apk',
|
||||
# },
|
||||
# 'includes': [ '../../build/android/finalize_apk.gypi' ],
|
||||
# },
|
||||
#
|
||||
|
||||
{
|
||||
'message': 'Signing/aligning <(_target_name) APK: <(input_apk_path)',
|
||||
'variables': {
|
||||
'keystore_path%': '<(DEPTH)/build/android/ant/chromium-debug.keystore',
|
||||
},
|
||||
'inputs': [
|
||||
'<(DEPTH)/build/android/gyp/util/build_utils.py',
|
||||
'<(DEPTH)/build/android/gyp/finalize_apk.py',
|
||||
'<(keystore_path)',
|
||||
'<(input_apk_path)',
|
||||
],
|
||||
'outputs': [
|
||||
'<(output_apk_path)',
|
||||
],
|
||||
'action': [
|
||||
'python', '<(DEPTH)/build/android/gyp/finalize_apk.py',
|
||||
'--android-sdk-root=<(android_sdk_root)',
|
||||
'--unsigned-apk-path=<(input_apk_path)',
|
||||
'--final-apk-path=<(output_apk_path)',
|
||||
'--keystore-path=<(keystore_path)',
|
||||
],
|
||||
}
|
||||
@@ -0,0 +1,53 @@
|
||||
# Copyright 2013 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
# This file is meant to be included into an action to provide a rule that
|
||||
# instruments either java class files, or jars.
|
||||
|
||||
{
|
||||
'variables': {
|
||||
'instr_type%': 'jar',
|
||||
'input_path%': '',
|
||||
'output_path%': '',
|
||||
'stamp_path%': '',
|
||||
'extra_instr_args': [
|
||||
'--coverage-file=<(_target_name).em',
|
||||
'--sources-file=<(_target_name)_sources.txt',
|
||||
],
|
||||
'emma_jar': '<(android_sdk_root)/tools/lib/emma.jar',
|
||||
'conditions': [
|
||||
['emma_instrument != 0', {
|
||||
'extra_instr_args': [
|
||||
'--sources=<(java_in_dir)/src >(additional_src_dirs) >(generated_src_dirs)',
|
||||
'--src-root=<(DEPTH)',
|
||||
'--emma-jar=<(emma_jar)',
|
||||
'--filter-string=<(emma_filter)',
|
||||
],
|
||||
'conditions': [
|
||||
['instr_type == "jar"', {
|
||||
'instr_action': 'instrument_jar',
|
||||
}, {
|
||||
'instr_action': 'instrument_classes',
|
||||
}]
|
||||
],
|
||||
}, {
|
||||
'instr_action': 'copy',
|
||||
'extra_instr_args': [],
|
||||
}]
|
||||
]
|
||||
},
|
||||
'inputs': [
|
||||
'<(DEPTH)/build/android/gyp/emma_instr.py',
|
||||
'<(DEPTH)/build/android/gyp/util/build_utils.py',
|
||||
'<(DEPTH)/build/android/pylib/utils/command_option_parser.py',
|
||||
],
|
||||
'action': [
|
||||
'python', '<(DEPTH)/build/android/gyp/emma_instr.py',
|
||||
'<(instr_action)',
|
||||
'--input-path=<(input_path)',
|
||||
'--output-path=<(output_path)',
|
||||
'--stamp=<(stamp_path)',
|
||||
'<@(extra_instr_args)',
|
||||
]
|
||||
}
|
||||
@@ -0,0 +1,39 @@
|
||||
# Copyright 2013 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
# This file is meant to be included into an action to provide a rule to
|
||||
# run lint on java/class files.
|
||||
|
||||
{
|
||||
'action_name': 'lint_<(_target_name)',
|
||||
'message': 'Linting <(_target_name)',
|
||||
'variables': {
|
||||
'conditions': [
|
||||
['chromium_code != 0 and android_lint != 0 and never_lint == 0', {
|
||||
'is_enabled': '--enable',
|
||||
}, {
|
||||
'is_enabled': '',
|
||||
}]
|
||||
]
|
||||
},
|
||||
'inputs': [
|
||||
'<(DEPTH)/build/android/gyp/util/build_utils.py',
|
||||
'<(DEPTH)/build/android/gyp/lint.py',
|
||||
'<(DEPTH)/build/android/lint/suppressions.xml',
|
||||
'<(DEPTH)/build/android/AndroidManifest.xml',
|
||||
],
|
||||
'action': [
|
||||
'python', '<(DEPTH)/build/android/gyp/lint.py',
|
||||
'--lint-path=<(android_sdk_root)/tools/lint',
|
||||
'--config-path=<(DEPTH)/build/android/lint/suppressions.xml',
|
||||
'--processed-config-path=<(config_path)',
|
||||
'--manifest-path=<(DEPTH)/build/android/AndroidManifest.xml',
|
||||
'--result-path=<(result_path)',
|
||||
'--product-dir=<(PRODUCT_DIR)',
|
||||
'--src-dirs=>(src_dirs)',
|
||||
'--classes-dir=<(classes_dir)',
|
||||
'--stamp=<(stamp_path)',
|
||||
'<(is_enabled)',
|
||||
],
|
||||
}
|
||||
@@ -0,0 +1,85 @@
|
||||
# Copyright (c) 2009 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
{
|
||||
'variables': {
|
||||
'version_py_path': 'version.py',
|
||||
'instaweb_path': '<(DEPTH)/net/instaweb',
|
||||
'version_path': '<(instaweb_path)/public/VERSION',
|
||||
'version_h_in_path': '<(instaweb_path)/public/version.h.in',
|
||||
'public_path' : 'net/instaweb/public',
|
||||
'version_h_path': '<(SHARED_INTERMEDIATE_DIR)/<(public_path)/version.h',
|
||||
'lastchange_out_path': '<(SHARED_INTERMEDIATE_DIR)/build/LASTCHANGE',
|
||||
},
|
||||
'targets': [
|
||||
{
|
||||
'target_name': 'lastchange',
|
||||
'type': 'none',
|
||||
'variables': {
|
||||
'default_lastchange_path': '../LASTCHANGE.in',
|
||||
},
|
||||
'actions': [
|
||||
{
|
||||
'action_name': 'lastchange',
|
||||
'inputs': [
|
||||
# Note: <(default_lastchange_path) is optional,
|
||||
# so it doesn't show up in inputs.
|
||||
'<(DEPTH)/build/lastchange.sh',
|
||||
],
|
||||
'outputs': [
|
||||
'<(lastchange_out_path)',
|
||||
],
|
||||
'action': [
|
||||
'/bin/sh', '<@(_inputs)',
|
||||
'<(DEPTH)',
|
||||
'-o', '<(lastchange_out_path)',
|
||||
'-d', '<(default_lastchange_path)',
|
||||
],
|
||||
'message': 'Extracting last change to <(lastchange_out_path)',
|
||||
'process_outputs_as_sources': '1',
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
'target_name': 'mod_pagespeed_version_header',
|
||||
'type': 'none',
|
||||
'dependencies': [
|
||||
'lastchange',
|
||||
],
|
||||
'actions': [
|
||||
{
|
||||
'action_name': 'version_header',
|
||||
'inputs': [
|
||||
'<(version_path)',
|
||||
'<(lastchange_out_path)',
|
||||
'<(version_h_in_path)',
|
||||
],
|
||||
'outputs': [
|
||||
'<(version_h_path)',
|
||||
],
|
||||
'action': [
|
||||
'python',
|
||||
'<(version_py_path)',
|
||||
'-f', '<(version_path)',
|
||||
'-f', '<(lastchange_out_path)',
|
||||
'<(version_h_in_path)',
|
||||
'<@(_outputs)',
|
||||
],
|
||||
'message': 'Generating version header file: <@(_outputs)',
|
||||
},
|
||||
],
|
||||
'direct_dependent_settings': {
|
||||
'include_dirs': [
|
||||
'<(SHARED_INTERMEDIATE_DIR)',
|
||||
],
|
||||
},
|
||||
},
|
||||
]
|
||||
}
|
||||
|
||||
# Local Variables:
|
||||
# tab-width:2
|
||||
# indent-tabs-mode:nil
|
||||
# End:
|
||||
# vim: set expandtab tabstop=2 shiftwidth=2:
|
||||
Executable
+57
@@ -0,0 +1,57 @@
|
||||
#!/usr/bin/env python
|
||||
# Copyright (c) 2012 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
#
|
||||
|
||||
"""Compiler version checking tool for clang.
|
||||
|
||||
(Based on corresponding tool for gcc in Chromium build system).
|
||||
|
||||
Prints X*100 + Y if $CXX is pointing to clang X.Y.*. Prints 0 otherwise.
|
||||
Note that this output convention is different from compiler_version.py's. This
|
||||
also never returns a failing status, since we want to run this even on systems
|
||||
without clang, and gyp will complain on a non-successful status.
|
||||
"""
|
||||
|
||||
import os
|
||||
import re
|
||||
import subprocess
|
||||
import sys
|
||||
|
||||
|
||||
def GetVersion(compiler):
|
||||
try:
|
||||
compiler = compiler + " --version"
|
||||
pipe = subprocess.Popen(compiler, shell=True,
|
||||
stdout=subprocess.PIPE, stderr=subprocess.PIPE)
|
||||
output, error = pipe.communicate()
|
||||
if pipe.returncode:
|
||||
raise subprocess.CalledProcessError(pipe.returncode, compiler)
|
||||
|
||||
result = re.search(r"clang version (\d+)\.?(\d+)?", output)
|
||||
if result is None:
|
||||
return "0"
|
||||
minor_version = result.group(2)
|
||||
if minor_version is None:
|
||||
minor_version = "0"
|
||||
return str(int(result.group(1)) * 100 + int(minor_version))
|
||||
except Exception, e:
|
||||
if error:
|
||||
sys.stderr.write(error)
|
||||
print >> sys.stderr, "clang_version.py failed to execute:", compiler
|
||||
print >> sys.stderr, e
|
||||
return "0"
|
||||
|
||||
|
||||
def main():
|
||||
# Check if CXX environment variable exists, and if it does use that compiler.
|
||||
cxx = os.getenv("CXX", None)
|
||||
if cxx:
|
||||
print GetVersion(cxx)
|
||||
else:
|
||||
print "0"
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
sys.exit(0)
|
||||
@@ -0,0 +1,178 @@
|
||||
# Copyright 2009 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
{
|
||||
'variables': {
|
||||
# Make sure we link statically so everything gets linked into a
|
||||
# single shared object.
|
||||
'library': 'static_library',
|
||||
|
||||
# We're building a shared library, so everything needs to be built
|
||||
# with Position-Independent Code.
|
||||
'linux_fpic': 1,
|
||||
|
||||
'instaweb_src_root': 'net/instaweb',
|
||||
|
||||
# Define the overridable use_system_libs variable in its own
|
||||
# nested block, so it's available for use in the conditions block
|
||||
# below.
|
||||
'variables': {
|
||||
'use_system_libs%': 0,
|
||||
},
|
||||
|
||||
# Which versions development is usually done with. These version will
|
||||
# get -Werror
|
||||
'gcc_devel_version%': '46',
|
||||
'gcc_devel_version2%': '48',
|
||||
|
||||
# We need inter-process mutexes to support POSIX shared memory, and they're
|
||||
# unfortunately not supported on some common systems.
|
||||
'support_posix_shared_mem%': 0,
|
||||
|
||||
# Detect clang being configured via CXX envvar, which is the easiest
|
||||
# way for our users to change the compiler (since gclient gets in
|
||||
# the way of tweaking gyp flags directly).
|
||||
'clang_version':
|
||||
'<!(python <(DEPTH)/build/clang_version.py)',
|
||||
|
||||
'conditions': [
|
||||
# TODO(morlovich): AIX, Solaris, FreeBSD10?
|
||||
['OS == "linux"', {
|
||||
'support_posix_shared_mem': 1
|
||||
}],
|
||||
['use_system_libs==1', {
|
||||
'use_system_apache_dev': 1,
|
||||
'use_system_icu': 1,
|
||||
'use_system_libjpeg': 1,
|
||||
'use_system_libpng': 1,
|
||||
'use_system_opencv': 1,
|
||||
'use_system_openssl': 1,
|
||||
'use_system_zlib': 1,
|
||||
},{
|
||||
'use_system_apache_dev%': 0,
|
||||
}],
|
||||
],
|
||||
},
|
||||
'includes': [
|
||||
# Import base Chromium build system, and pagespeed customizations of it.
|
||||
'../third_party/chromium/src/build/common.gypi',
|
||||
'pagespeed_overrides.gypi',
|
||||
],
|
||||
'target_defaults': {
|
||||
'variables': {
|
||||
# Make this available here as well.
|
||||
'use_system_libs%': 0,
|
||||
},
|
||||
'conditions': [
|
||||
['support_posix_shared_mem == 1', {
|
||||
'defines': [ 'PAGESPEED_SUPPORT_POSIX_SHARED_MEM', ],
|
||||
}],
|
||||
['OS == "linux"', {
|
||||
# Disable -Werror when not using the version of gcc that development
|
||||
# is generally done with, to avoid breaking things for users with
|
||||
# something older or newer (which produces different warnings).
|
||||
'conditions': [
|
||||
['<(gcc_version) != <(gcc_devel_version) and '
|
||||
'<(gcc_version) != <(gcc_devel_version2)', {
|
||||
'cflags!': ['-Werror']
|
||||
}],
|
||||
['<(gcc_version) < 48 and (clang_version == 0)', {
|
||||
'cflags+': '<!(echo gcc \< 4.8 is too old and no longer supported; false)'
|
||||
}]
|
||||
],
|
||||
'cflags': [
|
||||
# Our dependency on OpenCV need us to turn on exceptions.
|
||||
'-fexceptions',
|
||||
# Now we are using exceptions. -fno-asynchronous-unwind-tables is
|
||||
# set in libpagespeed's common.gypi. Now enable it.
|
||||
'-fasynchronous-unwind-tables',
|
||||
# We'd like to add '-Wtype-limits', but this does not work on
|
||||
# earlier versions of g++ on supported operating systems.
|
||||
#
|
||||
# Use -DFORTIFY_SOURCE to add extra checks to functions like printf,
|
||||
# and bounds checking to copies.
|
||||
'-D_FORTIFY_SOURCE=2',
|
||||
],
|
||||
'cflags_cc!': [
|
||||
# Newer Chromium build adds -Wsign-compare which we have some
|
||||
# difficulty with. Remove it for now.
|
||||
'-Wsign-compare',
|
||||
'-fno-rtti', # Same reason as using -frtti below.
|
||||
],
|
||||
'cflags_cc': [
|
||||
'-frtti', # Hardy's g++ 4.2 <trl/function> uses typeid
|
||||
'-D_FORTIFY_SOURCE=2',
|
||||
],
|
||||
'defines!': [
|
||||
# testing/gtest.gyp defines GTEST_HAS_RTTI=0 for itself and all deps.
|
||||
# This breaks when we turn rtti on, so must be removed.
|
||||
'GTEST_HAS_RTTI=0',
|
||||
# third_party/protobuf/protobuf.gyp defines GOOGLE_PROTOBUF_NO_RTTI
|
||||
# for itself and all deps. I assume this is just a ticking time bomb
|
||||
# like GTEST_HAS_RTTI=0 was, so remove it as well.
|
||||
'GOOGLE_PROTOBUF_NO_RTTI',
|
||||
],
|
||||
'defines': [
|
||||
'GTEST_HAS_RTTI=1', # gtest requires this set to indicate RTTI on.
|
||||
],
|
||||
# Disable -z,defs in linker.
|
||||
# This causes mod_pagespeed.so to fail because it doesn't link apache
|
||||
# libraries.
|
||||
'ldflags!': [
|
||||
'-Wl,-z,defs',
|
||||
],
|
||||
}],
|
||||
['OS == "mac"', {
|
||||
'xcode_settings':{
|
||||
'GCC_ENABLE_CPP_EXCEPTIONS': 'YES', # -fexceptions
|
||||
'GCC_ENABLE_CPP_RTTI': 'YES', # -frtti
|
||||
|
||||
# The Google CSS parser escapes from functions without
|
||||
# returning anything. Only with flow analysis that is,
|
||||
# evidently, beyond the scope of the g++ configuration in
|
||||
# MacOS, do we see those paths cannot be reached.
|
||||
'OTHER_CFLAGS': ['-funsigned-char', '-Wno-error'],
|
||||
},
|
||||
}],
|
||||
['use_system_libs == 0', {
|
||||
'ldflags+': [
|
||||
'-static-libstdc++',
|
||||
'-static-libgcc',
|
||||
]
|
||||
}],
|
||||
],
|
||||
|
||||
'defines': [ # See https://gcc.gnu.org/onlinedocs/libstdc++/manual/using_dual_abi.html
|
||||
'_GLIBCXX_USE_CXX11_ABI=0' ],
|
||||
|
||||
'cflags_cc+': [
|
||||
'-std=gnu++0x'
|
||||
],
|
||||
|
||||
# Permit building us with coverage information
|
||||
'configurations': {
|
||||
'Debug_Coverage': {
|
||||
'inherit_from': ['Debug'],
|
||||
'cflags': [
|
||||
'-ftest-coverage',
|
||||
'-fprofile-arcs',
|
||||
],
|
||||
'ldflags': [
|
||||
# takes care of -lgcov for us, but can be in a build configuration
|
||||
'-ftest-coverage -fprofile-arcs',
|
||||
],
|
||||
},
|
||||
},
|
||||
},
|
||||
}
|
||||
Executable
+61
@@ -0,0 +1,61 @@
|
||||
#!/usr/bin/env python
|
||||
# Copyright (c) 2012 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
#
|
||||
# This version contains a bugfix for the compiler returning a single digit
|
||||
# version number, as is the case for gcc 5.
|
||||
|
||||
"""Compiler version checking tool for gcc
|
||||
|
||||
Print gcc version as XY if you are running gcc X.Y.*.
|
||||
This is used to tweak build flags for gcc 4.4.
|
||||
"""
|
||||
|
||||
import os
|
||||
import re
|
||||
import subprocess
|
||||
import sys
|
||||
|
||||
def GetVersion(compiler):
|
||||
try:
|
||||
# Note that compiler could be something tricky like "distcc g++".
|
||||
compiler = compiler + " -dumpversion"
|
||||
pipe = subprocess.Popen(compiler, shell=True,
|
||||
stdout=subprocess.PIPE, stderr=subprocess.PIPE)
|
||||
gcc_output, gcc_error = pipe.communicate()
|
||||
if pipe.returncode:
|
||||
raise subprocess.CalledProcessError(pipe.returncode, compiler)
|
||||
|
||||
result = re.match(r"(\d+)\.?(\d+)?", gcc_output)
|
||||
minor_version = result.group(2)
|
||||
if minor_version is None:
|
||||
minor_version = "0"
|
||||
return result.group(1) + minor_version
|
||||
except Exception, e:
|
||||
if gcc_error:
|
||||
sys.stderr.write(gcc_error)
|
||||
print >> sys.stderr, "compiler_version.py failed to execute:", compiler
|
||||
print >> sys.stderr, e
|
||||
return ""
|
||||
|
||||
def main():
|
||||
# Check if CXX environment variable exists and
|
||||
# if it does use that compiler.
|
||||
cxx = os.getenv("CXX", None)
|
||||
if cxx:
|
||||
cxxversion = GetVersion(cxx)
|
||||
if cxxversion != "":
|
||||
print cxxversion
|
||||
return 0
|
||||
else:
|
||||
# Otherwise we check the g++ version.
|
||||
gccversion = GetVersion("g++")
|
||||
if gccversion != "":
|
||||
print gccversion
|
||||
return 0
|
||||
|
||||
return 1
|
||||
|
||||
if __name__ == "__main__":
|
||||
sys.exit(main())
|
||||
Executable
+15
@@ -0,0 +1,15 @@
|
||||
#!/usr/bin/env python
|
||||
# Copyright (c) 2011 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
"""Writes True if the argument is a directory."""
|
||||
|
||||
import os.path
|
||||
import sys
|
||||
|
||||
def main():
|
||||
sys.stdout.write(str(os.path.isdir(sys.argv[1])))
|
||||
return 0
|
||||
|
||||
if __name__ == '__main__':
|
||||
sys.exit(main())
|
||||
@@ -0,0 +1,18 @@
|
||||
# Copyright 2009 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
# Chromium expects this file to be here, but for our (Page Speed) purposes, it
|
||||
# doesn't need to actually do anything.
|
||||
|
||||
{}
|
||||
@@ -0,0 +1,125 @@
|
||||
# Copyright (c) 2012 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
# This gypi file defines the patterns used for determining whether a
|
||||
# file is excluded from the build on a given platform. It is
|
||||
# included by common.gypi for chromium_code.
|
||||
|
||||
{
|
||||
'target_conditions': [
|
||||
['OS!="win" or >(nacl_untrusted_build)==1', {
|
||||
'sources/': [ ['exclude', '_win(_browsertest|_unittest)?\\.(h|cc)$'],
|
||||
['exclude', '(^|/)win/'],
|
||||
['exclude', '(^|/)win_[^/]*\\.(h|cc)$'] ],
|
||||
}],
|
||||
['OS!="mac" or >(nacl_untrusted_build)==1', {
|
||||
'sources/': [ ['exclude', '_(cocoa|mac)(_unittest)?\\.(h|cc|mm?)$'],
|
||||
['exclude', '(^|/)(cocoa|mac)/'] ],
|
||||
}],
|
||||
['OS!="ios" or >(nacl_untrusted_build)==1', {
|
||||
'sources/': [ ['exclude', '_ios(_unittest)?\\.(h|cc|mm?)$'],
|
||||
['exclude', '(^|/)ios/'] ],
|
||||
}],
|
||||
['(OS!="mac" and OS!="ios") or >(nacl_untrusted_build)==1', {
|
||||
'sources/': [ ['exclude', '\\.mm?$' ] ],
|
||||
}],
|
||||
# Do not exclude the linux files on *BSD since most of them can be
|
||||
# shared at this point.
|
||||
# In case a file is not needed, it is going to be excluded later on.
|
||||
# TODO(evan): the above is not correct; we shouldn't build _linux
|
||||
# files on non-linux.
|
||||
['OS!="linux" and OS!="openbsd" and OS!="freebsd" or >(nacl_untrusted_build)==1', {
|
||||
'sources/': [
|
||||
['exclude', '_linux(_unittest)?\\.(h|cc)$'],
|
||||
['exclude', '(^|/)linux/'],
|
||||
],
|
||||
}],
|
||||
['OS!="android" or _toolset=="host"', {
|
||||
'sources/': [
|
||||
['exclude', '_android(_unittest)?\\.cc$'],
|
||||
['exclude', '(^|/)android/'],
|
||||
],
|
||||
}],
|
||||
['OS=="win" and >(nacl_untrusted_build)==0', {
|
||||
'sources/': [
|
||||
['exclude', '_posix(_unittest)?\\.(h|cc)$'],
|
||||
['exclude', '(^|/)posix/'],
|
||||
],
|
||||
}],
|
||||
['<(chromeos)!=1 or >(nacl_untrusted_build)==1', {
|
||||
'sources/': [
|
||||
['exclude', '_chromeos(_unittest)?\\.(h|cc)$'],
|
||||
['exclude', '(^|/)chromeos/'],
|
||||
],
|
||||
}],
|
||||
['>(nacl_untrusted_build)==0', {
|
||||
'sources/': [
|
||||
['exclude', '_nacl(_unittest)?\\.(h|cc)$'],
|
||||
],
|
||||
}],
|
||||
['OS!="linux" and OS!="openbsd" and OS!="freebsd" or >(nacl_untrusted_build)==1', {
|
||||
'sources/': [
|
||||
['exclude', '_xdg(_unittest)?\\.(h|cc)$'],
|
||||
],
|
||||
}],
|
||||
['<(use_x11)!=1 or >(nacl_untrusted_build)==1', {
|
||||
'sources/': [
|
||||
['exclude', '_(x|x11)(_unittest)?\\.(h|cc)$'],
|
||||
['exclude', '(^|/)x11_[^/]*\\.(h|cc)$'],
|
||||
['exclude', '(^|/)x11/'],
|
||||
['exclude', '(^|/)x/'],
|
||||
],
|
||||
}],
|
||||
['<(toolkit_uses_gtk)!=1 or >(nacl_untrusted_build)==1', {
|
||||
'sources/': [
|
||||
['exclude', '_gtk(_browsertest|_unittest)?\\.(h|cc)$'],
|
||||
['exclude', '(^|/)gtk/'],
|
||||
['exclude', '(^|/)gtk_[^/]*\\.(h|cc)$'],
|
||||
],
|
||||
}],
|
||||
['<(toolkit_views)==0 or >(nacl_untrusted_build)==1', {
|
||||
'sources/': [ ['exclude', '_views\\.(h|cc)$'] ]
|
||||
}],
|
||||
['<(use_aura)==0 or >(nacl_untrusted_build)==1', {
|
||||
'sources/': [ ['exclude', '_aura(_browsertest|_unittest)?\\.(h|cc)$'],
|
||||
['exclude', '(^|/)aura/'],
|
||||
]
|
||||
}],
|
||||
['<(use_aura)==0 or <(use_x11)==0 or >(nacl_untrusted_build)==1', {
|
||||
'sources/': [ ['exclude', '_aurax11(_browsertest|_unittest)?\\.(h|cc)$'] ]
|
||||
}],
|
||||
['<(use_aura)==0 or OS!="win" or >(nacl_untrusted_build)==1', {
|
||||
'sources/': [ ['exclude', '_aurawin\\.(h|cc)$'] ]
|
||||
}],
|
||||
['<(use_aura)==0 or OS!="linux" or >(nacl_untrusted_build)==1', {
|
||||
'sources/': [ ['exclude', '_auralinux\\.(h|cc)$'] ]
|
||||
}],
|
||||
['<(use_ash)==0 or >(nacl_untrusted_build)==1', {
|
||||
'sources/': [ ['exclude', '_ash(_browsertest|_unittest)?\\.(h|cc)$'],
|
||||
['exclude', '(^|/)ash/'],
|
||||
]
|
||||
}],
|
||||
['<(use_ash)==0 or OS!="win" or >(nacl_untrusted_build)==1', {
|
||||
'sources/': [ ['exclude', '_ashwin\\.(h|cc)$'] ]
|
||||
}],
|
||||
['<(use_ozone)==0 or >(nacl_untrusted_build)==1', {
|
||||
'sources/': [ ['exclude', '_ozone(_browsertest|_unittest)?\\.(h|cc)$'],
|
||||
['exclude', '(^|/)ozone/'],
|
||||
]
|
||||
}],
|
||||
['<(use_ozone_evdev)==0 or >(nacl_untrusted_build)==1', {
|
||||
'sources/': [ ['exclude', '_evdev(_browsertest|_unittest)?\\.(h|cc)$'],
|
||||
['exclude', '(^|/)evdev/'],
|
||||
]
|
||||
}],
|
||||
['<(ozone_platform_dri)==0 or >(nacl_untrusted_build)==1', {
|
||||
'sources/': [ ['exclude', '_dri(_browsertest|_unittest)?\\.(h|cc)$'],
|
||||
['exclude', '(^|/)dri/'],
|
||||
]
|
||||
}],
|
||||
['<(use_pango)==0', {
|
||||
'sources/': [ ['exclude', '(^|_)pango(_util|_browsertest|_unittest)?\\.(h|cc)$'], ],
|
||||
}],
|
||||
]
|
||||
}
|
||||
Executable
+20
@@ -0,0 +1,20 @@
|
||||
#!/bin/bash
|
||||
|
||||
set -e
|
||||
set -u
|
||||
|
||||
if [ $# -lt 3 ];then
|
||||
echo "Usage: $(basename $0) <proto_in> <proto_out> <protoc_path>"\
|
||||
"[<protoc_opts> ...]" >&2
|
||||
exit 1
|
||||
fi
|
||||
|
||||
proto_in=$1
|
||||
proto_out=$2
|
||||
protoc=$3
|
||||
shift 3
|
||||
|
||||
sed -e 's!"third_party/pagespeed/!"pagespeed/!; s!// \[opensource\] !!' \
|
||||
< "$proto_in" > "$proto_out"
|
||||
|
||||
exec "$protoc" "$@" "$proto_out"
|
||||
Executable
+71
@@ -0,0 +1,71 @@
|
||||
#!/usr/bin/env python
|
||||
# Copyright 2013 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
"""
|
||||
This file emits the list of reasons why a particular build needs to be clobbered
|
||||
(or a list of 'landmines').
|
||||
"""
|
||||
|
||||
import optparse
|
||||
import sys
|
||||
|
||||
import landmine_utils
|
||||
|
||||
|
||||
builder = landmine_utils.builder
|
||||
distributor = landmine_utils.distributor
|
||||
gyp_defines = landmine_utils.gyp_defines
|
||||
gyp_msvs_version = landmine_utils.gyp_msvs_version
|
||||
platform = landmine_utils.platform
|
||||
|
||||
|
||||
def print_landmines(target):
|
||||
"""
|
||||
ALL LANDMINES ARE EMITTED FROM HERE.
|
||||
target can be one of {'Release', 'Debug', 'Debug_x64', 'Release_x64'}.
|
||||
"""
|
||||
if (distributor() == 'goma' and platform() == 'win32' and
|
||||
builder() == 'ninja'):
|
||||
print 'Need to clobber winja goma due to backend cwd cache fix.'
|
||||
if platform() == 'android':
|
||||
print 'Clobber: Autogen java file needs to be removed (issue 159173002)'
|
||||
if platform() == 'win' and builder() == 'ninja':
|
||||
print 'Compile on cc_unittests fails due to symbols removed in r185063.'
|
||||
if platform() == 'linux' and builder() == 'ninja':
|
||||
print 'Builders switching from make to ninja will clobber on this.'
|
||||
if platform() == 'mac':
|
||||
print 'Switching from bundle to unbundled dylib (issue 14743002).'
|
||||
if platform() in ('win', 'mac'):
|
||||
print ('Improper dependency for create_nmf.py broke in r240802, '
|
||||
'fixed in r240860.')
|
||||
if (platform() == 'win' and builder() == 'ninja' and
|
||||
gyp_msvs_version() == '2012' and
|
||||
gyp_defines().get('target_arch') == 'x64' and
|
||||
gyp_defines().get('dcheck_always_on') == '1'):
|
||||
print "Switched win x64 trybots from VS2010 to VS2012."
|
||||
if (platform() == 'win' and builder() == 'ninja' and
|
||||
gyp_msvs_version().startswith('2013')):
|
||||
print "Switched win from VS2010 to VS2013."
|
||||
print 'Need to clobber everything due to an IDL change in r154579 (blink)'
|
||||
if (platform() != 'ios'):
|
||||
print 'Clobber to get rid of obselete test plugin after r248358'
|
||||
|
||||
|
||||
def main():
|
||||
parser = optparse.OptionParser()
|
||||
parser.add_option('-t', '--target',
|
||||
help=='Target for which the landmines have to be emitted')
|
||||
|
||||
options, args = parser.parse_args()
|
||||
|
||||
if args:
|
||||
parser.error('Unknown arguments %s' % args)
|
||||
|
||||
print_landmines(options.target)
|
||||
return 0
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
sys.exit(main())
|
||||
@@ -0,0 +1,42 @@
|
||||
# Copyright (c) 2011 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
# This file is meant to be included into an action to invoke grit in a
|
||||
# consistent manner. To use this the following variables need to be
|
||||
# defined:
|
||||
# grit_grd_file: string: grd file path
|
||||
# grit_out_dir: string: the output directory path
|
||||
|
||||
# It would be really nice to do this with a rule instead of actions, but it
|
||||
# would need to determine inputs and outputs via grit_info on a per-file
|
||||
# basis. GYP rules don’t currently support that. They could be extended to
|
||||
# do this, but then every generator would need to be updated to handle this.
|
||||
|
||||
{
|
||||
'variables': {
|
||||
'grit_cmd': ['python', '<(DEPTH)/tools/grit/grit.py'],
|
||||
'grit_resource_ids%': '<(DEPTH)/tools/gritsettings/resource_ids',
|
||||
# This makes it possible to add more defines in specific targets,
|
||||
# instead of build/common.gypi .
|
||||
'grit_additional_defines%': [],
|
||||
'grit_rc_header_format%': [],
|
||||
},
|
||||
'inputs': [
|
||||
'<!@pymod_do_main(grit_info <@(grit_defines) <@(grit_additional_defines) '
|
||||
'--inputs <(grit_grd_file) -f "<(grit_resource_ids)")',
|
||||
],
|
||||
'outputs': [
|
||||
'<!@pymod_do_main(grit_info <@(grit_defines) <@(grit_additional_defines) '
|
||||
'--outputs \'<(grit_out_dir)\' '
|
||||
'<(grit_grd_file) -f "<(grit_resource_ids)")',
|
||||
],
|
||||
'action': ['<@(grit_cmd)',
|
||||
'-i', '<(grit_grd_file)', 'build',
|
||||
'-f', '<(grit_resource_ids)',
|
||||
'-o', '<(grit_out_dir)',
|
||||
'<@(grit_defines)',
|
||||
'<@(grit_additional_defines)',
|
||||
'<@(grit_rc_header_format)'],
|
||||
'message': 'Generating resources from <(grit_grd_file)',
|
||||
}
|
||||
Executable
+572
@@ -0,0 +1,572 @@
|
||||
#!/usr/bin/env python
|
||||
|
||||
# Copyright (c) 2012 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
# This script is wrapper for Chromium that adds some support for how GYP
|
||||
# is invoked by Chromium beyond what can be done in the gclient hooks.
|
||||
|
||||
# This was copied from the chromium repository at revision 256281. The only
|
||||
# change was adding back support and making default Makefile generation, instead
|
||||
# of ninja support. This was removed as discussed in crbug.com/348686.
|
||||
|
||||
import glob
|
||||
import gyp_helper
|
||||
import json
|
||||
import os
|
||||
import pipes
|
||||
import shlex
|
||||
import shutil
|
||||
import subprocess
|
||||
import string
|
||||
import sys
|
||||
import tempfile
|
||||
|
||||
script_dir = os.path.dirname(os.path.realpath(__file__))
|
||||
chrome_src = os.path.abspath(os.path.join(script_dir, os.pardir))
|
||||
|
||||
sys.path.insert(0, os.path.join(chrome_src, 'tools', 'gyp', 'pylib'))
|
||||
import gyp
|
||||
|
||||
# Assume this file is in a one-level-deep subdirectory of the source root.
|
||||
SRC_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
|
||||
|
||||
# Add paths so that pymod_do_main(...) can import files.
|
||||
sys.path.insert(1, os.path.join(chrome_src, 'tools'))
|
||||
sys.path.insert(1, os.path.join(chrome_src, 'tools', 'generate_shim_headers'))
|
||||
sys.path.insert(1, os.path.join(chrome_src, 'tools', 'grit'))
|
||||
sys.path.insert(1, os.path.join(chrome_src, 'chrome', 'tools', 'build'))
|
||||
sys.path.insert(1, os.path.join(chrome_src, 'native_client', 'build'))
|
||||
sys.path.insert(1, os.path.join(chrome_src, 'native_client_sdk', 'src',
|
||||
'build_tools'))
|
||||
sys.path.insert(1, os.path.join(chrome_src, 'remoting', 'tools', 'build'))
|
||||
sys.path.insert(1, os.path.join(chrome_src, 'third_party', 'liblouis'))
|
||||
sys.path.insert(1, os.path.join(chrome_src, 'third_party', 'WebKit',
|
||||
'Source', 'build', 'scripts'))
|
||||
|
||||
# On Windows, Psyco shortens warm runs of build/gyp_chromium by about
|
||||
# 20 seconds on a z600 machine with 12 GB of RAM, from 90 down to 70
|
||||
# seconds. Conversely, memory usage of build/gyp_chromium with Psyco
|
||||
# maxes out at about 158 MB vs. 132 MB without it.
|
||||
#
|
||||
# Psyco uses native libraries, so we need to load a different
|
||||
# installation depending on which OS we are running under. It has not
|
||||
# been tested whether using Psyco on our Mac and Linux builds is worth
|
||||
# it (the GYP running time is a lot shorter, so the JIT startup cost
|
||||
# may not be worth it).
|
||||
if sys.platform == 'win32':
|
||||
try:
|
||||
sys.path.insert(0, os.path.join(chrome_src, 'third_party', 'psyco_win32'))
|
||||
import psyco
|
||||
except:
|
||||
psyco = None
|
||||
else:
|
||||
psyco = None
|
||||
|
||||
|
||||
def GetSupplementalFiles():
|
||||
"""Returns a list of the supplemental files that are included in all GYP
|
||||
sources."""
|
||||
return glob.glob(os.path.join(chrome_src, '*', 'supplement.gypi'))
|
||||
|
||||
|
||||
def FormatKeyForGN(key):
|
||||
"""Returns the given GYP key reformatted for GN.
|
||||
|
||||
GYP dictionary keys can be almost anything, but in GN they are identifiers
|
||||
and must follow the same rules. This reformats such keys to be valid GN
|
||||
identifiers."""
|
||||
return ''.join([c if c in string.ascii_letters else '_' for c in key])
|
||||
|
||||
|
||||
def EscapeStringForGN(s):
|
||||
"""Converts a string to a GN string literal."""
|
||||
for old, new in [('\\', '\\\\'), ('$', '\\$'), ('"', '\\"')]:
|
||||
s = s.replace(old, new)
|
||||
return '"' + s + '"'
|
||||
|
||||
|
||||
def ProcessGypDefinesItems(items):
|
||||
"""Converts a list of strings to a list of key-value pairs."""
|
||||
result = []
|
||||
for item in items:
|
||||
tokens = item.split('=', 1)
|
||||
# Some GYP variables have hyphens, which we don't support.
|
||||
key = FormatKeyForGN(tokens[0])
|
||||
if len(tokens) == 2:
|
||||
result += [(key, tokens[1])]
|
||||
else:
|
||||
# No value supplied, treat it as a boolean and set it. Note that we
|
||||
# use the string '1' here so we have a consistent definition whether
|
||||
# you do 'foo=1' or 'foo'.
|
||||
result += [(key, '1')]
|
||||
return result
|
||||
|
||||
|
||||
def GetGypVarsForGN(supplemental_files):
|
||||
"""Returns a dictionary of all GYP vars that we will be passing to GN."""
|
||||
# Find the .gyp directory in the user's home directory.
|
||||
home_dot_gyp = os.environ.get('GYP_CONFIG_DIR', None)
|
||||
if home_dot_gyp:
|
||||
home_dot_gyp = os.path.expanduser(home_dot_gyp)
|
||||
if not home_dot_gyp:
|
||||
home_vars = ['HOME']
|
||||
if sys.platform in ('cygwin', 'win32'):
|
||||
home_vars.append('USERPROFILE')
|
||||
for home_var in home_vars:
|
||||
home = os.getenv(home_var)
|
||||
if home != None:
|
||||
home_dot_gyp = os.path.join(home, '.gyp')
|
||||
if not os.path.exists(home_dot_gyp):
|
||||
home_dot_gyp = None
|
||||
else:
|
||||
break
|
||||
|
||||
if home_dot_gyp:
|
||||
include_gypi = os.path.join(home_dot_gyp, "include.gypi")
|
||||
if os.path.exists(include_gypi):
|
||||
supplemental_files += [include_gypi]
|
||||
|
||||
# GYP defines from the supplemental.gypi files.
|
||||
supp_items = []
|
||||
for supplement in supplemental_files:
|
||||
with open(supplement, 'r') as f:
|
||||
try:
|
||||
file_data = eval(f.read(), {'__builtins__': None}, None)
|
||||
except SyntaxError, e:
|
||||
e.filename = os.path.abspath(supplement)
|
||||
raise
|
||||
variables = file_data.get('variables', [])
|
||||
for v in variables:
|
||||
supp_items += [(FormatKeyForGN(v), str(variables[v]))]
|
||||
|
||||
# GYP defines from the environment.
|
||||
env_items = ProcessGypDefinesItems(
|
||||
shlex.split(os.environ.get('GYP_DEFINES', '')))
|
||||
|
||||
# GYP defines from the command line. We can't use optparse since we want
|
||||
# to ignore all arguments other than "-D".
|
||||
cmdline_input_items = []
|
||||
for i in range(len(sys.argv))[1:]:
|
||||
if sys.argv[i].startswith('-D'):
|
||||
if sys.argv[i] == '-D' and i + 1 < len(sys.argv):
|
||||
cmdline_input_items += [sys.argv[i + 1]]
|
||||
elif len(sys.argv[i]) > 2:
|
||||
cmdline_input_items += [sys.argv[i][2:]]
|
||||
cmdline_items = ProcessGypDefinesItems(cmdline_input_items)
|
||||
|
||||
vars_dict = dict(supp_items + env_items + cmdline_items)
|
||||
# It's not possible to set a default value for cpu_arch in GN, so do it here
|
||||
# for now (http://crbug.com/344767).
|
||||
if vars_dict.get('OS') == 'android' and not 'target_arch' in vars_dict:
|
||||
vars_dict['target_arch'] = 'arm'
|
||||
return vars_dict
|
||||
|
||||
|
||||
def GetOutputDirectory():
|
||||
"""Returns the output directory that GYP will use."""
|
||||
# GYP generator flags from the command line. We can't use optparse since we
|
||||
# want to ignore all arguments other than "-G".
|
||||
needle = '-Goutput_dir='
|
||||
cmdline_input_items = []
|
||||
for item in sys.argv[1:]:
|
||||
if item.startswith(needle):
|
||||
return item[len(needle):]
|
||||
|
||||
env_items = shlex.split(os.environ.get('GYP_GENERATOR_FLAGS', ''))
|
||||
needle = 'output_dir='
|
||||
for item in env_items:
|
||||
if item.startswith(needle):
|
||||
return item[len(needle):]
|
||||
|
||||
return "out"
|
||||
|
||||
|
||||
def GetArgsStringForGN(vars_dict):
|
||||
"""Returns the args to pass to GN.
|
||||
Based on a subset of the GYP variables that have been rewritten a bit."""
|
||||
gn_args = ''
|
||||
|
||||
# Note: These are the additional flags passed to various builds by builders
|
||||
# on the main waterfall. We'll probably need to add these at some point:
|
||||
# mac_strip_release=1 http://crbug.com/330301
|
||||
# linux_dump_symbols=0 http://crbug.com/330300
|
||||
# host_os=linux Probably can skip, GN knows the host OS.
|
||||
# order_text_section=<path> http://crbug.com/330299
|
||||
# chromium_win_pch=0 http://crbug.com/297678
|
||||
# chromium_ios_signing=0 http://crbug.com/330302
|
||||
# use_allocator=tcmalloc http://crbug.com/330303, 345554
|
||||
# release_extra_flags=... http://crbug.com/330305
|
||||
|
||||
# These tuples of (key, value, gn_arg_string) use the gn_arg_string for
|
||||
# gn when the key is set to the given value in the GYP arguments.
|
||||
remap_cases = [
|
||||
('android_webview_build', '1', 'is_android_webview_build=true'),
|
||||
('branding', 'Chrome', 'is_chrome_branded=true'),
|
||||
('build_for_tool', 'drmemory', 'disable_iterator_debugging=true'),
|
||||
('build_for_tool', 'tsan', 'disable_iterator_debugging=true'),
|
||||
('buildtype', 'Official', 'is_official_build=true'),
|
||||
('component', 'shared_library', 'is_component_build=true'),
|
||||
('clang', '1', 'is_clang=true'),
|
||||
('clang_use_chrome_plugins', '0', 'clang_use_chrome_plugins=false'),
|
||||
('disable_glibcxx_debug', '1', 'disable_iterator_debugging=true'),
|
||||
('enable_mdns', '0', 'enable_mdns=false'),
|
||||
('enable_mdns', '1', 'enable_mdns=true'),
|
||||
('enable_plugins', '0', 'enable_plugins=false'),
|
||||
('enable_plugins', '1', 'enable_plugins=true'),
|
||||
('target_arch', 'ia32', 'cpu_arch="x86"'),
|
||||
('target_arch', 'x64', 'cpu_arch="x64" force_win64=true'),
|
||||
('target_arch', 'arm', 'cpu_arch="arm"'),
|
||||
('target_arch', 'mipsel', 'cpu_arch="mipsel"'),
|
||||
('fastbuild', '0', 'symbol_level=2'),
|
||||
('fastbuild', '1', 'symbol_level=1'),
|
||||
('fastbuild', '2', 'symbol_level=0'),
|
||||
('OS', 'ios', 'os="ios"'),
|
||||
('OS', 'android', 'os="android"'),
|
||||
('chromeos', '1', 'os="chromeos"'),
|
||||
('use_aura', '1', 'use_aura=true'),
|
||||
('use_goma', '1', 'use_goma=true'),
|
||||
('use_openssl', '0', 'use_openssl=false'),
|
||||
('use_openssl', '1', 'use_openssl=true'),
|
||||
('asan', '1', 'is_asan=true'),
|
||||
('lsan', '1', 'is_lsan=true'),
|
||||
('msan', '1', 'is_msan=true'),
|
||||
('tsan', '1', 'is_tsan=true'),
|
||||
]
|
||||
for i in remap_cases:
|
||||
if i[0] in vars_dict and vars_dict[i[0]] == i[1]:
|
||||
gn_args += ' ' + i[2]
|
||||
|
||||
# These string arguments get passed directly as GN strings.
|
||||
for v in ['android_src', 'arm_float_abi', 'ios_deployment_target',
|
||||
'ios_sdk_path', 'windows_sdk_path']:
|
||||
if v in vars_dict:
|
||||
gn_args += ' ' + v + '=' + EscapeStringForGN(vars_dict[v])
|
||||
|
||||
# gomadir is renamed goma_dir in the GN build.
|
||||
if 'gomadir' in vars_dict:
|
||||
gn_args += ' goma_dir=%s' % EscapeStringForGN(vars_dict['gomadir'])
|
||||
|
||||
# Set the "use_ios_simulator" flag if the ios_sdk_path is set.
|
||||
if 'ios_sdk_path' in vars_dict:
|
||||
if os.path.basename(vars_dict['ios_sdk_path']).lower().startswith(
|
||||
'iphonesimulator'):
|
||||
gn_args += ' use_ios_simulator=true'
|
||||
else:
|
||||
gn_args += ' use_ios_simulator=false'
|
||||
|
||||
# These arguments get passed directly as integers (avoiding the quoting and
|
||||
# escaping of the string ones above).
|
||||
for v in ['arm_version']:
|
||||
if v in vars_dict:
|
||||
gn_args += ' %s=%s' % (v, vars_dict[v])
|
||||
|
||||
# Some other flags come from GYP environment variables.
|
||||
gyp_msvs_version = os.environ.get('GYP_MSVS_VERSION', '')
|
||||
if gyp_msvs_version:
|
||||
gn_args += ' visual_studio_version=' + EscapeStringForGN(gyp_msvs_version)
|
||||
gyp_msvs_override_path = os.environ.get('GYP_MSVS_OVERRIDE_PATH', '')
|
||||
if gyp_msvs_override_path:
|
||||
gn_args += ' visual_studio_path=' + \
|
||||
EscapeStringForGN(gyp_msvs_override_path)
|
||||
|
||||
# Set the GYP flag so BUILD files know they're being invoked in GYP mode.
|
||||
gn_args += ' is_gyp=true'
|
||||
|
||||
gyp_outdir = GetOutputDirectory()
|
||||
gn_args += ' gyp_output_dir=\"%s\"' % gyp_outdir
|
||||
|
||||
return gn_args.strip()
|
||||
|
||||
|
||||
def additional_include_files(supplemental_files, args=[]):
|
||||
"""
|
||||
Returns a list of additional (.gypi) files to include, without duplicating
|
||||
ones that are already specified on the command line. The list of supplemental
|
||||
include files is passed in as an argument.
|
||||
"""
|
||||
# Determine the include files specified on the command line.
|
||||
# This doesn't cover all the different option formats you can use,
|
||||
# but it's mainly intended to avoid duplicating flags on the automatic
|
||||
# makefile regeneration which only uses this format.
|
||||
specified_includes = set()
|
||||
for arg in args:
|
||||
if arg.startswith('-I') and len(arg) > 2:
|
||||
specified_includes.add(os.path.realpath(arg[2:]))
|
||||
|
||||
result = []
|
||||
def AddInclude(path):
|
||||
if os.path.realpath(path) not in specified_includes:
|
||||
result.append(path)
|
||||
|
||||
# Always include common.gypi.
|
||||
AddInclude(os.path.join(script_dir, 'common.gypi'))
|
||||
|
||||
# Optionally add supplemental .gypi files if present.
|
||||
for supplement in supplemental_files:
|
||||
AddInclude(supplement)
|
||||
|
||||
return result
|
||||
|
||||
|
||||
def RunGN(vars_dict):
|
||||
"""Runs GN, returning True if it succeeded, printing an error and returning
|
||||
false if not."""
|
||||
|
||||
# The binaries in platform-specific subdirectories in src/tools/gn/bin.
|
||||
gnpath = SRC_DIR + '/tools/gn/bin/'
|
||||
if sys.platform in ('cygwin', 'win32'):
|
||||
gnpath += 'win/gn.exe'
|
||||
elif sys.platform.startswith('linux'):
|
||||
# On Linux we have 32-bit and 64-bit versions.
|
||||
if subprocess.check_output(["getconf", "LONG_BIT"]).find("64") >= 0:
|
||||
gnpath += 'linux/gn'
|
||||
else:
|
||||
gnpath += 'linux/gn32'
|
||||
elif sys.platform == 'darwin':
|
||||
gnpath += 'mac/gn'
|
||||
else:
|
||||
print 'Unknown platform for GN: ', sys.platform
|
||||
return False
|
||||
|
||||
print 'Generating gyp files from GN...'
|
||||
|
||||
# Need to pass both the source root (the bots don't run this command from
|
||||
# within the source tree) as well as set the is_gyp value so the BUILD files
|
||||
# to know they're being run under GYP.
|
||||
args = [gnpath, 'gyp', '-q',
|
||||
'--root=' + chrome_src,
|
||||
'--args=' + GetArgsStringForGN(vars_dict),
|
||||
'--output=//' + GetOutputDirectory() + '/gn_build/']
|
||||
return subprocess.call(args) == 0
|
||||
|
||||
|
||||
def GetDesiredVsToolchainHashes():
|
||||
"""Load a list of SHA1s corresponding to the toolchains that we want installed
|
||||
to build with."""
|
||||
sha1path = os.path.join(script_dir, 'toolchain_vs2013.hash')
|
||||
with open(sha1path, 'rb') as f:
|
||||
return f.read().strip().splitlines()
|
||||
|
||||
|
||||
def DownloadVsToolChain():
|
||||
"""Download the Visual Studio toolchain on Windows.
|
||||
|
||||
If on Windows, request that depot_tools install/update the automatic
|
||||
toolchain, and then use it (unless opted-out) and return a tuple containing
|
||||
the x64 and x86 paths. Otherwise return None.
|
||||
"""
|
||||
vs2013_runtime_dll_dirs = None
|
||||
depot_tools_win_toolchain = \
|
||||
bool(int(os.environ.get('DEPOT_TOOLS_WIN_TOOLCHAIN', '1')))
|
||||
if sys.platform in ('win32', 'cygwin') and depot_tools_win_toolchain:
|
||||
import find_depot_tools
|
||||
depot_tools_path = find_depot_tools.add_depot_tools_to_path()
|
||||
temp_handle, data_file = tempfile.mkstemp(suffix='.json')
|
||||
os.close(temp_handle)
|
||||
get_toolchain_args = [
|
||||
sys.executable,
|
||||
os.path.join(depot_tools_path,
|
||||
'win_toolchain',
|
||||
'get_toolchain_if_necessary.py'),
|
||||
'--output-json', data_file,
|
||||
] + GetDesiredVsToolchainHashes()
|
||||
subprocess.check_call(get_toolchain_args)
|
||||
|
||||
with open(data_file, 'r') as tempf:
|
||||
toolchain_data = json.load(tempf)
|
||||
os.unlink(data_file)
|
||||
|
||||
toolchain = toolchain_data['path']
|
||||
version = toolchain_data['version']
|
||||
version_is_pro = version[-1] != 'e'
|
||||
win8sdk = toolchain_data['win8sdk']
|
||||
wdk = toolchain_data['wdk']
|
||||
# TODO(scottmg): The order unfortunately matters in these. They should be
|
||||
# split into separate keys for x86 and x64. (See CopyVsRuntimeDlls call
|
||||
# below). http://crbug.com/345992
|
||||
vs2013_runtime_dll_dirs = toolchain_data['runtime_dirs']
|
||||
|
||||
os.environ['GYP_MSVS_OVERRIDE_PATH'] = toolchain
|
||||
os.environ['GYP_MSVS_VERSION'] = version
|
||||
# We need to make sure windows_sdk_path is set to the automated
|
||||
# toolchain values in GYP_DEFINES, but don't want to override any
|
||||
# otheroptions.express
|
||||
# values there.
|
||||
gyp_defines_dict = gyp.NameValueListToDict(gyp.ShlexEnv('GYP_DEFINES'))
|
||||
gyp_defines_dict['windows_sdk_path'] = win8sdk
|
||||
os.environ['GYP_DEFINES'] = ' '.join('%s=%s' % (k, pipes.quote(str(v)))
|
||||
for k, v in gyp_defines_dict.iteritems())
|
||||
os.environ['WINDOWSSDKDIR'] = win8sdk
|
||||
os.environ['WDK_DIR'] = wdk
|
||||
# Include the VS runtime in the PATH in case it's not machine-installed.
|
||||
runtime_path = ';'.join(vs2013_runtime_dll_dirs)
|
||||
os.environ['PATH'] = runtime_path + ';' + os.environ['PATH']
|
||||
print('Using automatic toolchain in %s (%s edition).' % (
|
||||
toolchain, 'Pro' if version_is_pro else 'Express'))
|
||||
return vs2013_runtime_dll_dirs
|
||||
|
||||
|
||||
def CopyVsRuntimeDlls(output_dir, runtime_dirs):
|
||||
"""Copies the VS runtime DLLs from the given |runtime_dirs| to the output
|
||||
directory so that even if not system-installed, built binaries are likely to
|
||||
be able to run.
|
||||
|
||||
This needs to be run after gyp has been run so that the expected target
|
||||
output directories are already created.
|
||||
"""
|
||||
assert sys.platform.startswith(('win32', 'cygwin'))
|
||||
|
||||
def copy_runtime(target_dir, source_dir, dll_pattern):
|
||||
"""Copy both the msvcr and msvcp runtime DLLs, only if the target doesn't
|
||||
exist, but the target directory does exist."""
|
||||
for which in ('p', 'r'):
|
||||
dll = dll_pattern % which
|
||||
target = os.path.join(target_dir, dll)
|
||||
source = os.path.join(source_dir, dll)
|
||||
# If gyp generated to that output dir, and the runtime isn't already
|
||||
# there, then copy it over.
|
||||
if (os.path.isdir(target_dir) and
|
||||
(not os.path.isfile(target) or
|
||||
os.stat(target).st_mtime != os.stat(source).st_mtime)):
|
||||
print 'Copying %s to %s...' % (source, target)
|
||||
if os.path.exists(target):
|
||||
os.unlink(target)
|
||||
shutil.copy2(source, target)
|
||||
|
||||
x86, x64 = runtime_dirs
|
||||
out_debug = os.path.join(output_dir, 'Debug')
|
||||
out_debug_nacl64 = os.path.join(output_dir, 'Debug', 'x64')
|
||||
out_release = os.path.join(output_dir, 'Release')
|
||||
out_release_nacl64 = os.path.join(output_dir, 'Release', 'x64')
|
||||
out_debug_x64 = os.path.join(output_dir, 'Debug_x64')
|
||||
out_release_x64 = os.path.join(output_dir, 'Release_x64')
|
||||
|
||||
if os.path.exists(out_debug) and not os.path.exists(out_debug_nacl64):
|
||||
os.makedirs(out_debug_nacl64)
|
||||
if os.path.exists(out_release) and not os.path.exists(out_release_nacl64):
|
||||
os.makedirs(out_release_nacl64)
|
||||
copy_runtime(out_debug, x86, 'msvc%s120d.dll')
|
||||
copy_runtime(out_release, x86, 'msvc%s120.dll')
|
||||
copy_runtime(out_debug_x64, x64, 'msvc%s120d.dll')
|
||||
copy_runtime(out_release_x64, x64, 'msvc%s120.dll')
|
||||
copy_runtime(out_debug_nacl64, x64, 'msvc%s120d.dll')
|
||||
copy_runtime(out_release_nacl64, x64, 'msvc%s120.dll')
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
args = sys.argv[1:]
|
||||
|
||||
if int(os.environ.get('GYP_CHROMIUM_NO_ACTION', 0)):
|
||||
print 'Skipping gyp_chromium due to GYP_CHROMIUM_NO_ACTION env var.'
|
||||
sys.exit(0)
|
||||
|
||||
# Use the Psyco JIT if available.
|
||||
if psyco:
|
||||
psyco.profile()
|
||||
print "Enabled Psyco JIT."
|
||||
|
||||
# Fall back on hermetic python if we happen to get run under cygwin.
|
||||
# TODO(bradnelson): take this out once this issue is fixed:
|
||||
# http://code.google.com/p/gyp/issues/detail?id=177
|
||||
if sys.platform == 'cygwin':
|
||||
import find_depot_tools
|
||||
depot_tools_path = find_depot_tools.add_depot_tools_to_path()
|
||||
python_dir = sorted(glob.glob(os.path.join(depot_tools_path,
|
||||
'python2*_bin')))[-1]
|
||||
env = os.environ.copy()
|
||||
env['PATH'] = python_dir + os.pathsep + env.get('PATH', '')
|
||||
p = subprocess.Popen(
|
||||
[os.path.join(python_dir, 'python.exe')] + sys.argv,
|
||||
env=env, shell=False)
|
||||
p.communicate()
|
||||
sys.exit(p.returncode)
|
||||
|
||||
gyp_helper.apply_chromium_gyp_env()
|
||||
|
||||
# This could give false positives since it doesn't actually do real option
|
||||
# parsing. Oh well.
|
||||
gyp_file_specified = False
|
||||
for arg in args:
|
||||
if arg.endswith('.gyp'):
|
||||
gyp_file_specified = True
|
||||
break
|
||||
|
||||
# If we didn't get a file, check an env var, and then fall back to
|
||||
# assuming 'all.gyp' from the same directory as the script.
|
||||
if not gyp_file_specified:
|
||||
gyp_file = os.environ.get('CHROMIUM_GYP_FILE')
|
||||
if gyp_file:
|
||||
# Note that CHROMIUM_GYP_FILE values can't have backslashes as
|
||||
# path separators even on Windows due to the use of shlex.split().
|
||||
args.extend(shlex.split(gyp_file))
|
||||
else:
|
||||
args.append(os.path.join(script_dir, 'all.gyp'))
|
||||
|
||||
# There shouldn't be a circular dependency relationship between .gyp files,
|
||||
# but in Chromium's .gyp files, on non-Mac platforms, circular relationships
|
||||
# currently exist. The check for circular dependencies is currently
|
||||
# bypassed on other platforms, but is left enabled on the Mac, where a
|
||||
# violation of the rule causes Xcode to misbehave badly.
|
||||
# TODO(mark): Find and kill remaining circular dependencies, and remove this
|
||||
# option. http://crbug.com/35878.
|
||||
# TODO(tc): Fix circular dependencies in ChromiumOS then add linux2 to the
|
||||
# list.
|
||||
if sys.platform not in ('darwin',):
|
||||
args.append('--no-circular-check')
|
||||
|
||||
# Default to make if no generator has
|
||||
# explicitly been set.
|
||||
if not os.environ.get('GYP_GENERATORS'):
|
||||
os.environ['GYP_GENERATORS'] = 'make'
|
||||
elif sys.platform == 'darwin' and not os.environ.get('GYP_GENERATORS') and \
|
||||
not 'OS=ios' in os.environ.get('GYP_DEFINES', []):
|
||||
os.environ['GYP_GENERATORS'] = 'make'
|
||||
|
||||
vs2013_runtime_dll_dirs = DownloadVsToolChain()
|
||||
|
||||
# If CHROMIUM_GYP_SYNTAX_CHECK is set to 1, it will invoke gyp with --check
|
||||
# to enfore syntax checking.
|
||||
syntax_check = os.environ.get('CHROMIUM_GYP_SYNTAX_CHECK')
|
||||
if syntax_check and int(syntax_check):
|
||||
args.append('--check')
|
||||
|
||||
supplemental_includes = GetSupplementalFiles()
|
||||
gn_vars_dict = GetGypVarsForGN(supplemental_includes)
|
||||
|
||||
# Automatically turn on crosscompile support for platforms that need it.
|
||||
# (The Chrome OS build sets CC_host / CC_target which implicitly enables
|
||||
# this mode.)
|
||||
if all(('ninja' in os.environ.get('GYP_GENERATORS', ''),
|
||||
gn_vars_dict.get('OS') in ['android', 'ios'],
|
||||
'GYP_CROSSCOMPILE' not in os.environ)):
|
||||
os.environ['GYP_CROSSCOMPILE'] = '1'
|
||||
|
||||
# TODO(brettw) bug 350974 either turn back on GN or delete all of this code.
|
||||
#if not RunGN(gn_vars_dict):
|
||||
# sys.exit(1)
|
||||
args.extend(
|
||||
['-I' + i for i in additional_include_files(supplemental_includes, args)])
|
||||
|
||||
args.extend(['-D', 'gyp_output_dir=' + GetOutputDirectory()])
|
||||
|
||||
print 'Updating projects from gyp files...'
|
||||
sys.stdout.flush()
|
||||
|
||||
# Off we go...
|
||||
gyp_rc = gyp.main(args)
|
||||
|
||||
# Check for landmines (reasons to clobber the build). This must be run here,
|
||||
# rather than a separate runhooks step so that any environment modifications
|
||||
# from above are picked up.
|
||||
print 'Running build/landmines.py...'
|
||||
subprocess.check_call(
|
||||
[sys.executable, os.path.join(script_dir, 'landmines.py')])
|
||||
|
||||
if vs2013_runtime_dll_dirs:
|
||||
x64_runtime, x86_runtime = vs2013_runtime_dll_dirs
|
||||
CopyVsRuntimeDlls(os.path.join(chrome_src, GetOutputDirectory()),
|
||||
(x86_runtime, x64_runtime))
|
||||
|
||||
sys.exit(gyp_rc)
|
||||
@@ -0,0 +1,54 @@
|
||||
# Copyright (c) 2012 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
# This file helps gyp_chromium and landmines correctly set up the gyp
|
||||
# environment from chromium.gyp_env on disk
|
||||
|
||||
import os
|
||||
|
||||
SCRIPT_DIR = os.path.dirname(os.path.realpath(__file__))
|
||||
CHROME_SRC = os.path.dirname(SCRIPT_DIR)
|
||||
|
||||
|
||||
def apply_gyp_environment_from_file(file_path):
|
||||
"""Reads in a *.gyp_env file and applies the valid keys to os.environ."""
|
||||
if not os.path.exists(file_path):
|
||||
return
|
||||
with open(file_path, 'rU') as f:
|
||||
file_contents = f.read()
|
||||
try:
|
||||
file_data = eval(file_contents, {'__builtins__': None}, None)
|
||||
except SyntaxError, e:
|
||||
e.filename = os.path.abspath(file_path)
|
||||
raise
|
||||
supported_vars = (
|
||||
'CC',
|
||||
'CC_wrapper',
|
||||
'CHROMIUM_GYP_FILE',
|
||||
'CHROMIUM_GYP_SYNTAX_CHECK',
|
||||
'CXX',
|
||||
'CXX_wrapper',
|
||||
'GYP_DEFINES',
|
||||
'GYP_GENERATOR_FLAGS',
|
||||
'GYP_CROSSCOMPILE',
|
||||
'GYP_GENERATOR_OUTPUT',
|
||||
'GYP_GENERATORS',
|
||||
'GYP_MSVS_VERSION',
|
||||
)
|
||||
for var in supported_vars:
|
||||
file_val = file_data.get(var)
|
||||
if file_val:
|
||||
if var in os.environ:
|
||||
print 'INFO: Environment value for "%s" overrides value in %s.' % (
|
||||
var, os.path.abspath(file_path)
|
||||
)
|
||||
else:
|
||||
os.environ[var] = file_val
|
||||
|
||||
|
||||
def apply_chromium_gyp_env():
|
||||
if 'SKIP_CHROMIUM_GYP_ENV' not in os.environ:
|
||||
# Update the environment based on chromium.gyp_env
|
||||
path = os.path.join(os.path.dirname(CHROME_SRC), 'chromium.gyp_env')
|
||||
apply_gyp_environment_from_file(path)
|
||||
@@ -0,0 +1,166 @@
|
||||
# Copyright (c) 2010 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
{
|
||||
'variables': {
|
||||
'install_path': '<(DEPTH)/install',
|
||||
'version_py_path': '<(DEPTH)/build/version.py',
|
||||
'version_path': '<(DEPTH)/net/instaweb/public/VERSION',
|
||||
'lastchange_path': '<(SHARED_INTERMEDIATE_DIR)/build/LASTCHANGE',
|
||||
'branding_dir': '<(install_path)/common',
|
||||
},
|
||||
'conditions': [
|
||||
['OS=="linux"', {
|
||||
'variables': {
|
||||
'version' : '<!(python <(version_py_path) -f <(version_path) -t "@MAJOR@.@MINOR@.@BUILD@.@PATCH@")',
|
||||
'revision' : '<!(if [ -f <(DEPTH)/LASTCHANGE.in ]; then cat <(DEPTH)/LASTCHANGE.in | cut -d= -f2; else git rev-list --all --count; fi)',
|
||||
'packaging_files_common': [
|
||||
'<(install_path)/common/apt.include',
|
||||
'<(install_path)/common/mod-pagespeed/mod-pagespeed.info',
|
||||
'<(install_path)/common/installer.include',
|
||||
'<(install_path)/common/repo.cron',
|
||||
'<(install_path)/common/rpm.include',
|
||||
'<(install_path)/common/rpmrepo.cron',
|
||||
'<(install_path)/common/updater',
|
||||
'<(install_path)/common/variables.include',
|
||||
'<(install_path)/common/BRANDING',
|
||||
'<(install_path)/common/pagespeed.load.template',
|
||||
'<(install_path)/common/pagespeed.conf.template',
|
||||
],
|
||||
'packaging_files_deb': [
|
||||
'<(install_path)/debian/build.sh',
|
||||
'<(install_path)/debian/changelog.template',
|
||||
'<(install_path)/debian/conffiles',
|
||||
'<(install_path)/debian/control.template',
|
||||
'<(install_path)/debian/postinst',
|
||||
'<(install_path)/debian/postrm',
|
||||
'<(install_path)/debian/prerm',
|
||||
],
|
||||
'packaging_files_rpm': [
|
||||
'<(install_path)/rpm/build.sh',
|
||||
'<(install_path)/rpm/mod-pagespeed.spec.template',
|
||||
],
|
||||
'packaging_files_binaries': [
|
||||
'<(PRODUCT_DIR)/libmod_pagespeed.so',
|
||||
'<(PRODUCT_DIR)/libmod_pagespeed_ap24.so',
|
||||
],
|
||||
'flock_bash': ['flock', '--', '/tmp/linux_package_lock', 'bash'],
|
||||
'deb_build': '<(PRODUCT_DIR)/install/debian/build.sh',
|
||||
'rpm_build': '<(PRODUCT_DIR)/install/rpm/build.sh',
|
||||
'deb_cmd': ['<@(flock_bash)', '<(deb_build)', '-o' '<(PRODUCT_DIR)',
|
||||
'-b', '<(PRODUCT_DIR)', '-a', '<(target_arch)'],
|
||||
'rpm_cmd': ['<@(flock_bash)', '<(rpm_build)', '-o' '<(PRODUCT_DIR)',
|
||||
'-b', '<(PRODUCT_DIR)', '-a', '<(target_arch)'],
|
||||
'conditions': [
|
||||
['target_arch=="ia32"', {
|
||||
'deb_arch': 'i386',
|
||||
'rpm_arch': 'i386',
|
||||
}],
|
||||
['target_arch=="x64"', {
|
||||
'deb_arch': 'amd64',
|
||||
'rpm_arch': 'x86_64',
|
||||
}],
|
||||
],
|
||||
},
|
||||
'targets': [
|
||||
{
|
||||
'target_name': 'linux_installer_configs',
|
||||
'type': 'none',
|
||||
# Add these files to the build output so the build archives will be
|
||||
# "hermetic" for packaging.
|
||||
'copies': [
|
||||
{
|
||||
'destination': '<(PRODUCT_DIR)/install/debian/',
|
||||
'files': [
|
||||
'<@(packaging_files_deb)',
|
||||
]
|
||||
},
|
||||
{
|
||||
'destination': '<(PRODUCT_DIR)/install/rpm/',
|
||||
'files': [
|
||||
'<@(packaging_files_rpm)',
|
||||
]
|
||||
},
|
||||
{
|
||||
'destination': '<(PRODUCT_DIR)/install/common/',
|
||||
'files': [
|
||||
'<@(packaging_files_common)',
|
||||
]
|
||||
},
|
||||
],
|
||||
'actions': [
|
||||
{
|
||||
'action_name': 'save_build_info',
|
||||
'inputs': [
|
||||
'<(branding_dir)/BRANDING',
|
||||
'<(version_path)',
|
||||
'<(lastchange_path)',
|
||||
],
|
||||
'outputs': [
|
||||
'<(PRODUCT_DIR)/installer/version.txt',
|
||||
],
|
||||
# Just output the default version info variables.
|
||||
'action': [
|
||||
'python', '<(version_py_path)',
|
||||
'-f', '<(branding_dir)/BRANDING',
|
||||
'-f', '<(version_path)',
|
||||
'-f', '<(lastchange_path)',
|
||||
'-o', '<@(_outputs)'
|
||||
],
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
'target_name': 'linux_package_deb_stable',
|
||||
'suppress_wildcard': 1,
|
||||
'variables': {
|
||||
'channel': 'stable',
|
||||
},
|
||||
'includes': [
|
||||
'linux_package_deb.gypi',
|
||||
],
|
||||
},
|
||||
{
|
||||
'target_name': 'linux_package_deb_beta',
|
||||
'suppress_wildcard': 1,
|
||||
'variables': {
|
||||
'channel': 'beta',
|
||||
},
|
||||
'includes': [
|
||||
'linux_package_deb.gypi',
|
||||
],
|
||||
},
|
||||
{
|
||||
'target_name': 'linux_package_rpm_stable',
|
||||
'suppress_wildcard': 1,
|
||||
'variables': {
|
||||
'channel': 'stable',
|
||||
},
|
||||
'includes': [
|
||||
'linux_package_rpm.gypi',
|
||||
],
|
||||
},
|
||||
{
|
||||
'target_name': 'linux_package_rpm_beta',
|
||||
'suppress_wildcard': 1,
|
||||
'variables': {
|
||||
'channel': 'beta',
|
||||
},
|
||||
'includes': [
|
||||
'linux_package_rpm.gypi',
|
||||
],
|
||||
},
|
||||
],
|
||||
},{
|
||||
'targets': [
|
||||
],
|
||||
}],
|
||||
],
|
||||
}
|
||||
|
||||
# Local Variables:
|
||||
# tab-width:2
|
||||
# indent-tabs-mode:nil
|
||||
# End:
|
||||
# vim: set expandtab tabstop=2 shiftwidth=2:
|
||||
+398
@@ -0,0 +1,398 @@
|
||||
# Copyright (c) 2012 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
# This file is meant to be included into a target to provide a rule
|
||||
# to build Java in a consistent manner.
|
||||
#
|
||||
# To use this, create a gyp target with the following form:
|
||||
# {
|
||||
# 'target_name': 'my-package_java',
|
||||
# 'type': 'none',
|
||||
# 'variables': {
|
||||
# 'java_in_dir': 'path/to/package/root',
|
||||
# },
|
||||
# 'includes': ['path/to/this/gypi/file'],
|
||||
# }
|
||||
#
|
||||
# Required variables:
|
||||
# java_in_dir - The top-level java directory. The src should be in
|
||||
# <java_in_dir>/src.
|
||||
# Optional/automatic variables:
|
||||
# additional_input_paths - These paths will be included in the 'inputs' list to
|
||||
# ensure that this target is rebuilt when one of these paths changes.
|
||||
# additional_src_dirs - Additional directories with .java files to be compiled
|
||||
# and included in the output of this target.
|
||||
# generated_src_dirs - Same as additional_src_dirs except used for .java files
|
||||
# that are generated at build time. This should be set automatically by a
|
||||
# target's dependencies. The .java files in these directories are not
|
||||
# included in the 'inputs' list (unlike additional_src_dirs).
|
||||
# input_jars_paths - The path to jars to be included in the classpath. This
|
||||
# should be filled automatically by depending on the appropriate targets.
|
||||
# javac_includes - A list of specific files to include. This is by default
|
||||
# empty, which leads to inclusion of all files specified. May include
|
||||
# wildcard, and supports '**/' for recursive path wildcards, ie.:
|
||||
# '**/MyFileRegardlessOfDirectory.java', '**/IncludedPrefix*.java'.
|
||||
# has_java_resources - Set to 1 if the java target contains an
|
||||
# Android-compatible resources folder named res. If 1, R_package and
|
||||
# R_package_relpath must also be set.
|
||||
# R_package - The java package in which the R class (which maps resources to
|
||||
# integer IDs) should be generated, e.g. org.chromium.content.
|
||||
# R_package_relpath - Same as R_package, but replace each '.' with '/'.
|
||||
# java_strings_grd - The name of the grd file from which to generate localized
|
||||
# strings.xml files, if any.
|
||||
# res_extra_dirs - A list of extra directories containing Android resources.
|
||||
# These directories may be generated at build time.
|
||||
# res_extra_files - A list of the files in res_extra_dirs.
|
||||
# never_lint - Set to 1 to not run lint on this target.
|
||||
|
||||
{
|
||||
'dependencies': [
|
||||
'<(DEPTH)/build/android/setup.gyp:build_output_dirs'
|
||||
],
|
||||
'variables': {
|
||||
'android_jar': '<(android_sdk)/android.jar',
|
||||
'input_jars_paths': [ '<(android_jar)' ],
|
||||
'additional_src_dirs': [],
|
||||
'javac_includes': [],
|
||||
'jar_name': '<(_target_name).jar',
|
||||
'jar_dir': '<(PRODUCT_DIR)/lib.java',
|
||||
'jar_path': '<(intermediate_dir)/<(jar_name)',
|
||||
'jar_final_path': '<(jar_dir)/<(jar_name)',
|
||||
'jar_excluded_classes': [ '*/R.class', '*/R##*.class' ],
|
||||
'instr_stamp': '<(intermediate_dir)/instr.stamp',
|
||||
'additional_input_paths': [],
|
||||
'dex_path': '<(PRODUCT_DIR)/lib.java/<(_target_name).dex.jar',
|
||||
'generated_src_dirs': ['>@(generated_R_dirs)'],
|
||||
'generated_R_dirs': [],
|
||||
'has_java_resources%': 0,
|
||||
'java_strings_grd%': '',
|
||||
'res_extra_dirs': [],
|
||||
'res_extra_files': [],
|
||||
'res_v14_verify_only%': 0,
|
||||
'resource_input_paths': ['>@(res_extra_files)'],
|
||||
'intermediate_dir': '<(SHARED_INTERMEDIATE_DIR)/<(_target_name)',
|
||||
'classes_dir': '<(intermediate_dir)/classes',
|
||||
'compile_stamp': '<(intermediate_dir)/compile.stamp',
|
||||
'lint_stamp': '<(intermediate_dir)/lint.stamp',
|
||||
'lint_result': '<(intermediate_dir)/lint_result.xml',
|
||||
'lint_config': '<(intermediate_dir)/lint_config.xml',
|
||||
'never_lint%': 0,
|
||||
'proguard_config%': '',
|
||||
'proguard_preprocess%': '0',
|
||||
'variables': {
|
||||
'variables': {
|
||||
'proguard_preprocess%': 0,
|
||||
'emma_never_instrument%': 0,
|
||||
},
|
||||
'conditions': [
|
||||
['proguard_preprocess == 1', {
|
||||
'javac_jar_path': '<(intermediate_dir)/<(_target_name).pre.jar'
|
||||
}, {
|
||||
'javac_jar_path': '<(jar_path)'
|
||||
}],
|
||||
['chromium_code != 0 and emma_coverage != 0 and emma_never_instrument == 0', {
|
||||
'emma_instrument': 1,
|
||||
}, {
|
||||
'emma_instrument': 0,
|
||||
}],
|
||||
],
|
||||
},
|
||||
'emma_instrument': '<(emma_instrument)',
|
||||
'javac_jar_path': '<(javac_jar_path)',
|
||||
},
|
||||
# This all_dependent_settings is used for java targets only. This will add the
|
||||
# jar path to the classpath of dependent java targets.
|
||||
'all_dependent_settings': {
|
||||
'variables': {
|
||||
'input_jars_paths': ['<(jar_final_path)'],
|
||||
'library_dexed_jars_paths': ['<(dex_path)'],
|
||||
},
|
||||
},
|
||||
'conditions': [
|
||||
['has_java_resources == 1', {
|
||||
'variables': {
|
||||
'res_dir': '<(java_in_dir)/res',
|
||||
'res_crunched_dir': '<(intermediate_dir)/res_crunched',
|
||||
'res_v14_compatibility_stamp': '<(intermediate_dir)/res_v14_compatibility.stamp',
|
||||
'res_v14_compatibility_dir': '<(intermediate_dir)/res_v14_compatibility',
|
||||
'res_input_dirs': ['<(res_dir)', '<@(res_extra_dirs)'],
|
||||
'resource_input_paths': ['<!@(find <(res_dir) -type f)'],
|
||||
'R_dir': '<(intermediate_dir)/java_R',
|
||||
'R_text_file': '<(R_dir)/R.txt',
|
||||
'R_stamp': '<(intermediate_dir)/resources.stamp',
|
||||
'generated_src_dirs': ['<(R_dir)'],
|
||||
'additional_input_paths': ['<(R_stamp)',
|
||||
'<(res_v14_compatibility_stamp)',],
|
||||
'additional_res_dirs': [],
|
||||
'dependencies_res_input_dirs': [],
|
||||
'dependencies_res_files': [],
|
||||
},
|
||||
'all_dependent_settings': {
|
||||
'variables': {
|
||||
# Dependent jars include this target's R.java file via
|
||||
# generated_R_dirs and include its resources via
|
||||
# dependencies_res_files.
|
||||
'generated_R_dirs': ['<(R_dir)'],
|
||||
'additional_input_paths': ['<(R_stamp)',
|
||||
'<(res_v14_compatibility_stamp)',],
|
||||
'dependencies_res_files': ['<@(resource_input_paths)'],
|
||||
|
||||
'dependencies_res_input_dirs': ['<@(res_input_dirs)'],
|
||||
|
||||
# Dependent APKs include this target's resources via
|
||||
# additional_res_dirs, additional_res_packages, and
|
||||
# additional_R_text_files.
|
||||
'additional_res_dirs': ['<(res_crunched_dir)',
|
||||
'<(res_v14_compatibility_dir)',
|
||||
'<@(res_input_dirs)'],
|
||||
'additional_res_packages': ['<(R_package)'],
|
||||
'additional_R_text_files': ['<(R_text_file)'],
|
||||
},
|
||||
},
|
||||
'conditions': [
|
||||
['java_strings_grd != ""', {
|
||||
'variables': {
|
||||
'res_grit_dir': '<(intermediate_dir)/res_grit',
|
||||
'res_input_dirs': ['<(res_grit_dir)'],
|
||||
'grit_grd_file': '<(java_in_dir)/strings/<(java_strings_grd)',
|
||||
'resource_input_paths': ['<!@pymod_do_main(grit_info <@(grit_defines) --outputs "<(res_grit_dir)" <(grit_grd_file))'],
|
||||
},
|
||||
'actions': [
|
||||
{
|
||||
'action_name': 'generate_localized_strings_xml',
|
||||
'variables': {
|
||||
'grit_additional_defines': ['-E', 'ANDROID_JAVA_TAGGED_ONLY=false'],
|
||||
'grit_out_dir': '<(res_grit_dir)',
|
||||
# resource_ids is unneeded since we don't generate .h headers.
|
||||
'grit_resource_ids': '',
|
||||
},
|
||||
'includes': ['../build/grit_action.gypi'],
|
||||
},
|
||||
],
|
||||
}],
|
||||
],
|
||||
'actions': [
|
||||
# Generate R.java and crunch image resources.
|
||||
{
|
||||
'action_name': 'process_resources',
|
||||
'message': 'processing resources for <(_target_name)',
|
||||
'variables': {
|
||||
'android_manifest': '<(DEPTH)/build/android/AndroidManifest.xml',
|
||||
# Include the dependencies' res dirs so that references to
|
||||
# resources in dependencies can be resolved.
|
||||
'all_res_dirs': ['<@(res_input_dirs)',
|
||||
'>@(dependencies_res_input_dirs)',],
|
||||
# Write the inputs list to a file, so that the action command
|
||||
# line won't exceed the OS limits when calculating the checksum
|
||||
# of the list.
|
||||
'inputs_list_file': '>|(inputs_list.<(_target_name).gypcmd >@(_inputs))'
|
||||
},
|
||||
'inputs': [
|
||||
'<(DEPTH)/build/android/gyp/util/build_utils.py',
|
||||
'<(DEPTH)/build/android/gyp/process_resources.py',
|
||||
'>@(resource_input_paths)',
|
||||
'>@(dependencies_res_files)',
|
||||
],
|
||||
'outputs': [
|
||||
'<(R_stamp)',
|
||||
],
|
||||
'action': [
|
||||
'python', '<(DEPTH)/build/android/gyp/process_resources.py',
|
||||
'--android-sdk', '<(android_sdk)',
|
||||
'--android-sdk-tools', '<(android_sdk_tools)',
|
||||
'--R-dir', '<(R_dir)',
|
||||
'--res-dirs', '>(all_res_dirs)',
|
||||
'--crunch-input-dir', '>(res_dir)',
|
||||
'--crunch-output-dir', '<(res_crunched_dir)',
|
||||
'--android-manifest', '<(android_manifest)',
|
||||
'--non-constant-id',
|
||||
'--custom-package', '<(R_package)',
|
||||
'--stamp', '<(R_stamp)',
|
||||
|
||||
# Add hash of inputs to the command line, so if inputs change
|
||||
# (e.g. if a resource if removed), the command will be re-run.
|
||||
# TODO(newt): remove this once crbug.com/177552 is fixed in ninja.
|
||||
'--ignore=>!(md5sum >(inputs_list_file))',
|
||||
],
|
||||
},
|
||||
# Generate API 14 resources.
|
||||
{
|
||||
'action_name': 'generate_api_14_resources_<(_target_name)',
|
||||
'message': 'Generating Android API 14 resources <(_target_name)',
|
||||
'variables' : {
|
||||
'res_v14_additional_options': [],
|
||||
},
|
||||
'conditions': [
|
||||
['res_v14_verify_only == 1', {
|
||||
'variables': {
|
||||
'res_v14_additional_options': ['--verify-only']
|
||||
},
|
||||
}],
|
||||
],
|
||||
'inputs': [
|
||||
'<(DEPTH)/build/android/gyp/util/build_utils.py',
|
||||
'<(DEPTH)/build/android/gyp/generate_v14_compatible_resources.py',
|
||||
'>@(resource_input_paths)',
|
||||
],
|
||||
'outputs': [
|
||||
'<(res_v14_compatibility_stamp)',
|
||||
],
|
||||
'action': [
|
||||
'python', '<(DEPTH)/build/android/gyp/generate_v14_compatible_resources.py',
|
||||
'--res-dir=<(res_dir)',
|
||||
'--res-v14-compatibility-dir=<(res_v14_compatibility_dir)',
|
||||
'--stamp', '<(res_v14_compatibility_stamp)',
|
||||
'<@(res_v14_additional_options)',
|
||||
]
|
||||
},
|
||||
],
|
||||
}],
|
||||
['proguard_preprocess == 1', {
|
||||
'actions': [
|
||||
{
|
||||
'action_name': 'proguard_<(_target_name)',
|
||||
'message': 'Proguard preprocessing <(_target_name) jar',
|
||||
'inputs': [
|
||||
'<(android_sdk_root)/tools/proguard/bin/proguard.sh',
|
||||
'<(DEPTH)/build/android/gyp/util/build_utils.py',
|
||||
'<(DEPTH)/build/android/gyp/proguard.py',
|
||||
'<(javac_jar_path)',
|
||||
'<(proguard_config)',
|
||||
],
|
||||
'outputs': [
|
||||
'<(jar_path)',
|
||||
],
|
||||
'action': [
|
||||
'python', '<(DEPTH)/build/android/gyp/proguard.py',
|
||||
'--proguard-path=<(android_sdk_root)/tools/proguard/bin/proguard.sh',
|
||||
'--input-path=<(javac_jar_path)',
|
||||
'--output-path=<(jar_path)',
|
||||
'--proguard-config=<(proguard_config)',
|
||||
'--classpath=<(android_sdk_jar) >(input_jars_paths)',
|
||||
]
|
||||
},
|
||||
],
|
||||
}],
|
||||
],
|
||||
'actions': [
|
||||
{
|
||||
'action_name': 'javac_<(_target_name)',
|
||||
'message': 'Compiling <(_target_name) java sources',
|
||||
'variables': {
|
||||
'all_src_dirs': [
|
||||
'>(java_in_dir)/src',
|
||||
'>@(additional_src_dirs)',
|
||||
'>@(generated_src_dirs)',
|
||||
],
|
||||
},
|
||||
'inputs': [
|
||||
'<(DEPTH)/build/android/gyp/util/build_utils.py',
|
||||
'<(DEPTH)/build/android/gyp/javac.py',
|
||||
'>!@(find >(java_in_dir)/src >(additional_src_dirs) -name "*.java")',
|
||||
'>@(input_jars_paths)',
|
||||
'>@(additional_input_paths)',
|
||||
],
|
||||
'outputs': [
|
||||
'<(compile_stamp)',
|
||||
],
|
||||
'action': [
|
||||
'python', '<(DEPTH)/build/android/gyp/javac.py',
|
||||
'--output-dir=<(classes_dir)',
|
||||
'--classpath=>(input_jars_paths)',
|
||||
'--src-dirs=>(all_src_dirs)',
|
||||
'--javac-includes=<(javac_includes)',
|
||||
'--chromium-code=<(chromium_code)',
|
||||
'--stamp=<(compile_stamp)',
|
||||
|
||||
# TODO(newt): remove this once http://crbug.com/177552 is fixed in ninja.
|
||||
'--ignore=>!(echo \'>(_inputs)\' | md5sum)',
|
||||
]
|
||||
},
|
||||
{
|
||||
'variables': {
|
||||
'src_dirs': [
|
||||
'<(java_in_dir)/src',
|
||||
'>@(additional_src_dirs)',
|
||||
],
|
||||
'stamp_path': '<(lint_stamp)',
|
||||
'result_path': '<(lint_result)',
|
||||
'config_path': '<(lint_config)',
|
||||
},
|
||||
'inputs': [
|
||||
'<(compile_stamp)',
|
||||
],
|
||||
'outputs': [
|
||||
'<(lint_stamp)',
|
||||
],
|
||||
'includes': [ 'android/lint_action.gypi' ],
|
||||
},
|
||||
{
|
||||
'action_name': 'jar_<(_target_name)',
|
||||
'message': 'Creating <(_target_name) jar',
|
||||
'inputs': [
|
||||
'<(DEPTH)/build/android/gyp/util/build_utils.py',
|
||||
'<(DEPTH)/build/android/gyp/util/md5_check.py',
|
||||
'<(DEPTH)/build/android/gyp/jar.py',
|
||||
'<(compile_stamp)',
|
||||
],
|
||||
'outputs': [
|
||||
'<(javac_jar_path)',
|
||||
],
|
||||
'action': [
|
||||
'python', '<(DEPTH)/build/android/gyp/jar.py',
|
||||
'--classes-dir=<(classes_dir)',
|
||||
'--jar-path=<(javac_jar_path)',
|
||||
'--excluded-classes=<(jar_excluded_classes)',
|
||||
]
|
||||
},
|
||||
{
|
||||
'action_name': 'instr_jar_<(_target_name)',
|
||||
'message': 'Instrumenting <(_target_name) jar',
|
||||
'variables': {
|
||||
'input_path': '<(jar_path)',
|
||||
'output_path': '<(jar_final_path)',
|
||||
'stamp_path': '<(instr_stamp)',
|
||||
'instr_type': 'jar',
|
||||
},
|
||||
'outputs': [
|
||||
'<(jar_final_path)',
|
||||
],
|
||||
'inputs': [
|
||||
'<(jar_path)',
|
||||
],
|
||||
'includes': [ 'android/instr_action.gypi' ],
|
||||
},
|
||||
{
|
||||
'action_name': 'jar_toc_<(_target_name)',
|
||||
'message': 'Creating <(_target_name) jar.TOC',
|
||||
'inputs': [
|
||||
'<(DEPTH)/build/android/gyp/util/build_utils.py',
|
||||
'<(DEPTH)/build/android/gyp/util/md5_check.py',
|
||||
'<(DEPTH)/build/android/gyp/jar_toc.py',
|
||||
'<(jar_final_path)',
|
||||
],
|
||||
'outputs': [
|
||||
'<(jar_final_path).TOC',
|
||||
],
|
||||
'action': [
|
||||
'python', '<(DEPTH)/build/android/gyp/jar_toc.py',
|
||||
'--jar-path=<(jar_final_path)',
|
||||
'--toc-path=<(jar_final_path).TOC',
|
||||
]
|
||||
},
|
||||
{
|
||||
'action_name': 'dex_<(_target_name)',
|
||||
'variables': {
|
||||
'conditions': [
|
||||
['emma_instrument != 0', {
|
||||
'dex_no_locals': 1,
|
||||
}],
|
||||
],
|
||||
'dex_input_paths': [ '<(jar_final_path)' ],
|
||||
'output_path': '<(dex_path)',
|
||||
},
|
||||
'includes': [ 'android/dex_action.gypi' ],
|
||||
},
|
||||
],
|
||||
}
|
||||
@@ -0,0 +1,114 @@
|
||||
# Copyright 2013 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
|
||||
import functools
|
||||
import logging
|
||||
import os
|
||||
import shlex
|
||||
import sys
|
||||
|
||||
|
||||
def memoize(default=None):
|
||||
"""This decorator caches the return value of a parameterless pure function"""
|
||||
def memoizer(func):
|
||||
val = []
|
||||
@functools.wraps(func)
|
||||
def inner():
|
||||
if not val:
|
||||
ret = func()
|
||||
val.append(ret if ret is not None else default)
|
||||
if logging.getLogger().isEnabledFor(logging.INFO):
|
||||
print '%s -> %r' % (func.__name__, val[0])
|
||||
return val[0]
|
||||
return inner
|
||||
return memoizer
|
||||
|
||||
|
||||
@memoize()
|
||||
def IsWindows():
|
||||
return sys.platform in ['win32', 'cygwin']
|
||||
|
||||
|
||||
@memoize()
|
||||
def IsLinux():
|
||||
return sys.platform.startswith(('linux', 'freebsd'))
|
||||
|
||||
|
||||
@memoize()
|
||||
def IsMac():
|
||||
return sys.platform == 'darwin'
|
||||
|
||||
|
||||
@memoize()
|
||||
def gyp_defines():
|
||||
"""Parses and returns GYP_DEFINES env var as a dictionary."""
|
||||
return dict(arg.split('=', 1)
|
||||
for arg in shlex.split(os.environ.get('GYP_DEFINES', '')))
|
||||
|
||||
@memoize()
|
||||
def gyp_msvs_version():
|
||||
return os.environ.get('GYP_MSVS_VERSION', '')
|
||||
|
||||
@memoize()
|
||||
def distributor():
|
||||
"""
|
||||
Returns a string which is the distributed build engine in use (if any).
|
||||
Possible values: 'goma', 'ib', ''
|
||||
"""
|
||||
if 'goma' in gyp_defines():
|
||||
return 'goma'
|
||||
elif IsWindows():
|
||||
if 'CHROME_HEADLESS' in os.environ:
|
||||
return 'ib' # use (win and !goma and headless) as approximation of ib
|
||||
|
||||
|
||||
@memoize()
|
||||
def platform():
|
||||
"""
|
||||
Returns a string representing the platform this build is targetted for.
|
||||
Possible values: 'win', 'mac', 'linux', 'ios', 'android'
|
||||
"""
|
||||
if 'OS' in gyp_defines():
|
||||
if 'android' in gyp_defines()['OS']:
|
||||
return 'android'
|
||||
else:
|
||||
return gyp_defines()['OS']
|
||||
elif IsWindows():
|
||||
return 'win'
|
||||
elif IsLinux():
|
||||
return 'linux'
|
||||
else:
|
||||
return 'mac'
|
||||
|
||||
|
||||
@memoize()
|
||||
def builder():
|
||||
"""
|
||||
Returns a string representing the build engine (not compiler) to use.
|
||||
Possible values: 'make', 'ninja', 'xcode', 'msvs', 'scons'
|
||||
"""
|
||||
if 'GYP_GENERATORS' in os.environ:
|
||||
# for simplicity, only support the first explicit generator
|
||||
generator = os.environ['GYP_GENERATORS'].split(',')[0]
|
||||
if generator.endswith('-android'):
|
||||
return generator.split('-')[0]
|
||||
elif generator.endswith('-ninja'):
|
||||
return 'ninja'
|
||||
else:
|
||||
return generator
|
||||
else:
|
||||
if platform() == 'android':
|
||||
# Good enough for now? Do any android bots use make?
|
||||
return 'ninja'
|
||||
elif platform() == 'ios':
|
||||
return 'xcode'
|
||||
elif IsWindows():
|
||||
return 'ninja'
|
||||
elif IsLinux():
|
||||
return 'ninja'
|
||||
elif IsMac():
|
||||
return 'ninja'
|
||||
else:
|
||||
assert False, 'Don\'t know what builder we\'re using!'
|
||||
Executable
+132
@@ -0,0 +1,132 @@
|
||||
#!/usr/bin/env python
|
||||
# Copyright (c) 2012 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
"""
|
||||
This script runs every build as a hook. If it detects that the build should
|
||||
be clobbered, it will touch the file <build_dir>/.landmine_triggered. The
|
||||
various build scripts will then check for the presence of this file and clobber
|
||||
accordingly. The script will also emit the reasons for the clobber to stdout.
|
||||
|
||||
A landmine is tripped when a builder checks out a different revision, and the
|
||||
diff between the new landmines and the old ones is non-null. At this point, the
|
||||
build is clobbered.
|
||||
"""
|
||||
|
||||
import difflib
|
||||
import logging
|
||||
import optparse
|
||||
import os
|
||||
import sys
|
||||
import subprocess
|
||||
import time
|
||||
|
||||
import landmine_utils
|
||||
|
||||
|
||||
SRC_DIR = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
|
||||
|
||||
|
||||
def get_target_build_dir(build_tool, target, is_iphone=False):
|
||||
"""
|
||||
Returns output directory absolute path dependent on build and targets.
|
||||
Examples:
|
||||
r'c:\b\build\slave\win\build\src\out\Release'
|
||||
'/mnt/data/b/build/slave/linux/build/src/out/Debug'
|
||||
'/b/build/slave/ios_rel_device/build/src/xcodebuild/Release-iphoneos'
|
||||
|
||||
Keep this function in sync with tools/build/scripts/slave/compile.py
|
||||
"""
|
||||
ret = None
|
||||
if build_tool == 'xcode':
|
||||
ret = os.path.join(SRC_DIR, 'xcodebuild',
|
||||
target + ('-iphoneos' if is_iphone else ''))
|
||||
elif build_tool in ['make', 'ninja', 'ninja-ios']: # TODO: Remove ninja-ios.
|
||||
ret = os.path.join(SRC_DIR, 'out', target)
|
||||
elif build_tool in ['msvs', 'vs', 'ib']:
|
||||
ret = os.path.join(SRC_DIR, 'build', target)
|
||||
else:
|
||||
raise NotImplementedError('Unexpected GYP_GENERATORS (%s)' % build_tool)
|
||||
return os.path.abspath(ret)
|
||||
|
||||
|
||||
def set_up_landmines(target, new_landmines):
|
||||
"""Does the work of setting, planting, and triggering landmines."""
|
||||
out_dir = get_target_build_dir(landmine_utils.builder(), target,
|
||||
landmine_utils.platform() == 'ios')
|
||||
|
||||
landmines_path = os.path.join(out_dir, '.landmines')
|
||||
if not os.path.exists(out_dir):
|
||||
os.makedirs(out_dir)
|
||||
|
||||
if not os.path.exists(landmines_path):
|
||||
with open(landmines_path, 'w') as f:
|
||||
f.writelines(new_landmines)
|
||||
else:
|
||||
triggered = os.path.join(out_dir, '.landmines_triggered')
|
||||
with open(landmines_path, 'r') as f:
|
||||
old_landmines = f.readlines()
|
||||
if old_landmines != new_landmines:
|
||||
old_date = time.ctime(os.stat(landmines_path).st_ctime)
|
||||
diff = difflib.unified_diff(old_landmines, new_landmines,
|
||||
fromfile='old_landmines', tofile='new_landmines',
|
||||
fromfiledate=old_date, tofiledate=time.ctime(), n=0)
|
||||
|
||||
with open(triggered, 'w') as f:
|
||||
f.writelines(diff)
|
||||
elif os.path.exists(triggered):
|
||||
# Remove false triggered landmines.
|
||||
os.remove(triggered)
|
||||
|
||||
|
||||
def process_options():
|
||||
"""Returns a list of landmine emitting scripts."""
|
||||
parser = optparse.OptionParser()
|
||||
parser.add_option(
|
||||
'-s', '--landmine-scripts', action='append',
|
||||
default=[os.path.join(SRC_DIR, 'build', 'get_landmines.py')],
|
||||
help='Path to the script which emits landmines to stdout. The target '
|
||||
'is passed to this script via option -t. Note that an extra '
|
||||
'script can be specified via an env var EXTRA_LANDMINES_SCRIPT.')
|
||||
parser.add_option('-v', '--verbose', action='store_true',
|
||||
default=('LANDMINES_VERBOSE' in os.environ),
|
||||
help=('Emit some extra debugging information (default off). This option '
|
||||
'is also enabled by the presence of a LANDMINES_VERBOSE environment '
|
||||
'variable.'))
|
||||
|
||||
options, args = parser.parse_args()
|
||||
|
||||
if args:
|
||||
parser.error('Unknown arguments %s' % args)
|
||||
|
||||
logging.basicConfig(
|
||||
level=logging.DEBUG if options.verbose else logging.ERROR)
|
||||
|
||||
extra_script = os.environ.get('EXTRA_LANDMINES_SCRIPT')
|
||||
if extra_script:
|
||||
return options.landmine_scripts + [extra_script]
|
||||
else:
|
||||
return options.landmine_scripts
|
||||
|
||||
|
||||
def main():
|
||||
landmine_scripts = process_options()
|
||||
|
||||
if landmine_utils.builder() == 'dump_dependency_json':
|
||||
return 0
|
||||
|
||||
for target in ('Debug', 'Release', 'Debug_x64', 'Release_x64'):
|
||||
landmines = []
|
||||
for s in landmine_scripts:
|
||||
proc = subprocess.Popen([sys.executable, s, '-t', target],
|
||||
stdout=subprocess.PIPE)
|
||||
output, _ = proc.communicate()
|
||||
landmines.extend([('%s\n' % l.strip()) for l in output.splitlines()])
|
||||
set_up_landmines(target, landmines)
|
||||
|
||||
return 0
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
sys.exit(main())
|
||||
Executable
+55
@@ -0,0 +1,55 @@
|
||||
#!/bin/sh
|
||||
#
|
||||
# Copyright 2013 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
# Author: morlovich@google.com (Maksim Orlovich)
|
||||
#
|
||||
# Determine last git revision containing an actual change on a given branch
|
||||
# Usage: lastchange.sh gitpath [-d default_file] [-o out_file]
|
||||
set -e
|
||||
set -u
|
||||
|
||||
SVN_PATH=$1
|
||||
shift 1
|
||||
DEFAULT_FILE=
|
||||
OUT_FILE=/dev/stdout
|
||||
|
||||
while [ $# -ge 2 ]; do
|
||||
case $1 in
|
||||
-d)
|
||||
# -d has no effect if file doesn't exist.
|
||||
if [ -f $2 ]; then
|
||||
DEFAULT_FILE=$2
|
||||
fi
|
||||
shift 2
|
||||
;;
|
||||
-o)
|
||||
OUT_FILE=$2
|
||||
shift 2
|
||||
;;
|
||||
*)
|
||||
echo "Usage: lastchange.sh gitpath [-d default_file] [-o out_file]"
|
||||
exit 1
|
||||
;;
|
||||
esac
|
||||
done
|
||||
|
||||
if [ -z $DEFAULT_FILE ]; then
|
||||
KEY='Last Changed Rev: '
|
||||
REVISION=$(git rev-list --all --count)
|
||||
echo LASTCHANGE=$REVISION > $OUT_FILE
|
||||
else
|
||||
cat $DEFAULT_FILE > $OUT_FILE
|
||||
fi
|
||||
Executable
+25
@@ -0,0 +1,25 @@
|
||||
# Copyright 2013 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
# Author: morlovich@google.com (Maksim Orlovich)
|
||||
#
|
||||
# This simply forwards to the Chromium's lastchange.py script, but runs it
|
||||
# from the mod_pagespeed repo so it gets the mod_pagespeed revision and not
|
||||
# the chromium one.
|
||||
import sys
|
||||
sys.path.append('util')
|
||||
from lastchange import main
|
||||
|
||||
if __name__ == '__main__':
|
||||
sys.exit(main())
|
||||
@@ -0,0 +1,170 @@
|
||||
# Copyright (c) 2012 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
{
|
||||
'targets': [
|
||||
{
|
||||
'target_name': 'libwebp_dec',
|
||||
'type': 'static_library',
|
||||
'dependencies' : [
|
||||
'libwebp_dsp',
|
||||
'libwebp_dsp_neon',
|
||||
'libwebp_mux',
|
||||
'libwebp_utils',
|
||||
],
|
||||
'sources': [
|
||||
'<(DEPTH)/third_party/libwebp/src/dec/alpha.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dec/buffer.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dec/frame.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dec/idec.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dec/io.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dec/quant.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dec/tree.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dec/vp8.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dec/vp8l.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dec/webp.c',
|
||||
],
|
||||
'direct_dependent_settings': {
|
||||
'include_dirs': [
|
||||
'<(DEPTH)/third_party/libwebp/src/webp'
|
||||
],
|
||||
},
|
||||
},
|
||||
{
|
||||
'target_name': 'libwebp_dsp',
|
||||
'type': 'static_library',
|
||||
'sources': [
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/alpha_processing.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/alpha_processing_mips_dsp_r2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/alpha_processing_sse2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/alpha_processing_sse41.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/argb.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/argb_mips_dsp_r2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/argb_sse2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/cost.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/cost_mips32.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/cost_mips_dsp_r2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/cost_sse2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/cpu.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/dec.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/dec_clip_tables.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/dec_mips32.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/dec_mips_dsp_r2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/dec_sse2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/dec_sse41.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/enc.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/enc_avx2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/enc_mips32.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/enc_mips_dsp_r2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/enc_sse2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/enc_sse41.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/filters.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/filters_mips_dsp_r2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/filters_sse2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/lossless.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/lossless_enc.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/lossless_enc_mips32.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/lossless_enc_mips_dsp_r2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/lossless_enc_sse2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/lossless_enc_sse41.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/lossless_mips_dsp_r2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/lossless_sse2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/rescaler.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/rescaler_mips32.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/rescaler_mips_dsp_r2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/rescaler_sse2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/upsampling.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/upsampling_mips_dsp_r2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/upsampling_sse2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/yuv.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/yuv_mips32.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/yuv_mips_dsp_r2.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/yuv_sse2.c',
|
||||
],
|
||||
},
|
||||
{
|
||||
'target_name': 'libwebp_dsp_neon',
|
||||
'type': 'static_library',
|
||||
'sources': [
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/dec_neon.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/enc_neon.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/lossless_enc_neon.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/lossless_neon.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/rescaler_neon.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/dsp/upsampling_neon.c',
|
||||
],
|
||||
},
|
||||
{
|
||||
'target_name': 'libwebp_enc',
|
||||
'type': 'static_library',
|
||||
# note these dependencies are shared with libwebp_dec, if they are merged
|
||||
# into each lib causing duplicate symbol issues when both are used then
|
||||
# the deps could be split to enc/dec parts or a combined libwebp target
|
||||
# could be added similar to chrome.
|
||||
'dependencies' : [
|
||||
'libwebp_dsp',
|
||||
'libwebp_dsp_neon',
|
||||
'libwebp_mux',
|
||||
'libwebp_utils',
|
||||
],
|
||||
'sources': [
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/alpha.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/analysis.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/backward_references.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/config.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/cost.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/delta_palettization.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/filter.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/frame.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/histogram.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/iterator.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/near_lossless.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/picture.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/picture_csp.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/picture_psnr.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/picture_rescale.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/picture_tools.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/quant.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/syntax.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/token.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/tree.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/vp8l.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/enc/webpenc.c',
|
||||
],
|
||||
'direct_dependent_settings': {
|
||||
'include_dirs': [
|
||||
'<(DEPTH)/third_party/libwebp/src/webp'
|
||||
],
|
||||
},
|
||||
},
|
||||
{
|
||||
'target_name': 'libwebp_utils',
|
||||
'type': 'static_library',
|
||||
'sources': [
|
||||
'<(DEPTH)/third_party/libwebp/src/utils/bit_reader.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/utils/bit_writer.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/utils/color_cache.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/utils/filters.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/utils/huffman.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/utils/huffman_encode.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/utils/quant_levels.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/utils/quant_levels_dec.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/utils/random.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/utils/rescaler.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/utils/thread.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/utils/utils.c',
|
||||
],
|
||||
},
|
||||
{
|
||||
'target_name': 'libwebp_mux',
|
||||
'type': 'static_library',
|
||||
'sources': [
|
||||
'<(DEPTH)/third_party/libwebp/src/mux/anim_encode.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/mux/muxedit.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/mux/muxinternal.c',
|
||||
'<(DEPTH)/third_party/libwebp/src/mux/muxread.c',
|
||||
],
|
||||
},
|
||||
],
|
||||
}
|
||||
@@ -0,0 +1,35 @@
|
||||
#!/usr/bin/env python
|
||||
# Copyright 2014 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
"""Outputs host CPU architecture in format recognized by gyp."""
|
||||
|
||||
import platform
|
||||
import re
|
||||
import sys
|
||||
|
||||
|
||||
def main():
|
||||
host_arch = platform.machine()
|
||||
|
||||
# Convert machine type to format recognized by gyp.
|
||||
if re.match(r'i.86', host_arch) or host_arch == 'i86pc':
|
||||
host_arch = 'ia32'
|
||||
elif host_arch in ['x86_64', 'amd64']:
|
||||
host_arch = 'x64'
|
||||
elif host_arch.startswith('arm'):
|
||||
host_arch = 'arm'
|
||||
|
||||
# platform.machine is based on running kernel. It's possible to use 64-bit
|
||||
# kernel with 32-bit userland, e.g. to give linker slightly more memory.
|
||||
# Distinguish between different userland bitness by querying
|
||||
# the python binary.
|
||||
if host_arch == 'x64' and platform.architecture()[0] == '32bit':
|
||||
host_arch = 'ia32'
|
||||
|
||||
print host_arch
|
||||
return 0
|
||||
|
||||
if __name__ == '__main__':
|
||||
sys.exit(main())
|
||||
@@ -0,0 +1,33 @@
|
||||
# Copyright (c) 2010 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
{
|
||||
'type': 'none',
|
||||
'dependencies': [
|
||||
'all.gyp:All',
|
||||
'linux_installer_configs',
|
||||
],
|
||||
'actions': [
|
||||
{
|
||||
'action_name': 'linux_package_deb_<(channel)_action',
|
||||
'process_outputs_as_sources': 1,
|
||||
'inputs': [
|
||||
'<(deb_build)',
|
||||
'<@(packaging_files_binaries)',
|
||||
'<@(packaging_files_common)',
|
||||
'<@(packaging_files_deb)',
|
||||
],
|
||||
'outputs': [
|
||||
'<(PRODUCT_DIR)/mod-pagespeed-<(channel)-<(version)-r<(revision)_<(deb_arch).deb',
|
||||
],
|
||||
'action': [ '<@(deb_cmd)', '-c', '<(channel)', ],
|
||||
},
|
||||
],
|
||||
}
|
||||
|
||||
# Local Variables:
|
||||
# tab-width:2
|
||||
# indent-tabs-mode:nil
|
||||
# End:
|
||||
# vim: set expandtab tabstop=2 shiftwidth=2:
|
||||
@@ -0,0 +1,34 @@
|
||||
# Copyright (c) 2010 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
|
||||
{
|
||||
'type': 'none',
|
||||
'dependencies': [
|
||||
'all.gyp:All',
|
||||
'linux_installer_configs',
|
||||
],
|
||||
'actions': [
|
||||
{
|
||||
'action_name': 'linux_package_deb_<(channel)_action',
|
||||
'process_outputs_as_sources': 1,
|
||||
'inputs': [
|
||||
'<(rpm_build)',
|
||||
'<(PRODUCT_DIR)/install/rpm/mod-pagespeed.spec.template',
|
||||
'<@(packaging_files_binaries)',
|
||||
'<@(packaging_files_common)',
|
||||
'<@(packaging_files_rpm)',
|
||||
],
|
||||
'outputs': [
|
||||
'<(PRODUCT_DIR)/mod-pagespeed-<(channel)-<(version)-r<(revision).<(rpm_arch).rpm',
|
||||
],
|
||||
'action': [ '<@(rpm_cmd)', '-c', '<(channel)', ],
|
||||
},
|
||||
],
|
||||
}
|
||||
|
||||
# Local Variables:
|
||||
# tab-width:2
|
||||
# indent-tabs-mode:nil
|
||||
# End:
|
||||
# vim: set expandtab tabstop=2 shiftwidth=2:
|
||||
@@ -0,0 +1,5 @@
|
||||
{
|
||||
/* Make sure we don't export anything unneeded */
|
||||
global: pagespeed_module;
|
||||
local: *;
|
||||
};
|
||||
@@ -0,0 +1,17 @@
|
||||
<?xml version="1.0" encoding="utf-8"?>
|
||||
<VisualStudioToolFile
|
||||
Name="Output DLL copy"
|
||||
Version="8.00"
|
||||
>
|
||||
<Rules>
|
||||
<CustomBuildRule
|
||||
Name="Output DLL copy"
|
||||
CommandLine="xcopy /R /C /Y $(InputPath) $(OutDir)"
|
||||
Outputs="$(OutDir)\$(InputFileName)"
|
||||
FileExtensions="*.dll"
|
||||
>
|
||||
<Properties>
|
||||
</Properties>
|
||||
</CustomBuildRule>
|
||||
</Rules>
|
||||
</VisualStudioToolFile>
|
||||
@@ -0,0 +1,139 @@
|
||||
# Copyright 2013 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
# PageSpeed overrides for Chromium's common.gypi.
|
||||
{
|
||||
'variables': {
|
||||
# Putting a variables dict inside another variables dict looks
|
||||
# kind of weird. This is done so that some variables are defined
|
||||
# as variables within the outer variables dict here. This is
|
||||
# necessary to get these variables defined for the conditions
|
||||
# within this variables dict that operate on these variables.
|
||||
'variables': {
|
||||
# Whether or not we are building for native client.
|
||||
'build_nacl%': 0,
|
||||
},
|
||||
|
||||
# Copy conditionally-set variables out one scope.
|
||||
'build_nacl%': '<(build_nacl)',
|
||||
|
||||
# Conditions that operate on our variables defined above.
|
||||
'conditions': [
|
||||
['build_nacl==1', {
|
||||
# Disable position-independent code when building under Native
|
||||
# Client.
|
||||
'linux_fpic': 0,
|
||||
}],
|
||||
],
|
||||
|
||||
|
||||
# Override a few Chromium variables:
|
||||
|
||||
# Chromium uses system shared libraries on Linux by default
|
||||
# (Chromium already has transitive dependencies on these libraries
|
||||
# via gtk). We want to link these libraries into our binaries so
|
||||
# we change the default behavior.
|
||||
'use_system_libjpeg': 0,
|
||||
'use_system_libpng': 0,
|
||||
'use_system_zlib': 0,
|
||||
|
||||
# We don't use google API keys in the PageSpeed build, so disable them.
|
||||
'use_official_google_api_keys': 0,
|
||||
|
||||
# Disable the chromium linting plugins since our code doesn't
|
||||
# (yet) meet their requirements.
|
||||
'clang_use_chrome_plugins': 0,
|
||||
|
||||
# Disable use of special ld gold flags, since it isn't installed
|
||||
# by default.
|
||||
'linux_use_gold_binary': 0,
|
||||
'linux_use_gold_flags': 0,
|
||||
},
|
||||
'target_defaults': {
|
||||
# Make sure our shadow view of chromium source is available to
|
||||
# targets that don't explicitly declare their dependencies and
|
||||
# assume chromium source headers are available from the root
|
||||
# (third_party/modp_b64 is one such target).
|
||||
'include_dirs': [
|
||||
'<(DEPTH)/third_party/chromium/src',
|
||||
],
|
||||
|
||||
# ABI-incompatible changes are trouble when you have a library, so turn off
|
||||
# _GLIBCXX_DEBUG --- it makes various STL objects have different types and
|
||||
# sizes.
|
||||
'defines!': [
|
||||
'_GLIBCXX_DEBUG=1'
|
||||
],
|
||||
},
|
||||
'conditions': [
|
||||
['build_nacl==1', {
|
||||
'target_defaults': {
|
||||
'defines': [
|
||||
# NaCL newlib's libpthread.a provides the
|
||||
# GetRunningOnValgrind symbol already, so we should not
|
||||
# provide it.
|
||||
'DYNAMIC_ANNOTATIONS_PROVIDE_RUNNING_ON_VALGRIND=0',
|
||||
],
|
||||
'include_dirs': [
|
||||
'<(DEPTH)/build/nacl_header_stubs',
|
||||
],
|
||||
},
|
||||
}],
|
||||
['os_posix==1 and OS!="mac"', {
|
||||
'target_defaults': {
|
||||
'ldflags': [
|
||||
# Fail to link if there are any undefined symbols.
|
||||
'-Wl,-z,defs',
|
||||
],
|
||||
}
|
||||
}],
|
||||
['OS=="mac"', {
|
||||
'target_defaults': {
|
||||
'xcode_settings': {
|
||||
'conditions': [
|
||||
['clang==1', {
|
||||
# Chromium's common.gypi does not currently scope the
|
||||
# clang binary paths relative to DEPTH, so we must
|
||||
# override the paths here.
|
||||
'CC': '$(SOURCE_ROOT)/<(DEPTH)/third_party/llvm-build/Release+Asserts/bin/clang',
|
||||
'LDPLUSPLUS': '$(SOURCE_ROOT)/<(DEPTH)/third_party/llvm-build/Release+Asserts/bin/clang++',
|
||||
}],
|
||||
]
|
||||
},
|
||||
},
|
||||
}],
|
||||
['OS=="win"', {
|
||||
'target_defaults': {
|
||||
# Remove the following defines, which are normally defined by
|
||||
# Chromium's common.gypi.
|
||||
'defines!': [
|
||||
# Chromium's common.gypi disables tr1. We need it for tr1
|
||||
# regex so remove their define to disable it.
|
||||
'_HAS_TR1=0',
|
||||
|
||||
# Chromium disables exceptions in some environments, but our
|
||||
# use of tr1 regex requires exception support, so we have to
|
||||
# re-enable it here.
|
||||
'_HAS_EXCEPTIONS=0',
|
||||
],
|
||||
'msvs_settings': {
|
||||
'VCCLCompilerTool': {
|
||||
'ExceptionHandling': '1', # /EHsc
|
||||
},
|
||||
},
|
||||
},
|
||||
}]
|
||||
],
|
||||
}
|
||||
|
||||
@@ -0,0 +1,17 @@
|
||||
{
|
||||
'conditions': [
|
||||
# Handle build types.
|
||||
['buildtype=="Dev"', {
|
||||
'includes': ['internal/release_impl.gypi'],
|
||||
}],
|
||||
['buildtype=="Official"', {
|
||||
'includes': ['internal/release_impl_official.gypi'],
|
||||
}],
|
||||
# TODO(bradnelson): may also need:
|
||||
# checksenabled
|
||||
# coverage
|
||||
# dom_stats
|
||||
# pgo_instrument
|
||||
# pgo_optimize
|
||||
],
|
||||
}
|
||||
Executable
+201
@@ -0,0 +1,201 @@
|
||||
#!/usr/bin/env python
|
||||
# Copyright 2014 The Chromium Authors. All rights reserved.
|
||||
# Use of this source code is governed by a BSD-style license that can be
|
||||
# found in the LICENSE file.
|
||||
# (See http://src.chromium.org/viewvc/chrome/trunk/src/LICENSE)
|
||||
# This file itself is from
|
||||
# http://src.chromium.org/viewvc/chrome/trunk/src/build/util/ as of
|
||||
# revision r252481
|
||||
|
||||
"""
|
||||
version.py -- Chromium version string substitution utility.
|
||||
"""
|
||||
|
||||
import getopt
|
||||
import os
|
||||
import sys
|
||||
|
||||
|
||||
class Usage(Exception):
|
||||
def __init__(self, msg):
|
||||
self.msg = msg
|
||||
|
||||
|
||||
def fetch_values_from_file(values_dict, file_name):
|
||||
"""
|
||||
Fetches KEYWORD=VALUE settings from the specified file.
|
||||
|
||||
Everything to the left of the first '=' is the keyword,
|
||||
everything to the right is the value. No stripping of
|
||||
white space, so beware.
|
||||
|
||||
The file must exist, otherwise you get the Python exception from open().
|
||||
"""
|
||||
for line in open(file_name, 'r').readlines():
|
||||
key, val = line.rstrip('\r\n').split('=', 1)
|
||||
values_dict[key] = val
|
||||
|
||||
|
||||
def fetch_values(file_list):
|
||||
"""
|
||||
Returns a dictionary of values to be used for substitution, populating
|
||||
the dictionary with KEYWORD=VALUE settings from the files in 'file_list'.
|
||||
|
||||
Explicitly adds the following value from internal calculations:
|
||||
|
||||
OFFICIAL_BUILD
|
||||
"""
|
||||
CHROME_BUILD_TYPE = os.environ.get('CHROME_BUILD_TYPE')
|
||||
if CHROME_BUILD_TYPE == '_official':
|
||||
official_build = '1'
|
||||
else:
|
||||
official_build = '0'
|
||||
|
||||
values = dict(
|
||||
OFFICIAL_BUILD = official_build,
|
||||
)
|
||||
|
||||
for file_name in file_list:
|
||||
fetch_values_from_file(values, file_name)
|
||||
|
||||
return values
|
||||
|
||||
|
||||
def subst_template(contents, values):
|
||||
"""
|
||||
Returns the template with substituted values from the specified dictionary.
|
||||
|
||||
Keywords to be substituted are surrounded by '@': @KEYWORD@.
|
||||
|
||||
No attempt is made to avoid recursive substitution. The order
|
||||
of evaluation is random based on the order of the keywords returned
|
||||
by the Python dictionary. So do NOT substitute a value that
|
||||
contains any @KEYWORD@ strings expecting them to be recursively
|
||||
substituted, okay?
|
||||
"""
|
||||
for key, val in values.iteritems():
|
||||
try:
|
||||
contents = contents.replace('@' + key + '@', val)
|
||||
except TypeError:
|
||||
print repr(key), repr(val)
|
||||
return contents
|
||||
|
||||
|
||||
def subst_file(file_name, values):
|
||||
"""
|
||||
Returns the contents of the specified file_name with substited
|
||||
values from the specified dictionary.
|
||||
|
||||
This is like subst_template, except it operates on a file.
|
||||
"""
|
||||
template = open(file_name, 'r').read()
|
||||
return subst_template(template, values);
|
||||
|
||||
|
||||
def write_if_changed(file_name, contents):
|
||||
"""
|
||||
Writes the specified contents to the specified file_name
|
||||
iff the contents are different than the current contents.
|
||||
"""
|
||||
try:
|
||||
old_contents = open(file_name, 'r').read()
|
||||
except EnvironmentError:
|
||||
pass
|
||||
else:
|
||||
if contents == old_contents:
|
||||
return
|
||||
os.unlink(file_name)
|
||||
open(file_name, 'w').write(contents)
|
||||
|
||||
|
||||
def main(argv=None):
|
||||
if argv is None:
|
||||
argv = sys.argv
|
||||
|
||||
short_options = 'e:f:i:o:t:h'
|
||||
long_options = ['eval=', 'file=', 'help']
|
||||
|
||||
helpstr = """\
|
||||
Usage: version.py [-h] [-f FILE] ([[-i] FILE] | -t TEMPLATE) [[-o] FILE]
|
||||
|
||||
-f FILE, --file=FILE Read variables from FILE.
|
||||
-i FILE, --input=FILE Read strings to substitute from FILE.
|
||||
-o FILE, --output=FILE Write substituted strings to FILE.
|
||||
-t TEMPLATE, --template=TEMPLATE Use TEMPLATE as the strings to substitute.
|
||||
-e VAR=VAL, --eval=VAR=VAL Evaluate VAL after reading variables. Can
|
||||
be used to synthesize variables. e.g.
|
||||
-e 'PATCH_HI=int(PATCH)/256'.
|
||||
-h, --help Print this help and exit.
|
||||
"""
|
||||
|
||||
evals = {}
|
||||
variable_files = []
|
||||
in_file = None
|
||||
out_file = None
|
||||
template = None
|
||||
|
||||
try:
|
||||
try:
|
||||
opts, args = getopt.getopt(argv[1:], short_options, long_options)
|
||||
except getopt.error, msg:
|
||||
raise Usage(msg)
|
||||
for o, a in opts:
|
||||
if o in ('-e', '--eval'):
|
||||
try:
|
||||
evals.update(dict([a.split('=',1)]))
|
||||
except ValueError:
|
||||
raise Usage("-e requires VAR=VAL")
|
||||
elif o in ('-f', '--file'):
|
||||
variable_files.append(a)
|
||||
elif o in ('-i', '--input'):
|
||||
in_file = a
|
||||
elif o in ('-o', '--output'):
|
||||
out_file = a
|
||||
elif o in ('-t', '--template'):
|
||||
template = a
|
||||
elif o in ('-h', '--help'):
|
||||
print helpstr
|
||||
return 0
|
||||
while len(args) and (in_file is None or out_file is None or
|
||||
template is None):
|
||||
if in_file is None:
|
||||
in_file = args.pop(0)
|
||||
elif out_file is None:
|
||||
out_file = args.pop(0)
|
||||
if args:
|
||||
msg = 'Unexpected arguments: %r' % args
|
||||
raise Usage(msg)
|
||||
except Usage, err:
|
||||
sys.stderr.write(err.msg)
|
||||
sys.stderr.write('; Use -h to get help.\n')
|
||||
return 2
|
||||
|
||||
values = fetch_values(variable_files)
|
||||
for key, val in evals.iteritems():
|
||||
values[key] = str(eval(val, globals(), values))
|
||||
|
||||
if template is not None:
|
||||
contents = subst_template(template, values)
|
||||
elif in_file:
|
||||
contents = subst_file(in_file, values)
|
||||
else:
|
||||
# Generate a default set of version information.
|
||||
contents = """MAJOR=%(MAJOR)s
|
||||
MINOR=%(MINOR)s
|
||||
BUILD=%(BUILD)s
|
||||
PATCH=%(PATCH)s
|
||||
LASTCHANGE=%(LASTCHANGE)s
|
||||
OFFICIAL_BUILD=%(OFFICIAL_BUILD)s
|
||||
""" % values
|
||||
|
||||
|
||||
if out_file:
|
||||
write_if_changed(out_file, contents)
|
||||
else:
|
||||
print contents
|
||||
|
||||
return 0
|
||||
|
||||
|
||||
if __name__ == '__main__':
|
||||
sys.exit(main())
|
||||
@@ -1,355 +0,0 @@
|
||||
# Copyright 2012 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
# Environment Variables (Optional):
|
||||
# MOD_PAGESPEED_DIR: absolute path to the mod_pagespeed/src directory
|
||||
# PSOL_BINARY: absolute path to pagespeed_automatic.a
|
||||
|
||||
mod_pagespeed_dir="${MOD_PAGESPEED_DIR:-unset}"
|
||||
position_aux="${POSITION_AUX:-unset}"
|
||||
|
||||
if [ "$mod_pagespeed_dir" = "unset" ] ; then
|
||||
mod_pagespeed_dir="$ngx_addon_dir/psol/include"
|
||||
build_from_source=false
|
||||
|
||||
if [ ! -e "$mod_pagespeed_dir" ] ; then
|
||||
echo "ngx_pagespeed: pagespeed optimization library not found:"
|
||||
echo ""
|
||||
echo " You need to separately download the pagespeed library:"
|
||||
echo ""
|
||||
echo " $ cd /path/to/ngx_pagespeed"
|
||||
echo " $ wget https://dl.google.com/dl/page-speed/psol/1.10.33.7.tar.gz"
|
||||
echo " $ tar -xzvf 1.10.33.7.tar.gz # expands to psol/"
|
||||
echo ""
|
||||
echo " Or see the installation instructions:"
|
||||
echo " https://github.com/pagespeed/ngx_pagespeed#how-to-build"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
else
|
||||
build_from_source=true
|
||||
fi
|
||||
|
||||
os_name='unknown_os'
|
||||
arch_name='unknown_arch'
|
||||
uname_os=`uname`
|
||||
uname_arch=`uname -m`
|
||||
|
||||
if [ $uname_os = 'Linux' ]; then
|
||||
os_name='linux'
|
||||
elif [ $uname_os = 'Darwin' ]; then
|
||||
os_name='mac'
|
||||
else
|
||||
echo "OS not supported: $uname_os"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ $uname_arch = 'x86_64' -o $uname_arch = 'amd64' ]; then
|
||||
arch_name='x64'
|
||||
elif [ $uname_arch = 'x86_32' -o $uname_arch = 'i686' \
|
||||
-o $uname_arch = 'i386' ]; then
|
||||
arch_name='ia32'
|
||||
else
|
||||
echo "Architecture not supported: $uname_arch"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ "$NGX_DEBUG" = "YES" ]; then
|
||||
buildtype=Debug
|
||||
else
|
||||
buildtype=Release
|
||||
fi
|
||||
|
||||
# If the compiler is gcc, we want to use g++ to link, if at all possible,
|
||||
# so that -static-libstdc++ works.
|
||||
# Annoyingly, the feature test doesn't even use $LINK for linking, so that
|
||||
# needs an explicit -lstdc++
|
||||
pagespeed_libs=
|
||||
ps_maybe_gpp_base=`basename $CC| sed s/gcc/g++/`
|
||||
ps_maybe_gpp="`dirname $CC`/$ps_maybe_gpp_base"
|
||||
if [ -n "$NGX_GCC_VER" -a \( -x "$ps_maybe_gpp" \) ]; then
|
||||
LINK=$ps_maybe_gpp
|
||||
NGX_TEST_LD_OPT="$NGX_TEST_LD_OPT -lstdc++"
|
||||
else
|
||||
pagespeed_libs="-lstdc++"
|
||||
fi
|
||||
|
||||
# The compiler needs to know that __sync_add_and_fetch_4 is ok,
|
||||
# and this requires an instruction that didn't exist on i586 or i386.
|
||||
if [ "$uname_arch" = "i686" ]; then
|
||||
FLAG_MARCH='-march=i686'
|
||||
fi
|
||||
|
||||
CFLAGS="$CFLAGS $FLAG_MARCH"
|
||||
|
||||
# For now, standardize on gcc-4.x ABI --- if we don't set this, people building
|
||||
# with new gcc defaulting to gcc-5 C++11 ABI will have build trouble linking
|
||||
# to our libpsol.a
|
||||
# See https://gcc.gnu.org/onlinedocs/libstdc++/manual/using_dual_abi.html
|
||||
CFLAGS="$CFLAGS -D_GLIBCXX_USE_CXX11_ABI=0"
|
||||
CC_TEST_FLAGS="$CC_TEST_FLAGS -D_GLIBCXX_USE_CXX11_ABI=0"
|
||||
|
||||
case "$NGX_GCC_VER" in
|
||||
4.8*)
|
||||
# On GCC 4.8 and above, -Wall enables -Wunused-local-typedefs. This breaks
|
||||
# on VerifySizesAreEqual in bit_cast in chromium/src/base/basictypes.h which
|
||||
# has a typedef that is intentionally unused.
|
||||
CFLAGS="$CFLAGS -Wno-unused-local-typedefs"
|
||||
|
||||
# On GCC 4.8 and above, we get the following compiler warning:
|
||||
# chromium/src/base/memory/scoped_ptr.h:133:7: warning: declaration of ‘class scoped_ptr<C>’ [enabled by default]
|
||||
# Based on discussion at http://gcc.gnu.org/bugzilla/show_bug.cgi?id=54055,
|
||||
# this is invalid code, but hasn't been fixed yet in chromium.
|
||||
# Unfortunately, there also does not appear to be a flag for just disabling
|
||||
# that warning, so we add Wno-error to override nginx's default -Werror
|
||||
# option.
|
||||
CFLAGS="$CFLAGS -Wno-error"
|
||||
;;
|
||||
esac
|
||||
|
||||
# workaround for a bug in nginx-1.9.11, see:
|
||||
# http://hg.nginx.org/nginx/rev/ff1e625ae55b
|
||||
NGX_VERSION=`grep nginx_version src/core/nginx.h | sed -e 's/^.* \(.*\)$/\1/'`
|
||||
if [ "$NGX_VERSION" = "1009011" ]; then
|
||||
CFLAGS="$CFLAGS -Wno-write-strings"
|
||||
fi
|
||||
|
||||
if [ "$WNO_ERROR" = "YES" ]; then
|
||||
CFLAGS="$CFLAGS -Wno-error"
|
||||
fi
|
||||
|
||||
psol_binary="${PSOL_BINARY:-unset}"
|
||||
if [ "$psol_binary" = "unset" ] ; then
|
||||
if $build_from_source ; then
|
||||
psol_binary="\
|
||||
$mod_pagespeed_dir/pagespeed/automatic/pagespeed_automatic.a"
|
||||
else
|
||||
psol_library_dir="$ngx_addon_dir/psol/lib/$buildtype/$os_name/$arch_name"
|
||||
psol_binary="$psol_library_dir/pagespeed_automatic.a"
|
||||
fi
|
||||
fi
|
||||
|
||||
echo "mod_pagespeed_dir=$mod_pagespeed_dir"
|
||||
echo "build_from_source=$build_from_source"
|
||||
|
||||
ngx_feature="psol"
|
||||
ngx_feature_name=""
|
||||
ngx_feature_run=no
|
||||
ngx_feature_incs="
|
||||
#include \"pagespeed/kernel/base/string.h\"
|
||||
#include \"pagespeed/kernel/base/string_writer.h\"
|
||||
#include \"pagespeed/kernel/base/null_message_handler.h\"
|
||||
#include \"pagespeed/kernel/html/html_parse.h\"
|
||||
#include \"pagespeed/kernel/html/html_writer_filter.h\"
|
||||
"
|
||||
|
||||
pagespeed_include="\
|
||||
$mod_pagespeed_dir \
|
||||
$mod_pagespeed_dir/third_party/chromium/src \
|
||||
$mod_pagespeed_dir/third_party/google-sparsehash/src \
|
||||
$mod_pagespeed_dir/third_party/google-sparsehash/gen/arch/$os_name/$arch_name/include \
|
||||
$mod_pagespeed_dir/third_party/protobuf/src \
|
||||
$mod_pagespeed_dir/third_party/re2/src \
|
||||
$mod_pagespeed_dir/out/$buildtype/obj/gen \
|
||||
$mod_pagespeed_dir/out/$buildtype/obj/gen/protoc_out/instaweb \
|
||||
$mod_pagespeed_dir/third_party/apr/src/include \
|
||||
$mod_pagespeed_dir/third_party/aprutil/src/include \
|
||||
$mod_pagespeed_dir/third_party/apr/gen/arch/$os_name/$arch_name/include \
|
||||
$mod_pagespeed_dir/third_party/aprutil/gen/arch/$os_name/$arch_name/include"
|
||||
ngx_feature_path="$pagespeed_include"
|
||||
|
||||
pagespeed_libs="$pagespeed_libs $psol_binary -lrt -pthread -lm"
|
||||
ngx_feature_libs="$pagespeed_libs"
|
||||
ngx_feature_test="
|
||||
|
||||
GoogleString output_buffer;
|
||||
net_instaweb::StringWriter write_to_string(&output_buffer);
|
||||
|
||||
net_instaweb::NullMessageHandler handler;
|
||||
net_instaweb::HtmlParse html_parse(&handler);
|
||||
net_instaweb::HtmlWriterFilter html_writer_filter(&html_parse);
|
||||
|
||||
html_writer_filter.set_writer(&write_to_string);
|
||||
html_parse.AddFilter(&html_writer_filter);
|
||||
|
||||
html_parse.StartParse(\"http:example.com\");
|
||||
html_parse.ParseText(
|
||||
\"<html ><body ><h1 >Test</h1 ><p>Test Text</p></body></html>\n\");
|
||||
html_parse.FinishParse();
|
||||
|
||||
printf(\"parsed as: %s\", output_buffer.c_str())"
|
||||
|
||||
# Test whether we have pagespeed and can compile and link against it.
|
||||
. "$ngx_addon_dir/cpp_feature"
|
||||
|
||||
if [ $ngx_found = no ]; then
|
||||
cat << END
|
||||
$0: error: module ngx_pagespeed requires the pagespeed optimization library.
|
||||
Look in obj/autoconf.err for more details.
|
||||
END
|
||||
exit 1
|
||||
fi
|
||||
|
||||
ps_src="$ngx_addon_dir/src"
|
||||
ngx_addon_name=ngx_pagespeed
|
||||
NGX_ADDON_DEPS="$NGX_ADDON_DEPS \
|
||||
$ps_src/log_message_handler.h \
|
||||
$ps_src/ngx_base_fetch.h \
|
||||
$ps_src/ngx_caching_headers.h \
|
||||
$ps_src/ngx_event_connection.h \
|
||||
$ps_src/ngx_fetch.h \
|
||||
$ps_src/ngx_gzip_setter.h \
|
||||
$ps_src/ngx_list_iterator.h \
|
||||
$ps_src/ngx_message_handler.h \
|
||||
$ps_src/ngx_pagespeed.h \
|
||||
$ps_src/ngx_rewrite_driver_factory.h \
|
||||
$ps_src/ngx_rewrite_options.h \
|
||||
$ps_src/ngx_server_context.h \
|
||||
$ps_src/ngx_url_async_fetcher.h \
|
||||
$psol_binary"
|
||||
NPS_SRCS=" \
|
||||
$ps_src/log_message_handler.cc \
|
||||
$ps_src/ngx_base_fetch.cc \
|
||||
$ps_src/ngx_caching_headers.cc \
|
||||
$ps_src/ngx_event_connection.cc \
|
||||
$ps_src/ngx_fetch.cc \
|
||||
$ps_src/ngx_gzip_setter.cc \
|
||||
$ps_src/ngx_list_iterator.cc \
|
||||
$ps_src/ngx_message_handler.cc \
|
||||
$ps_src/ngx_pagespeed.cc \
|
||||
$ps_src/ngx_rewrite_driver_factory.cc \
|
||||
$ps_src/ngx_rewrite_options.cc \
|
||||
$ps_src/ngx_server_context.cc \
|
||||
$ps_src/ngx_url_async_fetcher.cc"
|
||||
# Save our sources in a separate var since we may need it in config.make
|
||||
PS_NGX_SRCS="$NGX_ADDON_SRCS \
|
||||
$NPS_SRCS"
|
||||
|
||||
# Make pagespeed run immediately before gzip and Brotli.
|
||||
if echo $HTTP_FILTER_MODULES | grep ngx_http_brotli_filter_module >/dev/null; then
|
||||
next=ngx_http_brotli_filter_module
|
||||
elif [ $HTTP_GZIP = YES ]; then
|
||||
next=ngx_http_gzip_filter_module
|
||||
else
|
||||
next=ngx_http_range_header_filter_module
|
||||
fi
|
||||
|
||||
if [ -n "$ngx_module_link" ]; then
|
||||
# nginx-1.9.11+
|
||||
ngx_module_type=HTTP_FILTER
|
||||
ngx_module_name="ngx_pagespeed ngx_pagespeed_etag_filter"
|
||||
ngx_module_incs="$ngx_feature_path"
|
||||
ngx_module_deps=
|
||||
ngx_module_srcs="$NPS_SRCS"
|
||||
ngx_module_libs="$ngx_feature_libs"
|
||||
ngx_module_order="ngx_http_range_header_filter_module\
|
||||
ngx_pagespeed_etag_filter\
|
||||
ngx_http_gzip_filter_module \
|
||||
ngx_http_brotli_filter_module \
|
||||
ngx_pagespeed \
|
||||
ngx_http_postpone_filter_module \
|
||||
ngx_http_ssi_filter_module \
|
||||
ngx_http_charset_filter_module \
|
||||
ngx_http_xslt_filter_module \
|
||||
ngx_http_image_filter_module \
|
||||
ngx_http_sub_filter_module \
|
||||
ngx_http_addition_filter_module \
|
||||
ngx_http_gunzip_filter_module \
|
||||
ngx_http_userid_filter_module \
|
||||
ngx_http_headers_filter_module"
|
||||
|
||||
. auto/module
|
||||
|
||||
if [ $ngx_module_link != DYNAMIC ]; then
|
||||
# ngx_module_order doesn't work with static modules,
|
||||
# so we must re-order filters here.
|
||||
if [ "$position_aux" = "true" ] ; then
|
||||
HTTP_AUX_FILTER_MODULES="$HTTP_AUX_FILTER_MODULES $ngx_addon_name"
|
||||
else
|
||||
HTTP_FILTER_MODULES=$(echo $HTTP_FILTER_MODULES \
|
||||
| sed "s/ngx_pagespeed//" \
|
||||
| sed "s/$next/$next ngx_pagespeed/")
|
||||
fi
|
||||
# Make the etag header filter run immediately before range header filter.
|
||||
HTTP_FILTER_MODULES=$(echo $HTTP_FILTER_MODULES \
|
||||
| sed "s/ngx_pagespeed_etag_filter//" \
|
||||
| sed "s/ngx_http_range_header_filter_module/ngx_http_range_header_filter_module ngx_pagespeed_etag_filter/")
|
||||
else
|
||||
# config.make is not executed for dynamic modules
|
||||
CFLAGS="$CFLAGS -Wno-c++11-extensions"
|
||||
if [ "$position_aux" = "true" ] ; then
|
||||
ngx_module_type=HTTP_AUX_FILTER
|
||||
ngx_module_order=""
|
||||
fi
|
||||
fi
|
||||
else
|
||||
CORE_LIBS="$CORE_LIBS $pagespeed_libs"
|
||||
CORE_INCS="$CORE_INCS $pagespeed_include"
|
||||
NGX_ADDON_SRCS="$PS_NGX_SRCS"
|
||||
if [ "$position_aux" = "true" ] ; then
|
||||
HTTP_AUX_FILTER_MODULES="$HTTP_AUX_FILTER_MODULES $ngx_addon_name"
|
||||
else
|
||||
HTTP_FILTER_MODULES=$(echo $HTTP_FILTER_MODULES | sed "s/$next/$next $ngx_addon_name/")
|
||||
fi
|
||||
|
||||
# Make the etag header filter run immediately before range header filter.
|
||||
HTTP_FILTER_MODULES=$(echo $HTTP_FILTER_MODULES |\
|
||||
sed "s/ngx_http_range_header_filter_module/ngx_http_range_header_filter_module ngx_pagespeed_etag_filter/")
|
||||
fi
|
||||
|
||||
echo "List of modules (in reverse order of applicability): "$HTTP_FILTER_MODULES
|
||||
|
||||
# Test whether the compiler is compatible
|
||||
ngx_feature="psol-compiler-compat"
|
||||
ngx_feature_name=""
|
||||
ngx_feature_run=no
|
||||
ngx_feature_incs=""
|
||||
ngx_feature_path=""
|
||||
ngx_feature_libs="-lstdc++"
|
||||
ngx_feature_test="
|
||||
|
||||
#if defined(__clang__) && defined(__GLIBCXX__)
|
||||
// See https://gcc.gnu.org/onlinedocs/libstdc++/manual/abi.html#abi.versioning
|
||||
// for a list of various values of __GLIBCXX__. Note that they're not monotonic
|
||||
// with respect to version numbers.
|
||||
#if __GLIBCXX__ == 20120322 || __GLIBCXX__ == 20120614
|
||||
#error \"clang is using libstdc++ 4.7.0 or 4.7.1, which can cause binary incompatibility.\"
|
||||
#endif
|
||||
#endif
|
||||
|
||||
#if !defined(__clang__) && defined(__GNUC__)
|
||||
#if __GNUC__ < 4 || (__GNUC__ == 4 && __GNUC_MINOR__ < 8)
|
||||
#error \"GCC < 4.8 no longer supported. Please use gcc >= 4.8 or clang >= 3.3\"
|
||||
#endif
|
||||
#endif
|
||||
|
||||
#if defined(__clang__)
|
||||
#if __clang_major__ < 3 || (__clang_major__ == 3 && __clang_minor__ < 3)
|
||||
#error \"Please use gcc >= 4.8 or clang >= 3.3\"
|
||||
#endif
|
||||
#endif
|
||||
"
|
||||
|
||||
. "$ngx_addon_dir/cpp_feature"
|
||||
|
||||
if [ $ngx_found = no ]; then
|
||||
cat << END
|
||||
$0: error: module ngx_pagespeed requires gcc >= 4.8 or clang >= 3.3.
|
||||
See https://developers.google.com/speed/pagespeed/module/build_ngx_pagespeed_from_source for some recommendations.
|
||||
Look in objs/autoconf.err for more details.
|
||||
END
|
||||
exit 1
|
||||
fi
|
||||
|
||||
have=NGX_PAGESPEED . auto/have
|
||||
@@ -1,7 +0,0 @@
|
||||
if [ -n "$NGX_CLANG_VER" ]; then
|
||||
# Chromium headers assume clang is always in C++11 mode. Oblige it.
|
||||
for ps_src_file in $PS_NGX_SRCS; do
|
||||
ps_obj_file="$NGX_OBJS/addon/src/`basename $ps_src_file .cc`.o"
|
||||
echo "$ps_obj_file : CFLAGS += --std=c++11" >> $NGX_MAKEFILE
|
||||
done
|
||||
fi
|
||||
-122
@@ -1,122 +0,0 @@
|
||||
# Copyright (C) Igor Sysoev
|
||||
# Copyright (C) Nginx, Inc.
|
||||
# 2012-10-01 Modified from auto/feature by jefftk to support c++ test files.
|
||||
|
||||
echo $ngx_n "checking for $ngx_feature ...$ngx_c"
|
||||
|
||||
cat << END >> $NGX_AUTOCONF_ERR
|
||||
|
||||
----------------------------------------
|
||||
checking for $ngx_feature
|
||||
|
||||
END
|
||||
|
||||
ngx_found=no
|
||||
|
||||
if test -n "$ngx_feature_name"; then
|
||||
ngx_have_feature=`echo $ngx_feature_name \
|
||||
| tr abcdefghijklmnopqrstuvwxyz ABCDEFGHIJKLMNOPQRSTUVWXYZ`
|
||||
fi
|
||||
|
||||
if test -n "$ngx_feature_path"; then
|
||||
for ngx_temp in $ngx_feature_path; do
|
||||
ngx_feature_inc_path="$ngx_feature_inc_path -I $ngx_temp"
|
||||
done
|
||||
fi
|
||||
|
||||
cat << END > $NGX_AUTOTEST.cc
|
||||
|
||||
#include <sys/types.h>
|
||||
$NGX_INCLUDE_UNISTD_H
|
||||
$ngx_feature_incs
|
||||
|
||||
int main() {
|
||||
$ngx_feature_test;
|
||||
return 0;
|
||||
}
|
||||
|
||||
END
|
||||
|
||||
|
||||
ngx_test="$CC $CC_TEST_FLAGS $CC_AUX_FLAGS $ngx_feature_inc_path \
|
||||
-o $NGX_AUTOTEST $NGX_AUTOTEST.cc $NGX_TEST_LD_OPT $ngx_feature_libs"
|
||||
|
||||
ngx_feature_inc_path=
|
||||
|
||||
eval "/bin/sh -c \"$ngx_test\" >> $NGX_AUTOCONF_ERR 2>&1"
|
||||
|
||||
|
||||
if [ -x $NGX_AUTOTEST ]; then
|
||||
|
||||
case "$ngx_feature_run" in
|
||||
|
||||
yes)
|
||||
# /bin/sh is used to intercept "Killed" or "Abort trap" messages
|
||||
if /bin/sh -c $NGX_AUTOTEST >> $NGX_AUTOCONF_ERR 2>&1; then
|
||||
echo " found"
|
||||
ngx_found=yes
|
||||
|
||||
if test -n "$ngx_feature_name"; then
|
||||
have=$ngx_have_feature . auto/have
|
||||
fi
|
||||
|
||||
else
|
||||
echo " found but is not working"
|
||||
fi
|
||||
;;
|
||||
|
||||
value)
|
||||
# /bin/sh is used to intercept "Killed" or "Abort trap" messages
|
||||
if /bin/sh -c $NGX_AUTOTEST >> $NGX_AUTOCONF_ERR 2>&1; then
|
||||
echo " found"
|
||||
ngx_found=yes
|
||||
|
||||
cat << END >> $NGX_AUTO_CONFIG_H
|
||||
|
||||
#ifndef $ngx_feature_name
|
||||
#define $ngx_feature_name `$NGX_AUTOTEST`
|
||||
#endif
|
||||
|
||||
END
|
||||
else
|
||||
echo " found but is not working"
|
||||
fi
|
||||
;;
|
||||
|
||||
bug)
|
||||
# /bin/sh is used to intercept "Killed" or "Abort trap" messages
|
||||
if /bin/sh -c $NGX_AUTOTEST >> $NGX_AUTOCONF_ERR 2>&1; then
|
||||
echo " not found"
|
||||
|
||||
else
|
||||
echo " found"
|
||||
ngx_found=yes
|
||||
|
||||
if test -n "$ngx_feature_name"; then
|
||||
have=$ngx_have_feature . auto/have
|
||||
fi
|
||||
fi
|
||||
;;
|
||||
|
||||
*)
|
||||
echo " found"
|
||||
ngx_found=yes
|
||||
|
||||
if test -n "$ngx_feature_name"; then
|
||||
have=$ngx_have_feature . auto/have
|
||||
fi
|
||||
;;
|
||||
|
||||
esac
|
||||
|
||||
else
|
||||
echo " not found"
|
||||
|
||||
echo "----------" >> $NGX_AUTOCONF_ERR
|
||||
cat $NGX_AUTOTEST.cc >> $NGX_AUTOCONF_ERR
|
||||
echo "----------" >> $NGX_AUTOCONF_ERR
|
||||
echo $ngx_test >> $NGX_AUTOCONF_ERR
|
||||
echo "----------" >> $NGX_AUTOCONF_ERR
|
||||
fi
|
||||
|
||||
rm $NGX_AUTOTEST*
|
||||
+702
@@ -0,0 +1,702 @@
|
||||
# This Makefile contains targets for building, testing, and debugging
|
||||
# mod_pagespeed during develoment. Useful targets:
|
||||
#
|
||||
# apache_debug
|
||||
# apache_release
|
||||
# - Build a development (debug), or release (optimized), version of
|
||||
# mod_pagespeed.
|
||||
#
|
||||
# apache_debug_psol
|
||||
# - Build a development version of PSOL, as '.a' file suitable for
|
||||
# ngx_pagespeed to link against.
|
||||
#
|
||||
# apache_test
|
||||
# - Run all unit tests. You can also run the tests in halves with:
|
||||
# - mod_pagespeed_test
|
||||
# - Run unit tests under test.gyp:mod_pagespeed_test
|
||||
# - pagespeed_automatic_test
|
||||
# - Run unit tests under test.gyp:pagespeed_automatic_test
|
||||
# - You can run a specific unit test by setting TEST=test_name.
|
||||
# For example:
|
||||
# TEST=SerfUrlAsyncFetcherTest.FetchOneURLWithGzip
|
||||
# You can also run a subset of tests, using wildcards:
|
||||
# TEST=SerfUrlAsyncFetcherTest.* make apache_test
|
||||
# What you give to TEST is passed to googletest with --gtest_filter, so for
|
||||
# more details see the doc there:
|
||||
# https://github.com/google/googletest/blob/master/googletest/docs/AdvancedGuide.md#running-a-subset-of-the-tests
|
||||
#
|
||||
# apache_release_test
|
||||
# - Run all unit test with a release (non-debug) build.
|
||||
#
|
||||
# apache_root_test
|
||||
# - Currently broken test that builds install tarball, installs it as the root
|
||||
# apache on port 80 (requires sudo password) and runs most of our system
|
||||
# tests to make sure filters are working and rewritten resources are served.
|
||||
#
|
||||
# (This file also pulls in the contents of Makefile.tests, so some useful
|
||||
# targets are defined there instead. To run system tests, for example, you can
|
||||
# run apache_debug_smoke_test.)
|
||||
#
|
||||
# apache_install_conf
|
||||
# - Copy install/debug.conf.template to your development apache directory,
|
||||
# making substitutions for @@VARS@@ and, depending on how OPTIONS is set,
|
||||
# uncommenting some #TESTVAR lines.
|
||||
# - When running tests this target is run automatically, but you may need to
|
||||
# run it manually during debugging.
|
||||
#
|
||||
# apache_debug_install
|
||||
# apache_release_install
|
||||
# - Install the debug/release version of mod_pagespeed into the build of apache
|
||||
# that build_development_apache.sh created.
|
||||
# - This is another command that you probably only need when debugging
|
||||
# manually.
|
||||
#
|
||||
# apache_debug_start
|
||||
# apache_debug_stop
|
||||
# apache_debug_restart
|
||||
# - Start, stop, and restart the development apache instance. This also
|
||||
# includes a few other potentially useful maintenance tasks, like cleaning up
|
||||
# temp files and rotating logs.
|
||||
# - Unless you specify FAST_RESTART=1, apache_debug_restart runs
|
||||
# apache_debug_install to make sure you're running the module you built and
|
||||
# not an earlier version.
|
||||
#
|
||||
# apache_debug_slurp
|
||||
# - mod_pagespeed can be run in "slurp" mode, where it is configured as a
|
||||
# forward proxy that saves a copy of everything that runs through it. Later
|
||||
# on the slurp can be served in read-only mode, to serve the cached copy of
|
||||
# whatever was visited. This is intended for testing and debugging, and is
|
||||
# what the load test uses.
|
||||
#
|
||||
# apache_debug_leak_test
|
||||
# - Run the unit tests and system tests under valgrind, to check for memory
|
||||
# errors and leaks.
|
||||
#
|
||||
# update_gyp_manifest
|
||||
# - If you add or remove a .gyp or .gypi file, run this target so we know to
|
||||
# watch it for changes.
|
||||
#
|
||||
# submodule_update
|
||||
# - The mod_pagespeed git repo includes its dependencies as git submodules.
|
||||
# These dependencies are pinned to a specific git revision. If someone has
|
||||
# upgraded one, you need to run submodule_update to apply those changes.
|
||||
#
|
||||
# doxygen
|
||||
# - Builds html documentation for PSOL. It includes everything defined as
|
||||
# public in the .h files. You might ask: how do I know what things are safe
|
||||
# to depend on as consumer of PSOL, and which might change? This is a good
|
||||
# question with a bad answer: you can depend on anything, and anything might
|
||||
# change. We don't offer ABI or even API compatibility across versions, even
|
||||
# across point releases.
|
||||
#
|
||||
# This Makefile also includes various test targets that really should be in
|
||||
# Makefile.tests:
|
||||
# - apache_debug_proxy_test
|
||||
# - apache_debug_slurp_test
|
||||
# TODO(jefftk): move these into Makefile.tests
|
||||
#
|
||||
# It also includes other targets that are not indended to be run directly, and
|
||||
# are either here to support devel/ scripts or to support other targets.
|
||||
# somewhat redundant with the .gyp files, but helps bridge the gap and automate
|
||||
# the transition.
|
||||
#
|
||||
# You can use the CONF= parameter to change build settings or enable coverage
|
||||
# testing for debug builds:
|
||||
#
|
||||
# CONF=Debug
|
||||
# - default, shouldn't be needed
|
||||
# CONF=Coverage
|
||||
# - run the test coverage analysis scripts after tests complete
|
||||
# CONF=Release
|
||||
# - shouldn't be needed; use targets with "release" in their name instead.
|
||||
# CONF=OptDebug
|
||||
# - build optimized binaries with debug info (-O2 -g)
|
||||
|
||||
# We need gcc-mozilla/bin to pick up our special gcc 4.8 for old versions of
|
||||
# ubuntu. It's ok to have it in the path even if we're on a machine where that
|
||||
# directory doesn't exist; bash will just move on.
|
||||
# TODO(jefftk): source ubuntu/make_vars.mk here, then move this there.
|
||||
# TODO(jefftk): get this Makefile working on other platforms (centos, ubuntu16)
|
||||
PATH := /usr/lib/gcc-mozilla/bin:/usr/local/bin:/usr/bin:$(PATH)
|
||||
export PATH
|
||||
|
||||
GIT_SRC = $(realpath ${PWD}/..)
|
||||
DEVEL_DIR = $(GIT_SRC)/devel
|
||||
INSTALL_DATA_DIR = $(GIT_SRC)/install
|
||||
|
||||
# Where binaries go.
|
||||
GIT_RELEASE_BIN = $(GIT_SRC)/out/Release
|
||||
GIT_DEBUG_BIN = $(GIT_SRC)/out/Debug
|
||||
GIT_BIN = $(GIT_SRC)/out/$(BUILDTYPE)
|
||||
|
||||
# GYP_MANIFEST holds a cached copy of the gyp files in this client. When we
|
||||
# first create a new checkout we run update_gyp_manifest, and from then on we
|
||||
# use the cached copy when we need to know whether to rerun hooks.
|
||||
GYP_MANIFEST = $(GIT_SRC)/gyp_manifest.d
|
||||
.PHONY : update_gyp_manifest
|
||||
update_gyp_manifest :
|
||||
find $(GIT_SRC) -name '*.gyp' -o -name '*.gypi' | \
|
||||
sort > $(GYP_MANIFEST)
|
||||
|
||||
# It's ok for this variable to be empty, and it will be empty the first time we
|
||||
# run in a new checkout. When it's empty we won't know whether to run gyp
|
||||
# but on an initial checkout we run them regardless because we won't yet
|
||||
# have the hook stamp.
|
||||
GYP_FILES = $(shell [ -f $(GYP_MANIFEST) ] && cat $(GYP_MANIFEST) || echo "")
|
||||
|
||||
HOOKS_STAMP = $(GIT_SRC)/hooks.timestamp
|
||||
|
||||
ifeq ($(OBJDIR),)
|
||||
OBJDIR := $(shell mktemp -td instaweb.XXXXXX)
|
||||
endif
|
||||
export OBJDIR
|
||||
MAKE := $(MAKE) --no-print-directory OBJDIR=$(OBJDIR)
|
||||
|
||||
# Unset environment variables that can interfere with the make process.
|
||||
# TODO(vchudnov): Not all of these may be problematic. Narrow down
|
||||
# this list if possible.
|
||||
unexport CC CXX GYP_DEFINES GYP_GENERATORS http_proxy
|
||||
|
||||
# gcc-mozilla contains /usr/lib/gcc-mozilla/bin/gcc but not
|
||||
# /usr/lib/gcc-mozilla/bin/cc so if we want to use gcc-mozilla, which we do on
|
||||
# Ubuntu 12 LTS, then we need to explicitly set CC=gcc.
|
||||
# TODO(jefftk): do this in a way that lets people explicitly choose to build
|
||||
# with clang instead of forcing gcc on everyone.
|
||||
export CC=gcc
|
||||
|
||||
# By default, precompiled JS files are used. When developing, though, we want to
|
||||
# enable local compilation of JS, so export the flag that enables use of the
|
||||
# closure compiler. Note that this var is checked when gyp is run, not at
|
||||
# compile time.
|
||||
export BUILD_JS=1
|
||||
|
||||
# Run the proxy tests from a host configured via
|
||||
# cd install; ./ubuntu.sh setup_test_machine
|
||||
# We use 'export' here so that apache/system_test.sh can see it.
|
||||
|
||||
PAGESPEED_TEST_HOST ?= selfsigned.modpagespeed.com
|
||||
export PAGESPEED_TEST_HOST
|
||||
|
||||
# We don't want our targets to be run parallelized, as we want
|
||||
# various directory maintenance steps to be run in-order
|
||||
# This prevents that from happening, but still passes -j to actual
|
||||
# compilation
|
||||
.NOTPARALLEL :
|
||||
|
||||
.PHONY : prepare_objdir
|
||||
prepare_objdir : $(OBJDIR)
|
||||
CHECKIN_PREP_TARGETS = test_no_var_growth prepare_objdir exes
|
||||
|
||||
.PHONY : checkin_prep echo_checkin_prep
|
||||
checkin_prep : $(CHECKIN_PREP_TARGETS)
|
||||
echo_checkin_prep :
|
||||
@echo $(CHECKIN_PREP_TARGETS)
|
||||
|
||||
# Determine gyp BUILDTYPE and hooks we should run based on the passed in CONF
|
||||
# TOOD(jefftk): The difference between setting CONF, BUILDTYPE, and running a
|
||||
# target that sets BUILDTYPE makes it pretty hard to know what BUILDTYPE(s) a
|
||||
# section of this Makefile might run under. Clean this up.
|
||||
CONF ?= Debug
|
||||
HOOKTYPE = NoHooks
|
||||
BUILDTYPE = $(CONF)
|
||||
|
||||
ifeq ($(CONF),Coverage)
|
||||
override BUILDTYPE=Debug_Coverage
|
||||
override HOOKTYPE=Coverage
|
||||
else ifeq ($(CONF),OptDebug)
|
||||
# For -O2 -g type builds, we have to build as BUILDTYPE=Release CXXLAGS=-g;
|
||||
# with BUILDTYPE=Debug CXXFLAGS="-O2" we would get a -O2 -g -O0 out of gyp,
|
||||
# with the -O0 cancelling the -O2.
|
||||
override BUILDTYPE=Release
|
||||
# We need to make sure to add -g only once (since otherwise recursive
|
||||
# invocation will end up with something like -g -g -g and force a rebuild)
|
||||
ifeq (,$(findstring -g,$(CFLAGS)))
|
||||
override CFLAGS+= -g
|
||||
override CXXFLAGS+= -g
|
||||
endif
|
||||
export CFLAGS
|
||||
endif
|
||||
|
||||
# We'd like to put this in gyp file, but that makes it hard to compile
|
||||
# on old versions of g++ that do not support this flag. However we
|
||||
# can add the flag during development. Don't add this in if it's
|
||||
# already present; that causes cxxflags to mismatch adding extra compiles.
|
||||
ifeq (,$(findstring -Wtype-limits,$(CXXFLAGS)))
|
||||
override CXXFLAGS+= -Wtype-limits
|
||||
endif
|
||||
export CXXFLAGS
|
||||
export BUILDTYPE
|
||||
|
||||
# test to make sure that CXXFLAGS doesn't grow on each recursion
|
||||
.PHONY : test_no_var_growth
|
||||
test_no_var_growth :
|
||||
[ "$(CXXFLAGS)" = \
|
||||
"`$(MAKE) echo_var VAR=CXXFLAGS `" ] || \
|
||||
$(DEVEL_DIR)/expectfail echo CXXFLAGS changed on Makefile recursion
|
||||
|
||||
APACHE_RELEASE_MODULES_DIR=/usr/lib/apache2/modules
|
||||
|
||||
APACHE_DEBUG_ROOT ?= $(HOME)/apache2
|
||||
|
||||
# Note: these must be distinct from the ports used for apache_root_test.
|
||||
APACHE_PORT = 8080
|
||||
APACHE_SLURP_ORIGIN_PORT = 8081
|
||||
APACHE_SLURP_PORT = 8082
|
||||
APACHE_SECONDARY_PORT = 8083
|
||||
APACHE_TERTIARY_PORT = 8085
|
||||
APACHE_HTTPS_PORT = 8443
|
||||
CONTROLLER_PORT = 8086
|
||||
RCPORT=9091
|
||||
# If you add additional ports here, make sure they don't overlap with the test
|
||||
# ports ngx_pagespeed uses. Check ngx_pagespeed/test/run_tests.sh for the list.
|
||||
|
||||
OPTIONS = $(EXTRA_OPTIONS) HTTPS_TEST=1
|
||||
APACHE_DEBUG_MODULES = $(APACHE_DEBUG_ROOT)/modules
|
||||
APACHE_DEBUG_BIN = $(APACHE_DEBUG_ROOT)/bin
|
||||
MOD_PAGESPEED_CACHE = $(APACHE_DEBUG_ROOT)/pagespeed_cache
|
||||
MOD_PAGESPEED_LOG = $(APACHE_DEBUG_ROOT)/pagespeed_log
|
||||
TMP_SLURP_DIR = /tmp/instaweb/$(USER)/slurp
|
||||
# Not used in this Makefile, but needed for some submake/script.
|
||||
APACHE_LOG = $(APACHE_DEBUG_ROOT)/logs/error_log
|
||||
APACHE_DEBUG_PAGESPEED_CONF = $(APACHE_DEBUG_ROOT)/conf/pagespeed.conf
|
||||
APACHE_DOC_ROOT = $(APACHE_DEBUG_ROOT)/htdocs
|
||||
|
||||
APACHE_SERVER = http://localhost:$(APACHE_PORT)
|
||||
|
||||
# We want to track borgingssl branch chromium-stable at head, but submodules
|
||||
# tracks a specific commit ID.
|
||||
# If we need more deps like this, we should figure out a more generic solution.
|
||||
UPDATE_BORINGSSL = git checkout chromium-stable && git pull
|
||||
|
||||
# These hooks are invoked before/after apache or tests are run
|
||||
.PHONY : pre_start_NoHooks post_run_NoHooks pre_start_Coverage post_run_Coverage
|
||||
.PHONY : pre_start post_run
|
||||
pre_start_NoHooks :
|
||||
post_run_NoHooks :
|
||||
|
||||
pre_start_Coverage :
|
||||
$(DEVEL_DIR)/gcov-all.sh --prepare $(GIT_SRC)
|
||||
|
||||
post_run_Coverage :
|
||||
$(DEVEL_DIR)/gcov-all.sh --summarize $(GIT_SRC)
|
||||
|
||||
pre_start : pre_start_$(HOOKTYPE)
|
||||
|
||||
post_run : post_run_$(HOOKTYPE)
|
||||
|
||||
# We check closure-compiled javascript into git to enable people to use
|
||||
# closure-compiled output without needing to have a closure compiler dependency
|
||||
# in the build process.
|
||||
GENFILES = $(GIT_SRC)/net/instaweb/genfiles
|
||||
|
||||
.PHONY : apache_debug apache_debug_psol
|
||||
|
||||
# Sets up a development tree, and builds the modules
|
||||
apache_debug : $(HOOKS_STAMP)
|
||||
@echo "building Apache module $@ ..."
|
||||
cd $(GIT_SRC) && $(MAKE)
|
||||
@echo Built mod_pagespeed successfully:
|
||||
ls -l $(GIT_DEBUG_BIN)/libmod_pagespeed.so
|
||||
@echo To install, type
|
||||
@echo " " cp $(GIT_DEBUG_BIN)/libmod_pagespeed.so \
|
||||
$(APACHE_DEBUG_ROOT)/modules/mod_pagespeed.so
|
||||
|
||||
apache_debug_psol : apache_debug
|
||||
cd $(GIT_SRC)/pagespeed/automatic && $(MAKE) \
|
||||
MOD_PAGESPEED_ROOT=$(GIT_SRC) \
|
||||
OUTPUT_DIR=$(GIT_DEBUG_BIN) \
|
||||
BUILDTYPE=Debug \
|
||||
CXXFLAGS=$(CXXFLAGS) \
|
||||
all
|
||||
@echo Built PSOL successfully under in $(GIT_DEBUG_BIN)
|
||||
|
||||
.PHONY : submodule_update
|
||||
submodule_update:
|
||||
@echo "Updating local checkouts from open source. If these generate any"
|
||||
@echo "merge conflicts you'll need to resolve them manually."
|
||||
cd $(GIT_SRC) && git pull --ff-only && git submodule update --recursive
|
||||
|
||||
.PHONY : exes apache_debug_install apache_debug_stop apache_debug_start
|
||||
exes : apache_debug_install
|
||||
apache_debug_install : apache_debug
|
||||
install -c $(GIT_BIN)/libmod_pagespeed.so \
|
||||
$(APACHE_DEBUG_MODULES)/mod_pagespeed.so
|
||||
install -c $(GIT_BIN)/libmod_pagespeed_ap24.so \
|
||||
$(APACHE_DEBUG_MODULES)/mod_pagespeed_ap24.so
|
||||
|
||||
apache_debug_stop :
|
||||
$(MAKE) stop
|
||||
$(MAKE) post_run
|
||||
|
||||
apache_debug_start :
|
||||
$(MAKE) pre_start
|
||||
$(MAKE) stop
|
||||
$(DEVEL_DIR)/apache_cleanup.sh $(USER)
|
||||
-$(DEVEL_DIR)/apache_rotate_logs.sh $(APACHE_DEBUG_ROOT)/logs
|
||||
$(MAKE) start
|
||||
|
||||
.PHONY : apache_debug_restart
|
||||
ifeq ($(FAST_RESTART),1)
|
||||
apache_debug_restart :
|
||||
$(MAKE) apache_debug_stop
|
||||
$(MAKE) apache_debug_start
|
||||
else
|
||||
# Restarts with newest module
|
||||
apache_debug_restart :
|
||||
$(MAKE) apache_debug_stop
|
||||
$(MAKE) apache_debug_install
|
||||
$(MAKE) apache_debug_start
|
||||
endif
|
||||
|
||||
# Installs a slurping pagespeed.conf on localhost:8082 and runs a debug
|
||||
# binary.
|
||||
.PHONY : apache_debug_slurp
|
||||
apache_debug_slurp : slurp_test_prepare apache_install_conf
|
||||
$(MAKE) apache_debug_restart
|
||||
@echo Set your browser proxy to `hostname`:$(APACHE_SLURP_PORT)
|
||||
|
||||
# Stop and start Apache as reliably as possible.
|
||||
.PHONY : stop start
|
||||
stop :
|
||||
$(INSTALL_DATA_DIR)/stop_apache.sh $(APACHE_DEBUG_BIN)/apachectl \
|
||||
$(APACHE_DEBUG_ROOT)/logs/httpd.pid \
|
||||
$(APACHE_DEBUG_BIN)/httpd \
|
||||
graceful-stop \
|
||||
$(APACHE_PORT)
|
||||
|
||||
start :
|
||||
$(APACHE_DEBUG_BIN)/apachectl start
|
||||
@if [ ! -f $(APACHE_DEBUG_ROOT)/logs/httpd.pid ]; then \
|
||||
/bin/echo -n "Waiting for httpd to start"; \
|
||||
while [ ! -f $(APACHE_DEBUG_ROOT)/logs/httpd.pid ]; do \
|
||||
/bin/echo -n "."; \
|
||||
sleep 1; \
|
||||
done; \
|
||||
/bin/echo; \
|
||||
fi
|
||||
|
||||
.PHONY : apache_debug_leak_test
|
||||
apache_debug_leak_test :
|
||||
rm -rf $(MOD_PAGESPEED_CACHE)/* # Start with an empty cache
|
||||
$(DEVEL_DIR)/check_for_leaks \
|
||||
$(APACHE_DEBUG_ROOT) localhost:$(APACHE_PORT)
|
||||
|
||||
include $(INSTALL_DATA_DIR)/Makefile.tests
|
||||
|
||||
# Installs the apache debug server and runs a stress test against it.
|
||||
# This will blow away your existing cache and pagespeed.conf.
|
||||
#
|
||||
# Note: this test is obsolete; you probably want mps_load_test.sh or one of the
|
||||
# siege tests.
|
||||
#
|
||||
# TODO(sligocki): Lock Apache.
|
||||
apache_debug_stress_test : stress_test_prepare apache_install_conf
|
||||
$(MAKE) apache_debug_restart
|
||||
$(INSTALL_DATA_DIR)/stress_test.sh localhost:$(APACHE_PORT)
|
||||
$(MAKE) apache_debug_stop
|
||||
|
||||
stress_test_prepare :
|
||||
# stop old apaches, w/o generating any coverage reports,
|
||||
# (as we're about to do some new test)
|
||||
$(MAKE) stop
|
||||
$(eval OPTIONS+=STRESS_TEST=1)
|
||||
-rm -rf $(MOD_PAGESPEED_CACHE)/*
|
||||
|
||||
# This test checks that when ProxyPass is set on a host with mod_pagespeed
|
||||
# enabled, URLs are rewritten correctly. (See install/debug.conf.template)
|
||||
# See: http://github.com/pagespeed/mod_pagespeed/issues/74
|
||||
#
|
||||
# TODO(sligocki): Lock Apache.
|
||||
.PHONY : apache_debug_proxy_test proxy_test_prepare
|
||||
apache_debug_proxy_test : proxy_test_prepare apache_install_conf
|
||||
$(MAKE) apache_debug_restart
|
||||
$(WGET_NO_PROXY) -q -O /dev/null \
|
||||
$(APACHE_SERVER)/proxy_pass.html?PageSpeedFilters=extend_cache
|
||||
sleep 1
|
||||
$(WGET_NO_PROXY) -q -O - \
|
||||
$(APACHE_SERVER)/proxy_pass.html?PageSpeedFilters=extend_cache\
|
||||
| grep "localhost:8080/proxy_pass.css.pagespeed.ce"
|
||||
# Before this was fixed, it would be rewritten as localhost:8081/...
|
||||
|
||||
proxy_test_prepare :
|
||||
$(eval OPTIONS+=PROXY_TEST=1)
|
||||
|
||||
# This test checks that we can serve slurped pages, both from requests
|
||||
# like those sent from a browser-proxy. We'd also like to test
|
||||
# requests sent from a fake DNS, like webpagetest, but I haven't
|
||||
# figured out how to do that yet. For now we'll just test read-only
|
||||
# proxying.
|
||||
#
|
||||
# In our test flow, we first warm up mod_pagespeed's cache with a
|
||||
# fetch and a sleep. Then we test to make sure that we rewrite a
|
||||
# resource properly, with mps on, and that we don't rewrite it with
|
||||
# mps off.
|
||||
#
|
||||
# TODO(sligocki): Lock Apache.
|
||||
.PHONY : apache_debug_slurp_test slurp_test_prepare
|
||||
apache_debug_slurp_test : slurp_test_prepare apache_install_conf
|
||||
$(MAKE) apache_debug_restart
|
||||
$(DEVEL_DIR)/slurp_test.sh $(APACHE_SERVER) \
|
||||
$(APACHE_SLURP_ORIGIN_PORT) $(APACHE_SLURP_PORT) $(WGET) \
|
||||
$(TMP_SLURP_DIR) $(PAGESPEED_TEST_HOST)
|
||||
|
||||
slurp_test_prepare :
|
||||
$(eval OPTIONS+=SLURP_TEST=1)
|
||||
rm -rf $(MOD_PAGESPEED_CACHE)/*
|
||||
|
||||
# This is for trace-based stress tests, that operate on recorded URLs
|
||||
# and slurp databases
|
||||
# Note: you can pass PAR=, EXP= and RUNS= to stress test targets that
|
||||
# execute the tests
|
||||
.PHONY : check_dump_dir apache_trace_stress_test_prepare
|
||||
check_dump_dir :
|
||||
$(if $(DUMP_DIR),,$(error "Need data directory set with DUMP_DIR="))
|
||||
$(if $(wildcard $(DUMP_DIR)/slurp),,\
|
||||
$(error "No slurp/ under $(DUMP_DIR)"))
|
||||
|
||||
# mod_pagespeed load tests can be started with scripts/mps_load_test.sh. If
|
||||
# given an arg 'memcached', then that script will export MEMCACHED=1 and that
|
||||
# will be passed to target 'apache_install_conf' as indicated below. Same
|
||||
# with cache_invalidation and inline_unauthorized_resources (IUR).
|
||||
apache_trace_stress_test_prepare : check_dump_dir
|
||||
$(MAKE) stress_test_prepare
|
||||
echo MEMCACHED=$(MEMCACHED)
|
||||
echo REDIS=$(REDIS)
|
||||
echo PURGING=$(PURGING)
|
||||
echo IUR=$(IUR)
|
||||
echo IPRO_PRESERVE=$(IPRO_PRESERVE)
|
||||
$(MAKE) apache_install_conf SLURP_DIR=$(DUMP_DIR)/slurp SLURP_WRITE=0 \
|
||||
OPTIONS="$(OPTIONS) \
|
||||
LOADTEST_TEST=1 \
|
||||
STRESS_TEST=1 \
|
||||
HTTPS_TEST=0 \
|
||||
IPRO_PRESERVE_LOADTEST_TEST=$(IPRO_PRESERVE) \
|
||||
MEMCACHED_LOADTEST_TEST=$(MEMCACHED) \
|
||||
REDIS_LOADTEST_TEST=$(REDIS) \
|
||||
PURGING_LOADTEST_TEST=$(PURGING) \
|
||||
IUR_LOADTEST_TEST=$(IUR)"
|
||||
|
||||
apache_trace_stress_test_server :
|
||||
$(MAKE) apache_trace_stress_test_prepare
|
||||
$(MAKE) apache_debug_install
|
||||
$(MAKE) apache_debug_start
|
||||
|
||||
ifeq ($(TEST),)
|
||||
TEST_ARG=
|
||||
else
|
||||
TEST_ARG=--gtest_filter=$(TEST)
|
||||
endif
|
||||
|
||||
.PHONY : apache_test mod_pagespeed_test
|
||||
apache_test : apache_debug
|
||||
$(MAKE) pre_start
|
||||
cd $(GIT_SRC) && \
|
||||
install/run_program_with_ext_caches.sh \
|
||||
$(GIT_BIN)/mod_pagespeed_test $(TEST_ARG)
|
||||
cd $(GIT_SRC) && \
|
||||
install/run_program_with_ext_caches.sh \
|
||||
$(GIT_BIN)/pagespeed_automatic_test $(TEST_ARG)
|
||||
$(MAKE) post_run
|
||||
|
||||
# TODO(jefftk): figure out if dividing the unit tests into mod_pagespeed_test
|
||||
# and pagespeed_automatic_test is actually helpful. Currently it looks like if
|
||||
# there was once a principled distinction between the targets it has atrophied.
|
||||
mod_pagespeed_test : apache_debug
|
||||
$(MAKE) pre_start
|
||||
cd $(GIT_SRC) && \
|
||||
install/run_program_with_ext_caches.sh \
|
||||
$(GIT_BIN)/mod_pagespeed_test $(TEST_ARG)
|
||||
$(MAKE) post_run
|
||||
|
||||
.PHONY : pagespeed_automatic_smoke_test
|
||||
# TODO(jefftk): get rid of this and just use apache_debug_psol
|
||||
pagespeed_automatic_smoke_test :
|
||||
@echo Building Pagespeed Automatic ...
|
||||
cd $(GIT_SRC)/pagespeed/automatic/ && \
|
||||
$(MAKE) MOD_PAGESPEED_ROOT=$(GIT_SRC) \
|
||||
OUTPUT_DIR=$(GIT_BIN) \
|
||||
CXXFLAGS=$(CXXFLAGS) \
|
||||
all
|
||||
|
||||
.PHONY : pagespeed_automatic_test
|
||||
pagespeed_automatic_test : apache_debug
|
||||
$(MAKE) pre_start
|
||||
cd $(GIT_SRC) && \
|
||||
install/run_program_with_ext_caches.sh \
|
||||
$(GIT_BIN)/pagespeed_automatic_test $(TEST_ARG)
|
||||
$(MAKE) post_run
|
||||
|
||||
.PHONY : apache_release_test
|
||||
apache_release_test : apache_release internal_release_test
|
||||
|
||||
TMP_PREFIX = /tmp/mod_pagespeed.$(USER).install
|
||||
|
||||
# Builds a binary release tarball, installs it as root (requires sudo password)
|
||||
# and tests that rewrites occur.
|
||||
#
|
||||
# TODO(jmarantz): We are still leaving a bunch of stuff behind in /tmp; organize
|
||||
# the temp dirs better and clean up.
|
||||
.PHONY : apache_root_test internal_release_test
|
||||
|
||||
# TODO(jmarantz): This target is not working yet...it fails copying over
|
||||
# pagespeed_libraries.conf. Investigate:
|
||||
# cat common/pagespeed.load.template | \
|
||||
# sed s~@@APACHE_MODULEDIR@@~/usr/lib/apache2/modules~ | \
|
||||
# sed s/@@COMMENT_OUT_DEFLATE@@// > /tmp/mod_pagespeed.install/pagespeed.load
|
||||
# cp -f /tmp/instaweb.vRV047/mod_pagespeed-test-jmarantz/install/net/instaweb/genfiles/conf/pagespeed_libraries.conf /tmp/mod_pagespeed.install/pagespeed_libraries.conf
|
||||
# cp: cannot stat ‘/tmp/instaweb.vRV047/mod_pagespeed-test-jmarantz/install/net/instaweb/genfiles/conf/pagespeed_libraries.conf’: No such file or directory
|
||||
# TODO(jefftk): this also depends on prepare_release.sh and install-glucid.sh,
|
||||
# that haven't been open sourced yet.
|
||||
#apache_root_test :
|
||||
# sudo /etc/init.d/apache2 stop
|
||||
# sudo rm -rf $(TMP_PREFIX) /tmp/mod_pagespeed.install
|
||||
# cd ../.. && devel/prepare_release.sh -force \
|
||||
# mod_pagespeed-test-$(USER)
|
||||
# cd $(OBJDIR) && tar xzf \
|
||||
# $(TMP_PREFIX)/mod_pagespeed-test-$(USER).tgz
|
||||
# cd $(OBJDIR)/mod_pagespeed-test-$(USER) && ./install-glucid.sh
|
||||
# rm -rf $(OBJDIR) /tmp/mod_pagespeed-test-$(USER).tgz
|
||||
# sudo rm -rf $(TMP_PREFIX) /tmp/mod_pagespeed.install
|
||||
|
||||
internal_release_test :
|
||||
cd $(GIT_SRC) && \
|
||||
BUILDTYPE=Release install/run_program_with_ext_caches.sh \
|
||||
$(GIT_RELEASE_BIN)/mod_pagespeed_test $(TEST_ARG) && \
|
||||
BUILDTYPE=Release install/run_program_with_ext_caches.sh \
|
||||
$(GIT_RELEASE_BIN)/pagespeed_automatic_test $(TEST_ARG)
|
||||
|
||||
# Configuration root for Apache file-system and cache directories, to
|
||||
# be written into config file.
|
||||
#
|
||||
# Installs a development copy of the the Instaweb server into $APACHE_DEBUG_ROOT
|
||||
.PHONY : apache_install_conf
|
||||
apache_install_conf : setup_doc_root
|
||||
rm -f $(APACHE_DEBUG_ROOT)/conf/pagespeed.conf
|
||||
mkdir -p $(MOD_PAGESPEED_CACHE)
|
||||
mkdir -p $(MOD_PAGESPEED_LOG)
|
||||
cd $(INSTALL_DATA_DIR) && \
|
||||
$(MAKE) $(APACHE_DEBUG_ROOT)/conf/pagespeed.conf \
|
||||
STAGING_DIR=$(APACHE_DEBUG_ROOT)/conf \
|
||||
APACHE_DOC_ROOT=$(APACHE_DEBUG_ROOT)/htdocs \
|
||||
APACHE_MODULES=$(APACHE_DEBUG_MODULES) \
|
||||
APACHE_DOMAIN=$(APACHE_SERVER) \
|
||||
CONTROLLER_PORT=$(CONTROLLER_PORT) \
|
||||
RCPORT=$(RCPORT) \
|
||||
APACHE_SECONDARY_PORT=$(APACHE_SECONDARY_PORT) \
|
||||
APACHE_TERTIARY_PORT=$(APACHE_TERTIARY_PORT) \
|
||||
APACHE_HTTPS_DOMAIN=$(APACHE_HTTPS_SERVER) \
|
||||
MOD_PAGESPEED_CACHE=$(MOD_PAGESPEED_CACHE) \
|
||||
MOD_PAGESPEED_LOG=$(MOD_PAGESPEED_LOG) \
|
||||
MOD_PAGESPEED_ROOT=$(GIT_SRC) \
|
||||
SLURP_DIR=$(SLURP_DIR) \
|
||||
SLURP_WRITE=$(SLURP_WRITE) \
|
||||
PAGESPEED_TEST_HOST=$(PAGESPEED_TEST_HOST) \
|
||||
TMP_SLURP_DIR=$(TMP_SLURP_DIR) \
|
||||
$(OPTIONS)
|
||||
$(DEVEL_DIR)/apache_configure_https_port.sh $(APACHE_DEBUG_ROOT) \
|
||||
$(APACHE_HTTPS_PORT)
|
||||
$(DEVEL_DIR)/apache_create_server_certificate.sh $(APACHE_DEBUG_ROOT)
|
||||
$(DEVEL_DIR)/apache_configure_php5_from_etc_php5.sh $(APACHE_DEBUG_ROOT)
|
||||
$(DEVEL_DIR)/apache_install.sh \
|
||||
$(APACHE_DEBUG_ROOT) $(APACHE_PORT) $(GIT_SRC)
|
||||
|
||||
# Builds the release objects. This should not be run on its own -- it
|
||||
# should be run manually via 'make apache_release'.
|
||||
.PHONY : internal_release_build
|
||||
internal_release_build : $(GIT_SRC) $(HOOKS_STAMP)
|
||||
@echo "building Apache release module ..."
|
||||
cd $(GIT_SRC) && BUILDTYPE=Release $(MAKE)
|
||||
|
||||
DOXYGEN_TARBALL = $(OBJDIR)/psol_doc.tar.gz
|
||||
# Generates a doxygen tarball in $(DOXYGEN_TARBALL) suitable for
|
||||
# scp to modpagespeed.com.
|
||||
.PHONY : doxygen
|
||||
doxygen :
|
||||
$(DEVEL_DIR)/doxify_tree.sh $(DOXYGEN_TARBALL)
|
||||
|
||||
.PHONY : apache_release apache_release_install
|
||||
apache_release : internal_release_build
|
||||
@echo Release apache module built. Install it with
|
||||
@echo " " cd $(GIT_SRC)/install
|
||||
@echo " " make staging
|
||||
@echo " " sudo make install
|
||||
@echo "or"
|
||||
@echo " " sudo cp \
|
||||
$(GIT_RELEASE_BIN)/libmod_pagespeed.so \
|
||||
$(APACHE_RELEASE_MODULES_DIR)/mod_pagespeed.so
|
||||
|
||||
apache_release_install : apache_release
|
||||
@echo "Copy the module to your Apache2 modules directory."
|
||||
@echo "Then, restart your Apache server."
|
||||
install -c $(GIT_RELEASE_BIN)/libmod_pagespeed.so \
|
||||
$(APACHE_RELEASE_MODULES_DIR)/mod_pagespeed.so
|
||||
install -c $(GIT_RELEASE_BIN)/libmod_pagespeed_ap24.so \
|
||||
$(APACHE_RELEASE_MODULES_DIR)/mod_pagespeed_ap24.so
|
||||
/etc/init.d/apache2 stop
|
||||
/etc/init.d/apache2 start
|
||||
|
||||
# Using pipefail to ensure grep -v doesn't obscure a gyp failure.
|
||||
$(HOOKS_STAMP) : $(GPERF) $(GYP_FILES)
|
||||
bash -o pipefail -c \
|
||||
"cd $(GIT_SRC) && python build/gyp_chromium --depth=. | \
|
||||
egrep -v '^(Generating )[a-zA-Z0-9_/.-]*(Makefile|mk)$$'"
|
||||
touch $(HOOKS_STAMP)
|
||||
|
||||
$(OBJDIR) : make_obj_dirs
|
||||
|
||||
.PHONY : make_obj_dirs clean
|
||||
make_obj_dirs : $(GIT_SRC)
|
||||
@echo Setting up library directories...
|
||||
@mkdir -p $(GIT_INSTAWEB_LIB_PATH) \
|
||||
$(GENFILES) \
|
||||
$(OBJDIR)/apache/net/instaweb \
|
||||
$(OBJDIR)/apache/pagespeed/opt/ads \
|
||||
$(OBJDIR)/apache/pagespeed/kernel/base \
|
||||
$(OBJDIR)/apache/pagespeed/kernel/cache \
|
||||
$(OBJDIR)/apache/pagespeed/kernel/html \
|
||||
$(OBJDIR)/apache/pagespeed/kernel/http \
|
||||
$(OBJDIR)/apache/pagespeed/kernel/image \
|
||||
$(OBJDIR)/apache/pagespeed/kernel/image/testdata/gif \
|
||||
$(OBJDIR)/apache/pagespeed/kernel/image/testdata/jpeg \
|
||||
$(OBJDIR)/apache/pagespeed/kernel/image/testdata/png \
|
||||
$(OBJDIR)/apache/pagespeed/kernel/image/testdata/pngsuite \
|
||||
$(OBJDIR)/apache/pagespeed/kernel/image/testdata/pngsuite/gif \
|
||||
$(OBJDIR)/apache/pagespeed/kernel/image/testdata/resized \
|
||||
$(OBJDIR)/apache/pagespeed/kernel/image/testdata/webp \
|
||||
$(OBJDIR)/apache/pagespeed/kernel/js \
|
||||
$(OBJDIR)/apache/pagespeed/kernel/sharedmem \
|
||||
$(OBJDIR)/apache/pagespeed/kernel/thread \
|
||||
$(OBJDIR)/apache/pagespeed/kernel/util \
|
||||
$(OBJDIR)/apache/pagespeed/install \
|
||||
$(OBJDIR)/apache/pagespeed/apache \
|
||||
$(OBJDIR)/apache/pagespeed/automatic \
|
||||
$(OBJDIR)/apache/pagespeed/automatic/public \
|
||||
$(OBJDIR)/apache/pagespeed/controller \
|
||||
$(OBJDIR)/apache/pagespeed/system \
|
||||
$(OBJDIR)/apache/pagespeed/system/public \
|
||||
$(OBJDIR)/css_parser
|
||||
@cd $(OBJDIR)/apache/net/instaweb; mkdir -p \
|
||||
config htmlparse/public http/public http/testdata \
|
||||
js/public public rewriter/public rewriter/testdata spriter \
|
||||
spriter/public util/public
|
||||
|
||||
clean :
|
||||
rm -rf $(OBJDIR)
|
||||
rm -rf $(GIT_SRC)/out
|
||||
|
||||
# Install gperf if it doesn't exist
|
||||
GPERF = /usr/bin/gperf
|
||||
$(GPERF) :
|
||||
sudo apt-get install gperf
|
||||
|
||||
.PHONY : echo_var echo_vars
|
||||
echo_var :
|
||||
@echo $($(VAR))
|
||||
|
||||
echo_vars :
|
||||
@echo OBJDIR=$(OBJDIR)
|
||||
@echo G3_ROOT=$(G3_ROOT)
|
||||
@echo SANDBOX=$(SANDBOX)
|
||||
@echo GOOGLE_PROTO_FILES=$(GOOGLE_PROTO_FILES)
|
||||
@echo GIT_SRC=$(GIT_SRC)
|
||||
@echo GYP_MANIFEST=$(GYP_MANIFEST)
|
||||
Executable
+51
@@ -0,0 +1,51 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2010 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
# See bug 3103898 and
|
||||
# http://carlosrivero.com/fix-apache
|
||||
#---no-space-left-on-device-couldnt-create-accept-lock
|
||||
#
|
||||
# This script might help cleanup any leftover resources that prevent
|
||||
# Apache from restarting. The error message might look a little something
|
||||
# like this:
|
||||
#
|
||||
# [Sat Oct 16 21:22:46 2010] [warn] pid file /usr/local/apache2/logs/httpd.pid
|
||||
# overwritten -- Unclean shutdown of previous Apache run?
|
||||
#
|
||||
# [Sat Oct 16 21:22:46 2010] [emerg] (28)No space left on device: Couldn't
|
||||
# create accept lock (/usr/local/apache2/logs/accept.lock.16025) (5)
|
||||
#
|
||||
# Usage:
|
||||
#
|
||||
# devel/apache_cleanup $USER
|
||||
#
|
||||
# You may want to see the owners of the IPC blocks by running ipcs -s
|
||||
# manually. For example, you might need to run:
|
||||
#
|
||||
# sudo devel/apache_cleanup www-data
|
||||
# or
|
||||
# sudo devel/apache_cleanup root
|
||||
|
||||
apache_user=$1
|
||||
|
||||
for ipsemId in $(ipcs -s | grep $apache_user | cut -f 2 -d ' '); do
|
||||
echo ipcrm -s $ipsemId
|
||||
ipcrm -s $ipsemId || true
|
||||
done
|
||||
for ipsemId in $(ipcs -m | grep $apache_user | cut -f 2 -d ' '); do
|
||||
echo ipcrm -m $ipsemId
|
||||
ipcrm -m $ipsemId || true
|
||||
done
|
||||
Executable
+48
@@ -0,0 +1,48 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2011 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
# Script to enable SSL on the given port for Apache, usually in ~/apache2.
|
||||
#
|
||||
# usage: apache_configure_https_port.sh apache-root-directory https-port
|
||||
|
||||
APACHE_ROOT=$1
|
||||
HTTPS_PORT=$2
|
||||
|
||||
# If either argument is missing, do nothing (assume that https is disabled).
|
||||
[ -z "$APACHE_ROOT" ] && exit 0
|
||||
[ -z "$HTTPS_PORT" ] && exit 0
|
||||
|
||||
# Change the port only if we can find the file where we expect it.
|
||||
conf_file=$APACHE_ROOT/conf/extra/httpd-ssl.conf
|
||||
if [ -e $conf_file ]; then
|
||||
sed -e '/^[ ]*Listen /s/^.*$/Listen '"$HTTPS_PORT"'/' \
|
||||
-e '/<VirtualHost /s/.*:[0-9]*/<VirtualHost localhost:'"$HTTPS_PORT"'/' \
|
||||
-e '/^[ ]*ServerName /s/^.*$/ServerName '"$(hostname):$HTTPS_PORT"'/' \
|
||||
${conf_file} > ${conf_file}.$$
|
||||
if mv -f ${conf_file}.$$ ${conf_file}; then
|
||||
echo HTTPS was enabled on port $HTTPS_PORT in $conf_file
|
||||
else
|
||||
rm -f ${conf_file}.$$
|
||||
echo FAILED: mv ${conf_file}.$$ ${conf_file}
|
||||
echo Cannot enable HTTPS on port $HTTPS_PORT in $conf_file
|
||||
fi
|
||||
else
|
||||
echo $conf_file does not exist.
|
||||
echo Consider updating devel/Makefile and/or devel/$(basename $0)
|
||||
exit 1
|
||||
fi
|
||||
|
||||
exit 0
|
||||
Executable
+167
@@ -0,0 +1,167 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2012 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
# Script to enable PHP5 in Apache assuming it has already been installed into
|
||||
# the standard Ubuntu directory (/etc/apache, /usr/apache) rather than the
|
||||
# ~/apache2 directory we use [in other words, modules have been apt install'd
|
||||
# rather than built from source].
|
||||
#
|
||||
# PHP5 can be installed using the following commands:
|
||||
# apt-get install php5-common php5
|
||||
# apt-get install php5-cgi php5-cli libapache2-mod-fcgid # * worker MPM only *
|
||||
#
|
||||
# Note that it does not fail if any of these are not installed since we don't
|
||||
# want to force site admins to install them just to run some tests.
|
||||
#
|
||||
# usage: apache_configure_php5_from_etc_php5.sh apache-root-directory
|
||||
APACHE_ROOT=$1
|
||||
if [ -z "${APACHE_ROOT}" ]; then
|
||||
echo "Usage: $0 <apache-root-directory>"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
HTTPD_CONF=${APACHE_ROOT}/conf/httpd.conf
|
||||
DST_PHP5_CONFIG=${APACHE_ROOT}/conf/php5.conf
|
||||
DST_PHP5_MODULE=${APACHE_ROOT}/modules/libphp5.so
|
||||
DST_FCGID_CONFIG=${APACHE_ROOT}/conf/fcgid.conf
|
||||
DST_FCGID_MODULE=${APACHE_ROOT}/modules/mod_fcgid.so
|
||||
|
||||
# Note: contains an embedded TAB.
|
||||
WS="[ ]"
|
||||
|
||||
# Early exit if everything seems to be installed already.
|
||||
grep -q "^${WS}*Include${WS}.*conf/php5.conf${WS}*$" "${HTTPD_CONF}" && \
|
||||
grep -q "^${WS}*Include${WS}.*conf/fcgid.conf${WS}*$" "${HTTPD_CONF}"
|
||||
if [[ $? -eq 0 && \
|
||||
-r "${DST_PHP5_CONFIG}" && \
|
||||
-r "${DST_PHP5_MODULE}" && \
|
||||
-r "${DST_FCGID_MODULE}" ]]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
# Hardwire where we get things from since it's a Ubuntu standard.
|
||||
SRC_PHP5_INIDIR=/etc/php5/apache2
|
||||
SRC_PHP5_MODULE=/usr/lib/apache2/modules/libphp5.so
|
||||
|
||||
# We want our own build of fcgid since we want to test with 2.2, while the
|
||||
# packages are for 2.4
|
||||
SRC_FCGID_MODULE=${APACHE_ROOT}/modules/mod_fcgid-src_build.so
|
||||
|
||||
# Bail if PHP5 isn't installed [where we expect it].
|
||||
|
||||
if [[ ! -r "/usr/bin/php5-cgi" ||
|
||||
! -r "${SRC_FCGID_MODULE}" ]]; then
|
||||
echo "*** PHP5 is not installed, or is not installed where we expect" >&2
|
||||
echo " under /etc/php5 and /usr/lib/apache2. Please run:" >&2
|
||||
echo " sudo apt-get install php5-common php5" >&2
|
||||
echo " sudo apt-get install php5-cgi php5-cli libapache2-mod-fcgid">&2
|
||||
echo ""
|
||||
echo " You may also need to rm -rf ${APACHE_ROOT}" >&2
|
||||
echo " and re-run install/build_development_apache.sh"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# Tricky grep'ing to find the correct Directory section in httpd.conf:
|
||||
PAT1="<Directory${WS}${WS}*${APACHE_ROOT}/htdocs${WS}*>"
|
||||
PAT2="<Directory${WS}${WS}*\"${APACHE_ROOT}/htdocs\"${WS}*>"
|
||||
HTDOCS_OPEN_LINENO=$(
|
||||
egrep -n "${PAT1}|${PAT2}" "${HTTPD_CONF}" \
|
||||
| sed -e 's/:.*//')
|
||||
if [ -z "$HTDOCS_OPEN_LINENO" ]; then
|
||||
echo
|
||||
echo "*** ${HTTPD_CONF} does not have a line like:" >&2
|
||||
echo ' <Directory "'${APACHE_ROOT}/htdocs'">' >&2
|
||||
echo " which is the expected document root for the installation" >&2
|
||||
echo " and whose entry needs to be updated. ABORTING." >&2
|
||||
exit 1
|
||||
fi
|
||||
HTDOCS_CLOSE_LINENO=$(
|
||||
tail -n +${HTDOCS_OPEN_LINENO} "${HTTPD_CONF}" \
|
||||
| grep -n "^${WS}*</${WS}*Directory${WS}*>" \
|
||||
| head -1 \
|
||||
| sed -e 's/:.*//')
|
||||
OPTIONS_LINENO=$(
|
||||
tail -n +${HTDOCS_OPEN_LINENO} "${HTTPD_CONF}" \
|
||||
| head -${HTDOCS_CLOSE_LINENO:-999999} \
|
||||
| grep -i "^${WS}${WS}*Options${WS}.*[+]\?ExecCGI")
|
||||
if [ -z "$OPTIONS_LINENO" ]; then
|
||||
[ -n "${HTDOCS_CLOSE_LINENO}" ] && \
|
||||
HTDOCS_CLOSE_LINENO=$((HTDOCS_OPEN_LINENO + HTDOCS_CLOSE_LINENO - 1))
|
||||
sed -e "${HTDOCS_CLOSE_LINENO:-$}"'i\
|
||||
# Required for mod_fcgi which is required for PHP when using worker MPM.\
|
||||
Options +ExecCGI' "${HTTPD_CONF}" > "${HTTPD_CONF}".tmp
|
||||
mv "${HTTPD_CONF}".tmp "${HTTPD_CONF}"
|
||||
fi
|
||||
|
||||
# Add the necessary lines to httpd.conf if/as necessary.
|
||||
fgrep -q "LoadModule fcgid_module modules/mod_fcgid.so" "${HTTPD_CONF}"
|
||||
if [ $? -ne 0 ]; then
|
||||
# Backwards compatibility: check if PHP5 for Apache 2.2 prefork is setup.
|
||||
grep -q "^${WS}*LoadModule${WS}${WS}*php5_module${WS}.*modules/libphp5.so${WS}*$" "${HTTPD_CONF}"
|
||||
if [ $? -eq 0 ]; then
|
||||
# Remove the lines that just setup PHP5 for APache 2.2 prefork.
|
||||
sed -e "/^${WS}*LoadModule${WS}${WS}*php5_module${WS}.*/d" \
|
||||
-e "/^${WS}*Include${WS}${WS}*conf\/php5.conf${WS}*$/d" \
|
||||
"${HTTPD_CONF}" > "${HTTPD_CONF}.tmp"
|
||||
mv "${HTTPD_CONF}.tmp" "${HTTPD_CONF}"
|
||||
fi
|
||||
# Insert the all-singing all dancing lines for Apache 2.2 prefork/worker.
|
||||
# Unconditionally use mod_fcgid.
|
||||
cat - >> "${HTTPD_CONF}" <<EOF
|
||||
LoadModule fcgid_module modules/mod_fcgid.so
|
||||
Include conf/fcgid.conf
|
||||
AddHandler fcgid-script .php
|
||||
FCGIWrapper /usr/bin/php-cgi .php
|
||||
EOF
|
||||
fi
|
||||
|
||||
# Copy the config files over as necessary.
|
||||
if [ ! -f "${DST_PHP5_CONFIG}" ]; then
|
||||
cat - > "${DST_PHP5_CONFIG}" <<EOF
|
||||
<IfModule php5_module>
|
||||
AddHandler php5-script .php
|
||||
DirectoryIndex index.html index.php
|
||||
AddType text/html .php
|
||||
AddType application/x-httpd-php-source phps
|
||||
PHPIniDir ${SRC_PHP5_INIDIR}
|
||||
</IfModule>
|
||||
EOF
|
||||
fi
|
||||
|
||||
if [ ! -f "${DST_FCGID_CONFIG}" ]; then
|
||||
cat - > "${DST_FCGID_CONFIG}" <<EOF
|
||||
<IfModule mod_fcgid.c>
|
||||
AddHandler fcgid-script .fcgi
|
||||
FcgidConnectTimeout 20
|
||||
FcgidProcessTableFile fcgid/fcgid_shm
|
||||
FcgidIPCDir fcgid/sock
|
||||
</IfModule>
|
||||
EOF
|
||||
fi
|
||||
|
||||
# Link the modules as necessary.
|
||||
if [[ ! -f "${DST_PHP5_MODULE}" && -f "${SRC_PHP5_MODULE}" ]]; then
|
||||
ln -s "${SRC_PHP5_MODULE}" "${DST_PHP5_MODULE}"
|
||||
fi
|
||||
if [ ! -f "${DST_FCGID_MODULE}" ]; then
|
||||
ln -s "${SRC_FCGID_MODULE}" "${DST_FCGID_MODULE}"
|
||||
fi
|
||||
|
||||
# Create the mod_fcgid directories.
|
||||
[ -d "${APACHE_ROOT}"/fcgid ] || mkdir "${APACHE_ROOT}"/fcgid
|
||||
[ -d "${APACHE_ROOT}"/fcgid/sock ] || mkdir "${APACHE_ROOT}"/fcgid/sock
|
||||
|
||||
exit 0
|
||||
Executable
+33
@@ -0,0 +1,33 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2012 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
# Script to create a server certificate (and key) file for Apache,
|
||||
# usually in ~/apache2.
|
||||
#
|
||||
# usage: apache_create_server_certificate.sh apache-root-directory
|
||||
|
||||
APACHE_ROOT=$1
|
||||
|
||||
# Create a cert file iff we don't already have one.
|
||||
if [ ! -e $APACHE_ROOT/conf/server.crt ]; then
|
||||
openssl req -new -x509 -days 36500 -sha1 -newkey rsa:1024 -nodes \
|
||||
-keyout $APACHE_ROOT/conf/server.key \
|
||||
-out $APACHE_ROOT/conf/server.crt \
|
||||
-subj "/O=Company/OU=Department/CN=$(hostname)"
|
||||
echo Certificate files were created: $APACHE_ROOT/conf/server.{key,crt}
|
||||
fi
|
||||
|
||||
exit 0
|
||||
Executable
+85
@@ -0,0 +1,85 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2010 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
# Script to install a debuggable mod_pagespeed.so into the Apache
|
||||
# distribution, usually in ~/apache2.
|
||||
|
||||
APACHE_DEBUG_ROOT=$1
|
||||
APACHE_DEBUG_PORT=$2
|
||||
SRC_TREE=$3
|
||||
|
||||
mkdir -p $APACHE_DEBUG_ROOT/pagespeed/cache
|
||||
chmod a+rwx $APACHE_DEBUG_ROOT/pagespeed/cache
|
||||
|
||||
# Check to see of mod_pagespeed is already loaded into httpd.conf
|
||||
conf_file=$APACHE_DEBUG_ROOT/conf/httpd.conf
|
||||
if [ -e $conf_file ]; then
|
||||
if grep -q "^Listen $APACHE_DEBUG_PORT\$" $conf_file; then
|
||||
echo $conf_file is set up to listen on the port $APACHE_DEBUG_PORT.
|
||||
else
|
||||
echo $conf_file is not set up to listen on port $APACHE_DEBUG_PORT
|
||||
echo please remedy
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if grep -q "LoadModule pagespeed_module" $conf_file; then
|
||||
echo mod_pagespeed is already loaded in config file $conf_file
|
||||
else
|
||||
echo adding mod_pagespeed into apache config file $conf_file
|
||||
cat $SRC_TREE/install/common/pagespeed.load.template | \
|
||||
sed s#@@APACHE_MODULEDIR@@#$APACHE_DEBUG_ROOT/modules# | \
|
||||
sed s#@@COMMENT_OUT_DEFLATE@@## >> $conf_file
|
||||
echo Include $APACHE_DEBUG_ROOT/conf/pagespeed.conf >> $conf_file
|
||||
fi
|
||||
|
||||
# Now hack the file to also load mod_h2.
|
||||
MOD_H2=$APACHE_DEBUG_ROOT/modules/mod_http2.so
|
||||
if [ -f $MOD_H2 ]; then
|
||||
if grep -q "LoadModule http2_module" $conf_file; then
|
||||
echo http2_module is already loaded in config file $conf_file
|
||||
else
|
||||
echo adding http2_module into apache config file $conf_file
|
||||
cat $conf_file | sed -e '/pagespeed.conf/i\
|
||||
\
|
||||
# Load mod_http2 to test mod_pagespeed integration. This is done before\
|
||||
# pagespeed.conf so it can detect it.\
|
||||
LoadModule http2_module '$MOD_H2'\
|
||||
Protocols h2 http/1.1 \
|
||||
Protocols h2c http/1.1\
|
||||
' > $conf_file.sp
|
||||
mv $conf_file.sp $conf_file
|
||||
fi
|
||||
else
|
||||
echo "No mod_http2 in $APACHE_DEBUG_ROOT/modules, so not loading"
|
||||
fi
|
||||
|
||||
# pagespeed_libraries.conf was added later, so check for it separately.
|
||||
libraries_conf_file="$APACHE_DEBUG_ROOT/conf/pagespeed_libraries.conf"
|
||||
if grep -q "Include $libraries_conf_file" $conf_file; then
|
||||
echo pagespeed_libraries.conf is already loaded by $conf_file
|
||||
else
|
||||
echo adding pagespeed_libraries.conf include to $conf_file
|
||||
cp -f $SRC_TREE/net/instaweb/genfiles/conf/pagespeed_libraries.conf \
|
||||
$libraries_conf_file
|
||||
echo Include $libraries_conf_file >> $conf_file
|
||||
fi
|
||||
else
|
||||
echo "$conf_file does not exist. Consider updating devel/Makefile and/or"
|
||||
echo "devel/apache_install.sh"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
exit 0
|
||||
Executable
+92
@@ -0,0 +1,92 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2011 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
# Rotate the logs in the apache logs directory specified on the command line,
|
||||
# and gzip them, then erase old logs if disk usage is over 85%. Note that
|
||||
# apache must be stopped when we do this. Note also that we take pains not to
|
||||
# erase the newly-rotated logs, as those are the ones we are likely to care
|
||||
# deeply about. This may mean the disk stays full, but logs are pretty
|
||||
# compressible so it's unlikely.
|
||||
set -e
|
||||
now() {
|
||||
date '+%Y%m%d-%H%M'
|
||||
}
|
||||
stamp=$(now)
|
||||
if [ $# -ne 1 -o ! -d "$1" ]; then
|
||||
echo "Usage: apache_rotate_logs.sh logs_directory" >&2
|
||||
exit 1
|
||||
fi
|
||||
cd "$1"
|
||||
if [ -f "error_log.gz" ]; then
|
||||
# Clean up after partial log rotation
|
||||
echo "Cleaning up error_log.gz"
|
||||
mv error_log.gz error_log.$stamp.gz
|
||||
cleaned_up=true
|
||||
fi
|
||||
if [ -f "access_log.gz" ]; then
|
||||
# Clean up after partial log rotation
|
||||
echo "Cleaning up access_log.gz"
|
||||
mv access_log.gz access_log.$stamp.gz
|
||||
cleaned_up=true
|
||||
fi
|
||||
if [ ! -f "error_log" -a ! -f "access_log" ]; then
|
||||
# No logs to rotate.
|
||||
echo "No new logs to rotate"
|
||||
else
|
||||
# gzip can be kind of slow, so parallelize.
|
||||
# But gzip well, as this stuff eats a ton of space.
|
||||
if [ -f "error_log" ]; then
|
||||
echo "Gzipping error_log"
|
||||
gzip -9 error_log &
|
||||
fi
|
||||
if [ -f "access_log" ]; then
|
||||
echo "Gzipping access_log"
|
||||
gzip -9 access_log
|
||||
fi
|
||||
wait
|
||||
if [ ! -z "$cleaned_up" ]; then
|
||||
# If we used stamp, create a fresh one (effectively spin)
|
||||
old_stamp=stamp
|
||||
stamp=$(now)
|
||||
while [ "$stamp" == "$old_stamp" ]; do
|
||||
sleep 1
|
||||
stamp=$(now)
|
||||
done
|
||||
fi
|
||||
# Now timestamp the just-compressed logs.
|
||||
if [ -f "error_log.gz" ]; then
|
||||
echo "Timestamping error_log"
|
||||
mv error_log.gz error_log.$stamp.gz
|
||||
fi
|
||||
if [ -f "access_log.gz" ]; then
|
||||
echo "Timestamping access_log"
|
||||
mv access_log.gz access_log.$stamp.gz
|
||||
fi
|
||||
fi
|
||||
# Clean up old logs if the disk is getting full (>85%).
|
||||
df_percent() {
|
||||
df . --output=pcent | egrep -o '[0-9]+'
|
||||
}
|
||||
if [ $(df_percent) -ge 85 ]; then
|
||||
echo "Cleaning required."
|
||||
for log in $(/bin/ls -1tr *_log.[0-9]* | head -n -2); do
|
||||
echo "Cleaning $log"
|
||||
rm $log
|
||||
if [ $(df_percent) -lt 85 ]; then
|
||||
break
|
||||
fi
|
||||
done
|
||||
fi
|
||||
Executable
+96
@@ -0,0 +1,96 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Note: you might need to type your password a few times, once early, and once
|
||||
# at the end.
|
||||
#
|
||||
# This should be run on a release branch to make sure we can make a tarball and
|
||||
# at least build it on our workstations. It will also copy the tarball into
|
||||
# ~/release (where the binaries usually go).
|
||||
#
|
||||
# Like most of our dev tools this assumes Ubuntu 14 LTS. If that isn't what you
|
||||
# have, it's probably easiest to run this in a VM.
|
||||
#
|
||||
# Note that if this fails you may need to tweak the file list inside
|
||||
# devel/create_distro_tarball.sh
|
||||
|
||||
set -e # exit script if any command returns an error
|
||||
set -u # exit the script if any variable is uninitialized
|
||||
|
||||
function usage {
|
||||
echo "Usage: devel/build_release_tarball.sh <beta|stable>"
|
||||
exit 1
|
||||
}
|
||||
|
||||
if [ $# -ne 1 ]; then
|
||||
usage
|
||||
fi
|
||||
|
||||
if [ ! -d net/instaweb ]; then
|
||||
echo "This script must be run from the root of the mps checkout."
|
||||
exit 1
|
||||
fi
|
||||
|
||||
source net/instaweb/public/VERSION
|
||||
RELEASE="$MAJOR.$MINOR.$BUILD.$PATCH"
|
||||
CHANNEL="$1"
|
||||
|
||||
deps="libpng12-dev libicu-dev libssl-dev libjpeg-dev realpath build-essential
|
||||
pkg-config gperf unzip libapr1-dev libaprutil1-dev apache2-dev"
|
||||
if dpkg-query -Wf '${Status}\n' $deps 2>&1 | \
|
||||
grep -v "install ok installed"; then
|
||||
# Only run apt-get install if one of the deps is not already installed.
|
||||
# See: http://stackoverflow.com/questions/1298066
|
||||
sudo apt-get install $deps
|
||||
fi
|
||||
|
||||
RELEASE_DIR="$HOME/release/$RELEASE"
|
||||
mkdir -p "$RELEASE_DIR"
|
||||
REVISION="$(build/lastchange.sh "$PWD" | sed 's/LASTCHANGE=//')"
|
||||
TARBALL="$RELEASE_DIR/mod-pagespeed-$CHANNEL-$RELEASE-r$REVISION.tar.bz2"
|
||||
devel/create_distro_tarball.sh "$TARBALL"
|
||||
|
||||
echo "Tarball should now be at $TARBALL"
|
||||
|
||||
# Try to build it
|
||||
BUILD_DIR="$(mktemp -d)"
|
||||
echo "Doing a test build inside $BUILD_DIR"
|
||||
cd "$BUILD_DIR"
|
||||
|
||||
if openssl version | grep "^OpenSSL 1[.]0[.][01]\|^OpenSSL 0[.]"; then
|
||||
echo "Your openssl version is too old to build the tarball; we need 1.0.2+"
|
||||
echo "Building 1.0.2 from source..."
|
||||
OPENSSL_VERSION="1.0.2j"
|
||||
wget "https://www.openssl.org/source/openssl-${OPENSSL_VERSION}.tar.gz"
|
||||
tar -xzvf "openssl-${OPENSSL_VERSION}.tar.gz"
|
||||
cd openssl-"${OPENSSL_VERSION}"
|
||||
./config --prefix="$BUILD_DIR" shared
|
||||
make
|
||||
make install
|
||||
export SSL_CERT_DIR=/etc/ssl/certs
|
||||
export PKG_CONFIG_PATH="$BUILD_DIR/lib/pkgconfig"
|
||||
export LD_LIBRARY_PATH="$BUILD_DIR/lib"
|
||||
cd "$BUILD_DIR"
|
||||
fi
|
||||
|
||||
tar xjf "$TARBALL"
|
||||
cd modpagespeed*
|
||||
./generate.sh -Dsystem_include_path_apr=/usr/include/apr-1.0/ \
|
||||
-Dsystem_include_path_httpd=/usr/include/apache2
|
||||
cd src
|
||||
make -j6
|
||||
out/Debug/mod_pagespeed_test
|
||||
# These tests fail because they are golded against a specific version of
|
||||
# compression libraries.
|
||||
# TODO(sligocki): Could we change the tests to be less fragile or test in a
|
||||
# different way in this case?
|
||||
BROKEN_TESTS=\
|
||||
ImageConverterTest.OptimizePngOrConvertToJpeg:\
|
||||
ImageConverterTest.ConvertOpaqueGifToJpeg:\
|
||||
JpegOptimizerTest.ValidJpegsLossy:\
|
||||
JpegOptimizerTest.ValidJpegLossyAndColorSampling:\
|
||||
JpegOptimizerTest.ValidJpegsProgressiveAndLossy
|
||||
out/Debug/pagespeed_automatic_test --gtest_filter=-$BROKEN_TESTS
|
||||
|
||||
echo "Cleaning up"
|
||||
rm -rf "$BUILD_DIR"
|
||||
|
||||
Executable
+229
@@ -0,0 +1,229 @@
|
||||
#!/bin/bash
|
||||
|
||||
set -u # exit the script if any variable is uninitialized
|
||||
|
||||
this_dir=$(dirname "${BASH_SOURCE[0]}")
|
||||
cd "$this_dir/.."
|
||||
src="$PWD"
|
||||
|
||||
if [ ! -d install ]; then
|
||||
echo "Expected to see install."
|
||||
exit 1
|
||||
fi
|
||||
|
||||
source "$src/install/shell_utils.sh" || exit 1
|
||||
|
||||
# In order to set up the pagespeed.conf file correctly for external cache
|
||||
# tests, we must have a special env variable established. The easiest way
|
||||
# to do that is to re-run this script under 'run_program_with_<cache-type>.sh',
|
||||
# which executes a command and then brings down external cache server.
|
||||
#
|
||||
# So when we run this script, if we don't already have our external cache
|
||||
# configured, we just re-run the script under run_program_with_*.sh. That will
|
||||
# establish a single external cache server for all the unit tests and system
|
||||
# tests.
|
||||
|
||||
# One weird trick for testing a variable for whether it is set, without
|
||||
# triggering an error due to "set -u" above:
|
||||
# http://stackoverflow.com/questions/3601515/how-to-check-if-a-variable-is-set-in-bash
|
||||
if [[ -z ${MEMCACHED_PORT+x} ]]; then
|
||||
exec "$src/install/run_program_with_memcached.sh" "$0" "$@"
|
||||
fi
|
||||
if [[ -z ${REDIS_PORT+x} ]]; then
|
||||
exec "$src/install/run_program_with_redis.sh" "$0" "$@"
|
||||
fi
|
||||
|
||||
valgrind="/usr/bin/valgrind"
|
||||
if [ ! -e $valgrind ]; then
|
||||
echo "***" You must install the system valgrind into $valgrind
|
||||
echo sudo apt-get install valgrind
|
||||
exit 1
|
||||
fi
|
||||
|
||||
install_log_file=/tmp/install.log.$$
|
||||
valgrind_test_out=/tmp/valgrind.test.out.$$
|
||||
valgrind_httpd_out=/tmp/valgrind.httpd.out.$$
|
||||
system_test_log=/tmp/system_test.log.$$
|
||||
apache_test_log=/tmp/apache_test.log.$$
|
||||
exit_status=0
|
||||
failures=""
|
||||
run_unit_tests=1
|
||||
OPTIONS="${OPTIONS:-""} VALGRIND_TEST=1"
|
||||
|
||||
if [ $1 == "--no_unit_tests" ]; then
|
||||
run_unit_tests="0"
|
||||
shift
|
||||
fi
|
||||
apache_debug_root=$1
|
||||
shift
|
||||
server=$1
|
||||
shift
|
||||
|
||||
function record_error() {
|
||||
exit_status=1
|
||||
failures="$failures $@"
|
||||
echo FAIL: $@
|
||||
}
|
||||
|
||||
function check_valgrind_log_for_problems() {
|
||||
# TODO(jmaessen): Consider checking 'Use of uninitialized', but
|
||||
# that will require image library exclusions.
|
||||
grep 'Invalid .* of size' $2 && \
|
||||
record_error "$1 contains invalid memory operations."
|
||||
grep 'definitely lost: [1-9][0-9,]* bytes in [1-9][0-9,]* blocks' $2 && \
|
||||
record_error "$1 Directly lost bytes"
|
||||
grep "indirectly lost: [1-9][0-9,]* bytes in [1-9][0-9,]* blocks" $2 && \
|
||||
record_error "$1 Indirectly Lost bytes"
|
||||
}
|
||||
|
||||
# Because valgrind is so slow, we want to run it under tee. But tee swallows
|
||||
# the exit status code, so we can get false positives. Instead we ignore the
|
||||
# exit status from tee and search for a pattern in the log that indicates an
|
||||
# error.
|
||||
#
|
||||
# $1 = the program to be run
|
||||
# $2 = the log file
|
||||
# $3 = the error-pattern to search for in the log.
|
||||
function run_and_grep_for_error {
|
||||
echo `date`: Running "$1 in $PWD ..."
|
||||
$1 2>&1 | tee $2
|
||||
grep "$3" $2 >/dev/null
|
||||
if [ $? -eq 0 ]; then
|
||||
record_error "$1 failed: \"$3\" found in $2"
|
||||
fi
|
||||
}
|
||||
|
||||
SUPPRESSIONS="$src/devel/valgrind_suppressions.txt"
|
||||
|
||||
function check_unit_test_for_leaks() {
|
||||
exe=$1
|
||||
shards=$2
|
||||
echo `date`: Running $exe with $valgrind, log to $valgrind_test_out.$exe
|
||||
cd $src
|
||||
# For the unit tests only we use --child-silent-after-fork so that
|
||||
# cross-process communication tests don't trigger false leak warnings
|
||||
# at exit of kids they fork.
|
||||
|
||||
# If one sets envvars GTEST_TOTAL_SHARDS as well as GTEST_SHARD_INDEX
|
||||
# with 0 <= GTEST_SHARD_INDEX < GTEST_TOTAL_SHARDS, gtest will only
|
||||
# execute a portion of tests in a given process, letting us to parallelize
|
||||
# unit test execution.
|
||||
export GTEST_TOTAL_SHARDS=$shards
|
||||
last_shard=$((GTEST_TOTAL_SHARDS - 1))
|
||||
LOGS=
|
||||
for i in $(seq 0 $last_shard); do
|
||||
export GTEST_SHARD_INDEX=$i
|
||||
LOG=$valgrind_test_out.$exe.$i
|
||||
LOGS="$LOGS $LOG"
|
||||
|
||||
echo $valgrind --leak-check=full \
|
||||
--suppressions=$SUPPRESSIONS \
|
||||
--read-var-info=yes --num-callers=20 --child-silent-after-fork=yes \
|
||||
./out/Debug/$exe "2>&1" "|" tee $LOG "&"
|
||||
$valgrind --leak-check=full --suppressions=$SUPPRESSIONS \
|
||||
--read-var-info=yes --num-callers=20 --child-silent-after-fork=yes \
|
||||
./out/Debug/$exe 2>&1 | tee $LOG &
|
||||
done
|
||||
wait
|
||||
|
||||
run_and_grep_for_error "cat $LOGS" $valgrind_test_out.$exe '^\[ FAILED \] '
|
||||
check_valgrind_log_for_problems $exe $valgrind_test_out.$exe
|
||||
}
|
||||
|
||||
# Checks the system-tests using a pagespeed.conf configuration. An
|
||||
# argument must be supplied that will be used as a suffix for log files.
|
||||
function check_system_test_for_leaks() {
|
||||
suffix=$1
|
||||
|
||||
local options="HTTPS_TEST=0 $OPTIONS"
|
||||
if [[ $suffix == "memcached" ]]; then
|
||||
options+=" MEMCACHED_TEST=1"
|
||||
elif [[ $suffix == "redis" ]]; then
|
||||
options+=" REDIS_TEST=1"
|
||||
fi
|
||||
|
||||
echo make apache_debug_install apache_install_conf \
|
||||
OPTIONS="$options" '>&' "$install_log_file"
|
||||
make apache_debug_install apache_install_conf \
|
||||
OPTIONS="$options" >& $install_log_file
|
||||
|
||||
outfile=$valgrind_httpd_out.$suffix
|
||||
echo `date`: Running httpd $valgrind with output spewed to $outfile
|
||||
ps auxww | grep httpd
|
||||
|
||||
echo $valgrind --gen-suppressions=all --leak-check=full --trace-children=yes \
|
||||
--suppressions=$SUPPRESSIONS \
|
||||
$apache_debug_root/bin/httpd --enable-pool-debug \
|
||||
">&" $outfile "&"
|
||||
$valgrind --gen-suppressions=all --leak-check=full --trace-children=yes \
|
||||
--suppressions=$SUPPRESSIONS \
|
||||
$apache_debug_root/bin/httpd --enable-pool-debug \
|
||||
>& $outfile &
|
||||
|
||||
local apache_timeout=30
|
||||
echo -n Waiting up to "$apache_timeout" seconds for valgrind/httpd \
|
||||
to start listening
|
||||
if ! wait_cmd_with_timeout "$apache_timeout" \
|
||||
wget -q --timeout=2 -O/dev/null "http://$server"
|
||||
then
|
||||
record_error apache/valgrind did not start after "$apache_timeout" seconds.
|
||||
return 1
|
||||
fi
|
||||
|
||||
run_and_grep_for_error "$src/pagespeed/apache/system_test.sh \
|
||||
$server" $apache_test_log '^\FAIL\.'
|
||||
|
||||
$apache_debug_root/bin/apachectl graceful-stop
|
||||
|
||||
echo -n Waiting for httpd to actually exit...
|
||||
while [ -f $apache_debug_root/logs/httpd.pid ]; do sleep 1; done
|
||||
echo done.
|
||||
|
||||
echo `date`: Waiting for $valgrind to finish spewing to $outfile
|
||||
wait
|
||||
check_valgrind_log_for_problems httpd $outfile
|
||||
echo `date`: Cleaning up
|
||||
|
||||
tail -12 $outfile | tee $outfile.tail
|
||||
}
|
||||
|
||||
set +u
|
||||
PAGESPEED_TEST_HOST=${PAGESPEED_TEST_HOST:-selfsigned.modpagespeed.com}
|
||||
export PAGESPEED_TEST_HOST
|
||||
set -u
|
||||
|
||||
$apache_debug_root/bin/apachectl graceful-stop
|
||||
if [ $? -ne 0 ]; then
|
||||
record_error restart failed: please see log $install_log_file
|
||||
else
|
||||
if [ $run_unit_tests = "1" ]; then
|
||||
# We use 1 shard here for convenience of memcached setup, since this
|
||||
# test is quick.
|
||||
check_unit_test_for_leaks mod_pagespeed_test 1
|
||||
|
||||
# 3 shards here in hope of using the idle CPU while not overwhelming things
|
||||
# if other things (e.g. checkin.blaze) are parallel to us.
|
||||
check_unit_test_for_leaks pagespeed_automatic_test 3
|
||||
fi
|
||||
|
||||
cd "$src/devel"
|
||||
|
||||
echo Running system tests using a file cache...
|
||||
check_system_test_for_leaks file_cache
|
||||
|
||||
echo Running system tests using memcached...
|
||||
check_system_test_for_leaks memcached
|
||||
|
||||
echo Running system tests using redis...
|
||||
check_system_test_for_leaks redis
|
||||
fi
|
||||
|
||||
if [ $exit_status -eq 0 ]; then
|
||||
echo PASS
|
||||
else
|
||||
echo FAIL: $failures
|
||||
fi
|
||||
echo NOTE: there can be multiple LEAK SUMMARY entries in Valgrid log, which
|
||||
echo can be located in different parts of log, not necessarily in the end.
|
||||
|
||||
exit $exit_status
|
||||
Executable
+18
@@ -0,0 +1,18 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Scans source directories for _test.cc files to find ones that aren't mentioned
|
||||
# in the test gyp file. On success produces no output, otherwise prints the
|
||||
# names of the unreferenced _test.cc files.
|
||||
|
||||
set -u
|
||||
set -e
|
||||
|
||||
this_dir="$(dirname "${BASH_SOURCE[0]}")"
|
||||
cd "$this_dir/.."
|
||||
|
||||
test_gyp="net/instaweb/test.gyp"
|
||||
find net pagespeed -name *_test.cc | while read test_path; do
|
||||
if ! grep -q "$(basename "$test_path")" "$test_gyp"; then
|
||||
echo "$test_path ($(basename "$test_path")) missing from $test_gyp"
|
||||
fi
|
||||
done
|
||||
Executable
+136
@@ -0,0 +1,136 @@
|
||||
#!/bin/bash
|
||||
|
||||
# Run the checkin tests for mod_pagespeed. These help ensure the build won't
|
||||
# break.
|
||||
#
|
||||
# Extra parmeters are passed to make. For example, pass V=1 to get verbose
|
||||
# gyp builds.
|
||||
#
|
||||
# We don't clean by default in checkin tests. That makes checkin tests take way
|
||||
# too long, especially when re-running after a failure. This adds risk because
|
||||
# someone might break the build by checking in a dependence on a file that
|
||||
# cannot be regenerated, but that risk seems low compared with the cost of total
|
||||
# rebuilds.
|
||||
|
||||
echo Starting tests at time `date`
|
||||
|
||||
# Don't leave processes hanging around on exit. "jobs -p" gives all background
|
||||
# processes.
|
||||
trap 'kill $(jobs -p)' SIGINT SIGTERM EXIT
|
||||
|
||||
APACHE_DEBUG_ROOT="$HOME/apache2"
|
||||
|
||||
FAIL=
|
||||
if [ ! -d "$APACHE_DEBUG_ROOT" ]; then
|
||||
echo "You must install a local Apache before running checkin tests, e.g."
|
||||
echo " install/build_development_apache.sh 2.2 prefork"
|
||||
FAIL=true
|
||||
fi
|
||||
|
||||
required_binaries="autoconf g++ gperf libtool valgrind memcached redis-server"
|
||||
missing=""
|
||||
for bin in $required_binaries; do
|
||||
which $bin >/dev/null || missing="$missing $bin"
|
||||
done
|
||||
if [ "$missing" != "" ]; then
|
||||
echo You are missing required packages $missing. Type:
|
||||
echo sudo apt-get install $missing
|
||||
FAIL=true
|
||||
fi
|
||||
|
||||
if ! locale -a | grep -q tr_TR.utf8; then
|
||||
echo "You are missing language-pack-tr-base. Type:"
|
||||
echo "sudo apt-get install language-pack-tr-base"
|
||||
FAIL=true
|
||||
fi
|
||||
|
||||
if [ ! -f /usr/bin/php5-cgi ]; then
|
||||
echo "You are missing php5. Type:"
|
||||
echo "sudo apt-get install php5-cgi"
|
||||
FAIL=true
|
||||
fi
|
||||
|
||||
if [ ! -f $APACHE_DEBUG_ROOT/modules/mod_fcgid-src_build.so ]; then
|
||||
echo "You are missing source build of fcgid. Please re-run "
|
||||
echo "build_development_apache.sh"
|
||||
FAIL=true
|
||||
fi
|
||||
|
||||
this_dir=$(dirname "${BASH_SOURCE[0]}")
|
||||
cd "$this_dir"
|
||||
|
||||
tests_missing=$(./check_tests_are_run.sh)
|
||||
if [ ! -z "$tests_missing" ]; then
|
||||
echo "$tests_missing"
|
||||
FAIL=true
|
||||
fi
|
||||
|
||||
if [ -n "$FAIL" ]; then
|
||||
echo "***" Please correct above errors and try again.
|
||||
exit 1
|
||||
fi
|
||||
|
||||
export OBJDIR=/tmp/instaweb.$$
|
||||
make_log=/tmp/checkin.make.$$
|
||||
blaze_log=/tmp/checkin.blaze.$$
|
||||
|
||||
function kill_subprocesses() {
|
||||
echo "^C caught by $0, killing jobs..."
|
||||
kill -INT $(jobs -p)
|
||||
|
||||
# Make is resilient to kills, partially due to our recursive make calls.
|
||||
# Also we need to be wary of other 'make' processes on the system for
|
||||
# different clients, but we always use OBJDIR=$OBJDIR on the command-line for
|
||||
# our recursive makes. So keep finding them and killing them until they are
|
||||
# all dead dead dead.
|
||||
|
||||
continue=1
|
||||
while [ $continue -eq 1 ];
|
||||
do
|
||||
# TODO(jmarantz): jmaessen suggests: How about
|
||||
# processes=$(ps auxw | awk "/[m]ake OBJDIR=$OBJDIR/{ print \$2 }")
|
||||
# This would be more silent. But I'm inclined to leave it noisy for
|
||||
# now until we are confident it's working well.
|
||||
ps auxw | grep "make OBJDIR=$OBJDIR" | grep -v grep
|
||||
|
||||
if [ $? -eq 0 ]; then
|
||||
processes=$(ps auxw|grep "make OBJDIR=$OBJDIR"|awk '{ print $2 }')
|
||||
kill -TERM $processes
|
||||
sleep 5
|
||||
else
|
||||
# All done. Let the 'checkin' script itself exit.
|
||||
continue=0
|
||||
fi
|
||||
done
|
||||
}
|
||||
|
||||
trap '{ kill_subprocesses; exit 1; }' INT
|
||||
|
||||
echo "$this_dir/checkin.make $* &> $make_log &"
|
||||
rm -f "$make_log"
|
||||
touch "$make_log"
|
||||
echo $PWD
|
||||
# TODO(jefftk): combine checkin and checkin.make
|
||||
./checkin.make "$@" &> "$make_log" &
|
||||
make_pid=$!
|
||||
|
||||
# Show make's output as it runs...
|
||||
tail -f $make_log &
|
||||
|
||||
exit_status=0
|
||||
|
||||
# Wait for make to finish.
|
||||
wait $make_pid
|
||||
MAKE_STATUS="$?"
|
||||
|
||||
if [ "$MAKE_STATUS" = "0" ]; then
|
||||
echo checkin.make Passed.
|
||||
rm "$make_log"
|
||||
else
|
||||
echo "*** checkin.make failed: check $make_log for details. Last 4 lines:"
|
||||
tail -n 4 "$make_log"
|
||||
exit_status=1
|
||||
fi
|
||||
|
||||
echo Exiting checkin at "$(date)" with status "$exit_status"
|
||||
exit $exit_status
|
||||
Executable
+79
@@ -0,0 +1,79 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# This script is intended to be run from 'checkin'. It runs a series of tests,
|
||||
# noting which ones failed, and allowing re-running only the failed ones if
|
||||
# needed.
|
||||
|
||||
this_dir=$(dirname "${BASH_SOURCE[0]}")
|
||||
cd "$this_dir"
|
||||
|
||||
# When a single system test fails, keep running until the end of the test
|
||||
# script, and then print out all failing tests. While this isn't a better flow
|
||||
# for interactive use for all users, for system tests it allows you to see the
|
||||
# full list of system tests that failed so you can iterate on them or test them
|
||||
# for flakiness.
|
||||
export CONTINUE_AFTER_FAILURE=true
|
||||
|
||||
source checkin_test_helpers.sh
|
||||
|
||||
export OBJDIR=${OBJDIR:-/tmp/instaweb.$$}
|
||||
make_args_array=($MAKE_ARGS)
|
||||
mkdir -p "$OBJDIR"
|
||||
|
||||
failed_tests=""
|
||||
prep_failures=""
|
||||
for prep in $(make echo_checkin_prep); do
|
||||
run_noisy_command_showing_log "$OBJDIR"/"$prep".log "$prep" \
|
||||
make "${make_args_array[@]}" "$prep"
|
||||
if [ "$?" -ne "0" ]; then
|
||||
prep_failures+=" $prep"
|
||||
fi
|
||||
done
|
||||
|
||||
if [ ! -z "$prep_failures" ]; then
|
||||
echo checkin_prep failed: "$prep_failures"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ "$#" -eq 0 ]; then
|
||||
tests=( \
|
||||
apache_test \
|
||||
apache_release_test \
|
||||
apache_system_tests \
|
||||
pagespeed_automatic_smoke_test \
|
||||
)
|
||||
else
|
||||
tests=("$@")
|
||||
fi
|
||||
|
||||
for testname in "${tests[@]}"; do
|
||||
is_system_test=$(echo "$testname" | grep -c system_test)
|
||||
if [ "$is_system_test" = 1 ]; then
|
||||
SERVER="Apache"
|
||||
LOCKFILE="$APACHE_LOCKFILE"
|
||||
echo -n Waiting for "$SERVER" lock "$LOCKFILE" ...
|
||||
acquire_lock "$SERVER" "$LOCKFILE"
|
||||
print_elapsed_time
|
||||
echo ""
|
||||
fi
|
||||
run_noisy_command_showing_log "$OBJDIR/${testname}.log" "$testname" \
|
||||
make "${make_args_array[@]}" "$testname"
|
||||
if [ "$?" -ne "0" ]; then
|
||||
failed_tests+=" $testname"
|
||||
fi
|
||||
if [ "$is_system_test" = 1 ]; then
|
||||
run_noisy_command_showing_log "$OBJDIR/apache_install_conf.log" \
|
||||
"Returning Apache config to a consistent state." \
|
||||
make "${make_args_array[@]}" apache_install_conf
|
||||
release_lock "$SERVER" "$LOCKFILE"
|
||||
fi
|
||||
done
|
||||
|
||||
if [ -z "$failed_tests" ]; then
|
||||
echo "All 'make' tests passed."
|
||||
exit 0
|
||||
fi
|
||||
|
||||
echo Failing tests: "$failed_tests"
|
||||
echo Re-run with devel/checkin.make "$failed_tests"
|
||||
exit 1
|
||||
Executable
+144
@@ -0,0 +1,144 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2011 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
# Author: sligocki@google.com (Shawn Ligocki)
|
||||
#
|
||||
# Helper functions for holding locks so that checkin tests from two clients
|
||||
# can be run simultaneously, and printing status on long-running commands.
|
||||
#
|
||||
# Sourced from checkin.make.
|
||||
|
||||
readonly APACHE_LOCKFILE="/tmp/pagespeed-apache.lock"
|
||||
|
||||
function acquire_lock {
|
||||
local server=$1
|
||||
local lockfile=$2
|
||||
|
||||
local lockfile_tmp="$lockfile.$$"
|
||||
local printed_msg=0
|
||||
|
||||
echo $$ > "$lockfile_tmp"
|
||||
# ln will fail if $lockfile exists, making this an atomic test and set.
|
||||
# Note that this is a hard link (ln), not a symlink (ln -s).
|
||||
while ! ln "$lockfile_tmp" "$lockfile" 2>/dev/null; do
|
||||
local lock_pid=$(cat "$lockfile" 2>/dev/null)
|
||||
if [ "$lock_pid" = "$$" ]; then
|
||||
## We already have the lock, apparently!
|
||||
break
|
||||
fi
|
||||
|
||||
if [ -n "$lock_pid" ] && ! ps "$lock_pid" >/dev/null; then
|
||||
echo "Removing stale lock. Process PID=$lock_pid, no longer exists."
|
||||
rm "$lockfile"
|
||||
else
|
||||
if [ "$printed_msg" = 0 ]; then
|
||||
echo -n "Waiting for PID $lock_pid to give up the $server lock."
|
||||
printed_msg=1
|
||||
else
|
||||
echo -n '.'
|
||||
fi
|
||||
sleep 1
|
||||
fi
|
||||
done
|
||||
|
||||
if [ "$printed_msg" != 0 ]; then
|
||||
echo
|
||||
fi
|
||||
rm -f "$lockfile_tmp"
|
||||
}
|
||||
|
||||
function release_lock {
|
||||
SERVER=$1
|
||||
LOCKFILE=$2
|
||||
|
||||
echo "Unlocking $SERVER."
|
||||
rm "$LOCKFILE"
|
||||
}
|
||||
exit_status=0
|
||||
|
||||
# Returns the unix system time in seconds.
|
||||
function now_sec() {
|
||||
date +%s
|
||||
}
|
||||
|
||||
start_time_sec=$(now_sec)
|
||||
|
||||
# Prints the elapsed time, in seconds, since the last time print_elapsed_time
|
||||
# was called. Any arguments to this function will be passed to through as the
|
||||
# first args to echo. The intent is you can put
|
||||
# print_elapsed_time -n
|
||||
# to allow callers to print more stuff on the same line.
|
||||
function print_elapsed_time() {
|
||||
current_time_sec=$(now_sec)
|
||||
if [ "$previous_time_sec" != 0 ]; then
|
||||
echo -n : "$((current_time_sec - start_time_sec))" sec
|
||||
fi
|
||||
}
|
||||
|
||||
# Determines whether the passed-in PID is alive.
|
||||
function is_process_alive() {
|
||||
ps "$1" > /dev/null
|
||||
}
|
||||
|
||||
# Runs command, redirecting stdout+stderr to a logfile, which is specified as
|
||||
# the first argument. The second argument is a string to put in the status
|
||||
# messsage. This might be all or part of the actual command, or something
|
||||
# descriptive. The rest of the arguments are the command.
|
||||
#
|
||||
# The full command will be added as the first line of the logfile.
|
||||
#
|
||||
# This function blocks until the command finishes, but it prints out status
|
||||
# lines at increasing intervals, with the max interval being 60 seconds. Once
|
||||
# the 60-second threshold is reached, each status line is emitted with a
|
||||
# newline. This is so that two long-running commands running in parallel
|
||||
# don't completely overwrite each other's status.
|
||||
#
|
||||
# The global variable 'exit_status' is set to 0 if the command succeeds, 1 if
|
||||
# it fails.
|
||||
function run_noisy_command_showing_log() {
|
||||
logfile="$1"
|
||||
shift
|
||||
description="$1"
|
||||
shift
|
||||
|
||||
start_time_sec=$(now_sec)
|
||||
previous_time_sec=$start_time_sec
|
||||
echo "$@" "&>" "$logfile" "..."
|
||||
("$@" ; echo exit_status=$?) &> "$logfile" &
|
||||
pid=$!
|
||||
print_interval_sec=60
|
||||
while is_process_alive $pid; do
|
||||
sleep 1
|
||||
current_sec=$(now_sec)
|
||||
interval_sec=$((current_sec - previous_time_sec))
|
||||
if [ $interval_sec -ge $print_interval_sec ]; then
|
||||
previous_time_sec=$current_sec
|
||||
lines_in_logfile=$(wc -l < "$logfile")
|
||||
echo " ... $description: $lines_in_logfile lines$(print_elapsed_time)"
|
||||
fi
|
||||
done
|
||||
if [ "$(tail -n 1 "$logfile")" = "exit_status=0" ]; then
|
||||
echo -n "PASS"
|
||||
local exit_status=0
|
||||
else
|
||||
echo -n "FAIL"
|
||||
local exit_status=1
|
||||
fi
|
||||
print_elapsed_time
|
||||
# shellcheck disable=SC2145
|
||||
echo " ($@ >& $logfile)"
|
||||
return $exit_status
|
||||
}
|
||||
Executable
+195
@@ -0,0 +1,195 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2011 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
# Author: morlovich@google.com (Maksim Orlovich)
|
||||
#
|
||||
# The usual mechanism used to develop mod_pagespeed and build binaries is based
|
||||
# on merging all dependencies into a single source tree. This script enables a
|
||||
# standard untar/configure/make flow that does not bundle widely available
|
||||
# external libraries. It generates the tarball including the configure (or
|
||||
# rather generate.sh) script.
|
||||
#
|
||||
# If --minimal is passed, it will cut out even more things. This was meant
|
||||
# for packaging properly Debian, which has a particularly extensive package
|
||||
# repository. At the moment this configuration requires further patching of
|
||||
# the .gyp[i] files and doesn't work out of the box. The pruning was also done
|
||||
# as of branch 33, so further tweaks might be required for this mode in
|
||||
# 34 or newer.
|
||||
#
|
||||
# This is expected to be run from build_release_tarball.sh, on the branch you
|
||||
# want a tarball for.
|
||||
|
||||
set -e # exit script if any command returns an error
|
||||
set -u # exit the script if any variable is uninitialized
|
||||
|
||||
function usage {
|
||||
echo "create_distro_tarball_debian.sh [ --minimal ] tarball"
|
||||
exit 1
|
||||
}
|
||||
|
||||
# This outputs a little wrapper around gyp that calls it with appropriate -D
|
||||
# flag
|
||||
function config {
|
||||
cat <<SCRIPT_END
|
||||
#!/bin/sh
|
||||
#
|
||||
# This script uses gyp to generate Makefiles for mod_pagespeed built against
|
||||
# the following system libraries:
|
||||
# apr, aprutil, apache httpd headers, icu, libjpeg_turbo, libpng, zlib.
|
||||
#
|
||||
# Besides the -D use_system_libs=1 below, you may need to set (via -D var=value)
|
||||
# paths for some of these libraries via these variables:
|
||||
# system_include_path_httpd, system_include_path_apr,
|
||||
# system_include_path_aprutil.
|
||||
#
|
||||
# for example, you might run
|
||||
# ./generate.sh -Dsystem_include_path_apr=/usr/include/apr-1 \\
|
||||
# -Dsystem_include_path_httpd=/usr/include/httpd
|
||||
# to specify APR and Apache include directories.
|
||||
#
|
||||
# Also, BUILDTYPE=Release can be passed to make (the default is Debug).
|
||||
echo "Generating src/Makefile"
|
||||
src/build/gyp_chromium -D use_system_libs=1 \$*
|
||||
SCRIPT_END
|
||||
}
|
||||
|
||||
if [ $# -lt 1 ]; then
|
||||
usage
|
||||
exit
|
||||
fi
|
||||
|
||||
MINIMAL=0
|
||||
if [ "$1" == "--minimal" ]; then
|
||||
MINIMAL=1
|
||||
shift 1
|
||||
fi
|
||||
|
||||
TARBALL="$1"
|
||||
if [ -z "$TARBALL" ]; then
|
||||
usage
|
||||
fi
|
||||
touch "$TARBALL"
|
||||
TARBALL="$(realpath $TARBALL)"
|
||||
MPS_CHECKOUT="$PWD"
|
||||
|
||||
git submodule update --init --recursive
|
||||
|
||||
# Pick up our version info, and wrap src inside a modpagespeed-version dir.
|
||||
source net/instaweb/public/VERSION
|
||||
VER_STRING="$MAJOR.$MINOR.$BUILD.$PATCH"
|
||||
TEMP_DIR="$(mktemp -d)"
|
||||
WRAPPER_DIR="modpagespeed-$VER_STRING"
|
||||
mkdir "$TEMP_DIR/$WRAPPER_DIR"
|
||||
DIR="$WRAPPER_DIR/src"
|
||||
ln -s "$MPS_CHECKOUT" "$TEMP_DIR/$DIR"
|
||||
|
||||
# Also create a little helper script that shows how to run gyp
|
||||
config > "$TEMP_DIR/$WRAPPER_DIR/generate.sh"
|
||||
chmod +x "$TEMP_DIR/$WRAPPER_DIR/generate.sh"
|
||||
|
||||
# Normally, the build system runs build/lastchange.sh to figure out what
|
||||
# to put into the last portion of the version number. We are, however, going to
|
||||
# be getting rid of the .git dirs, so that will not work (nor would it without
|
||||
# network access). Luckily, we can provide the number via LASTCHANGE.in,
|
||||
# so we just compute it now, and save it there.
|
||||
./build/lastchange.sh "$MPS_CHECKOUT" > LASTCHANGE.in
|
||||
|
||||
# Things that depends on minimal or not.
|
||||
if [ $MINIMAL -eq 0 ]; then
|
||||
GTEST=$DIR/testing
|
||||
GFLAGS=$DIR/third_party/gflags
|
||||
GIFLIB=$DIR/third_party/giflib
|
||||
ICU="$DIR/third_party/icu/icu.gyp \
|
||||
$DIR/third_party/icu/source/common/unicode/"
|
||||
JSONCPP=$DIR/third_party/jsoncpp
|
||||
LIBWEBP=$DIR/third_party/libwebp
|
||||
PROTOBUF=$DIR/third_party/protobuf
|
||||
RE2=$DIR/third_party/re2
|
||||
else
|
||||
GTEST="$DIR/testing \
|
||||
--exclude $DIR/testing/gmock \
|
||||
--exclude $DIR/testing/gtest"
|
||||
GFLAGS=$DIR/third_party/gflags/gflags.gyp
|
||||
GIFLIB=$DIR/third_party/giflib/giflib.gyp
|
||||
ICU=$DIR/third_party/icu/icu.gyp
|
||||
JSONCPP=$DIR/third_party/jsoncpp/jsoncpp.gyp
|
||||
LIBWEBP="$DIR/third_party/libwebp/COPYING \
|
||||
$DIR/third_party/libwebp/examples/gif2webp_util.*"
|
||||
PROTOBUF="$DIR/third_party/protobuf/*.gyp \
|
||||
$DIR/third_party/protobuf/*.gypi"
|
||||
RE2=$DIR/third_party/re2/re2.gyp
|
||||
fi
|
||||
|
||||
# It's tarball time!
|
||||
# Note that this is highly-version specific, and requires tweaks for every
|
||||
# release as its dependencies change. Always run the version of this
|
||||
# script that's on the branch you're making a tarball for.
|
||||
cd "$TEMP_DIR"
|
||||
tar cj --dereference --exclude='.git' --exclude='.svn' --exclude='.hg' -f $TARBALL \
|
||||
--exclude='*.mk' --exclude='*.pyc' \
|
||||
--exclude=$DIR/net/instaweb/genfiles/*/*.cc \
|
||||
$WRAPPER_DIR/generate.sh \
|
||||
$DIR/LASTCHANGE.in \
|
||||
$DIR/base \
|
||||
$DIR/build \
|
||||
--exclude $DIR/build/android/arm-linux-androideabi-gold \
|
||||
$DIR/install \
|
||||
$DIR/net/instaweb \
|
||||
$DIR/pagespeed \
|
||||
$DIR/strings \
|
||||
$GTEST \
|
||||
$DIR/third_party/apr/apr.gyp \
|
||||
$DIR/third_party/aprutil/aprutil.gyp \
|
||||
$DIR/third_party/aprutil/apr_memcache2.h \
|
||||
$DIR/third_party/aprutil/apr_memcache2.c \
|
||||
$DIR/third_party/httpd/httpd.gyp \
|
||||
$DIR/third_party/httpd24/httpd24.gyp \
|
||||
$DIR/third_party/base64 \
|
||||
$DIR/third_party/brotli \
|
||||
$DIR/third_party/chromium/src/base \
|
||||
--exclude src/third_party/chromium/src/base/third_party/xdg_mime \
|
||||
--exclude src/third_party/chromium/src/base/third_party/xdg_user_dirs \
|
||||
$DIR/third_party/chromium/src/build \
|
||||
--exclude $DIR/third_party/chromium/src/build/android \
|
||||
$DIR/third_party/chromium/src/googleurl \
|
||||
$DIR/third_party/chromium/src/net/tools \
|
||||
$DIR/third_party/closure/ \
|
||||
$DIR/third_party/closure_library/ \
|
||||
$DIR/third_party/css_parser \
|
||||
$DIR/third_party/domain_registry_provider \
|
||||
$GFLAGS \
|
||||
$GIFLIB \
|
||||
$DIR/third_party/google-sparsehash \
|
||||
$DIR/third_party/grpc \
|
||||
$DIR/third_party/hiredis \
|
||||
$ICU \
|
||||
$JSONCPP \
|
||||
$DIR/third_party/libjpeg_turbo/libjpeg_turbo.gyp \
|
||||
$DIR/third_party/libpng/libpng.gyp \
|
||||
$LIBWEBP \
|
||||
$DIR/third_party/modp_b64 \
|
||||
$DIR/third_party/optipng \
|
||||
$PROTOBUF \
|
||||
$DIR/third_party/rdestl \
|
||||
$RE2 \
|
||||
$DIR/third_party/redis-crc \
|
||||
$DIR/third_party/serf \
|
||||
$DIR/third_party/zlib/zlib.gyp \
|
||||
$DIR/tools/gyp \
|
||||
$DIR/url
|
||||
|
||||
cd "$MPS_CHECKOUT"
|
||||
rm -r "$TEMP_DIR"
|
||||
Executable
+60
@@ -0,0 +1,60 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2003 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
# Runs a file in $1 through a giant sed script, transforming normal
|
||||
# C++ comments to Doxygen comments. The resultant file is placed in
|
||||
# $2/$1, so $2 must be a subdirectory.
|
||||
#
|
||||
# Usage: scripts/doxify.sh filename destination_directory
|
||||
|
||||
set -u # exit the script if any variable is uninitialized
|
||||
set -e # exit script if any command returns an error
|
||||
|
||||
filename=$1
|
||||
destination_directory=$2
|
||||
outfile=$destination_directory/$filename
|
||||
|
||||
mkdir -p "$(dirname $outfile)"
|
||||
|
||||
sed -r 's~/\*([^\*])~/\*\*\1~; # /* -> /** \
|
||||
s~///*~///~; # // -> /// \
|
||||
s~;[ ]*/\*\*([^<*]*)~; /\*\*<\1~; # /** -> /**< on right after code \
|
||||
s~;[ ]*///*([^<])~; ///<\1~; # /// -> ///< on right after code \
|
||||
s~,([ ]*)///*([^<])~,\1///<\2~; # /// -> ///< on right after enum \
|
||||
s~([[:alnum:]][ ]*)///*([^<])~\1///<\2~; # /// -> ///< on right after enum \
|
||||
s~DISALLOW_COPY_AND_ASSIGN\(.*\)\;~~; # /// -> ///< on right after code \
|
||||
s~(///) *---+([^-].+[^-]) *---+~\1\2~; # /// ---- Bla ---- -> /// Bla
|
||||
s~(///) *===+([^=].+[^=]) *===+~\1\2~; # /// ==== Bla ==== -> /// Bla
|
||||
s~(///) *\*\*\*+([^\*].+[^\*]) *\*\*\*+~\1\2~; # /// **** Bla **** -> /// Bla
|
||||
s~(///) *----*( *)~\1\2~; # /// -------- -> ///
|
||||
s~(///) *====*( *)~\1\2~; # /// ======== -> ///
|
||||
s~(///) *\*\*\*\**( *)~\1\2~; # /// ******** -> ///
|
||||
s~(///) *\* \* \*( \*)* *~\1~; # /// * * * * * -> ///
|
||||
s~(([^A-Z_])((TODO|FIXME)[^A-Z_].*))~\2 @todo \3~; # TODO* -> @todo TODO* \
|
||||
s~(([^A-Z_])((BUG)[^A-Z_].*))~\2 @bug \3~; # BUG* -> @bug BUG* \
|
||||
s~([ \t]*)ABSTRACT([ \t]*\;)~\1\=0\2~; # void f() ABSTRACT; -> void f() =0; \
|
||||
s~DECLARE_string(.*)~DECLARE_STRING\1~; # /// -> ///< on right after code \
|
||||
s~DECLARE_bool(.*)~DECLARE_BOOL\1~; # /// -> ///< on right after code \
|
||||
s~DECLARE_int32(.*)~DECLARE_INT32\1~; # /// -> ///< on right after code \
|
||||
s~DECLARE_uint32(.*)~DECLARE_UINT32\1~; # /// -> ///< on right after code \
|
||||
s~DECLARE_int64(.*)~DECLARE_INT64\1~; # /// -> ///< on right after code \
|
||||
s~DECLARE_uint64(.*)~DECLARE_UINT64\1~; # /// -> ///< on right after code \
|
||||
s~/// *(Copyright(.*))~// \1~; # clutter \
|
||||
s~/// *(All [rR]ights [rR]eserved(.*))~// \1~; # clutter \
|
||||
s~/// *(Date: (.*))~/// @file~; # clutter \
|
||||
s~/// *Author:(.*)~/// @file~; # /// Author -> /// @file \
|
||||
s~/// *Author(.*)~/// @file~; # /// Author -> /// @file ' \
|
||||
< $filename > $outfile
|
||||
Executable
+85
@@ -0,0 +1,85 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2010 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
# Processes the open-source header files using Doxygen. Each header
|
||||
# must be preprocessed using doxify.sh to convert normal C++ comments
|
||||
# into Doxygen Usage.
|
||||
#
|
||||
# comments: devel/doxify_tree.sh output_tarball
|
||||
|
||||
set -e # exit script if any command returns an error
|
||||
set -u # exit the script if any variable is uninitialized
|
||||
|
||||
this_dir=$(dirname "${BASH_SOURCE[0]}")
|
||||
cd "$this_dir/.."
|
||||
src="$PWD"
|
||||
cfg="$src/devel/doxygen.cfg"
|
||||
|
||||
if [ $# != 1 ]; then
|
||||
echo Usage: $0 output_tarball
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if ! which doxygen > /dev/null; then
|
||||
echo "doxygen is not installed; run"
|
||||
echo " sudo apt-get install doxygen"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# This generates a documentation tarball, suitable for copying to
|
||||
# modpagespeed.com. This should be in $1
|
||||
tarball="$(readlink -f $1)"
|
||||
|
||||
source "$src/net/instaweb/public/VERSION"
|
||||
PSOL_VERSION="$MAJOR.$MINOR.$BUILD.$PATCH"
|
||||
|
||||
WORKDIR=$(mktemp -d)
|
||||
trap "rm -r $WORKDIR" EXIT
|
||||
|
||||
OUTPUT_DIRECTORY="$WORKDIR/doxygen_out"
|
||||
mkdir "$OUTPUT_DIRECTORY"
|
||||
|
||||
hacked_copies="$WORKDIR/hacked_copies"
|
||||
mkdir "$hacked_copies"
|
||||
|
||||
echo Preprocessing header files to turn normal C++ comments into Doxygen-style
|
||||
echo comments....
|
||||
find net/ pagespeed/ -name "*.h" -exec "$src/devel/doxify.sh" {} \
|
||||
"$hacked_copies" \;
|
||||
|
||||
# These variables are referenced in doxygen.cfg, so export them before running
|
||||
# doxygen.
|
||||
export PSOL_VERSION
|
||||
export OUTPUT_DIRECTORY
|
||||
|
||||
log_file=$OUTPUT_DIRECTORY/doxygen.log
|
||||
cd $hacked_copies
|
||||
doxygen $cfg 2> $log_file
|
||||
|
||||
# Doxygen produces a large number of warnings about undocumented classes. At
|
||||
# some point we should fix all these but this is going to take a while as there
|
||||
# are 12431 as of 2016-11-18.
|
||||
#
|
||||
# These will reference files that we have hacked in this script, and using Emacs
|
||||
# to navigate to these errors will get you to files you should never edit.
|
||||
# Strip off the prefix so we'll print files with their source of truth.
|
||||
grep hacked_copies $log_file | sed -e s@$hacked_copies/@@g
|
||||
|
||||
# TODO(jmarantz): walk through files in $OUTPUT_DIRECTORY/html and see whether
|
||||
# there are changes to the corresponding files in the documentation.
|
||||
cd $OUTPUT_DIRECTORY
|
||||
tar czf $tarball .
|
||||
ls -l $tarball
|
||||
+1552
File diff suppressed because it is too large
Load Diff
Executable
+8
@@ -0,0 +1,8 @@
|
||||
#!/bin/bash
|
||||
|
||||
"$@"
|
||||
if [ $? -eq 0 ]; then
|
||||
echo expected $1 to fail
|
||||
exit 1
|
||||
fi
|
||||
exit 0
|
||||
Executable
+168
@@ -0,0 +1,168 @@
|
||||
#!/usr/bin/python
|
||||
#
|
||||
# Copyright 2010 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
"""Fetches a set of URLs via a proxy, keeping statistics.
|
||||
|
||||
This script attempts to fetch all URLs in the list given on
|
||||
the command-line via a specified proxy. It differs from the
|
||||
widely available tools in that:
|
||||
- The proxy connection is kept-alive to try to maximize throughput.
|
||||
- Statuses and completion times for each URL are output to stdout to
|
||||
help analyze the results.
|
||||
|
||||
With the --js option the output is a JavaScript object literal with fields named
|
||||
for URLs with http:// replaced with whatever is passed as test_cat,
|
||||
followed by a dash.
|
||||
|
||||
"""
|
||||
|
||||
__author__ = "morlovich@google.com (Maksim Orlovich)"
|
||||
|
||||
import getopt
|
||||
import httplib
|
||||
import socket
|
||||
import sys
|
||||
import time
|
||||
import urlparse
|
||||
|
||||
|
||||
def OpenProxy(config):
|
||||
if config.ssl_mode:
|
||||
new_proxy = httplib.HTTPSConnection(config.proxy_host, config.proxy_port)
|
||||
else:
|
||||
new_proxy = httplib.HTTPConnection(config.proxy_host, config.proxy_port)
|
||||
new_proxy.connect()
|
||||
return new_proxy
|
||||
|
||||
|
||||
def ReopenProxy(config, old_proxy):
|
||||
old_proxy.close()
|
||||
return OpenProxy(config)
|
||||
|
||||
|
||||
def TestName(config, test_url):
|
||||
return test_url.replace("http://", config.test_cat + "-")
|
||||
|
||||
|
||||
def FormatResult(config, time_str, status, test_url):
|
||||
if config.js_mode:
|
||||
return '"%s": %s,' % (TestName(config, test_url), time_str)
|
||||
else:
|
||||
return "%s %s %s" % (time_str, status, test_url)
|
||||
|
||||
|
||||
class Configuration(object):
|
||||
"""packages up execution settings."""
|
||||
|
||||
def __init__(self):
|
||||
"""Initializes settings from command-line arguments."""
|
||||
try:
|
||||
opts, _ = getopt.getopt(sys.argv[1:], "",
|
||||
["ssl", "js=", "proxy_host=", "proxy_port=",
|
||||
"urls_file=", "user_agent="])
|
||||
except getopt.GetoptError as err:
|
||||
print str(err)
|
||||
print ("Usage: devel/fetch_all.py [--ssl] [--js test_cat] "
|
||||
"[--proxy_host host] [--proxy_port port] [--urls_file file] "
|
||||
"[--user_agent user_agent]")
|
||||
sys.exit(2)
|
||||
|
||||
self.ssl_mode = False
|
||||
self.js_mode = False
|
||||
self.has_user_agent = False
|
||||
|
||||
for name, value in opts:
|
||||
if name == "--ssl":
|
||||
self.ssl_mode = True
|
||||
elif name == "--js":
|
||||
self.js_mode = True
|
||||
self.test_cat = value
|
||||
elif name == "--proxy_host":
|
||||
self.proxy_host = value
|
||||
elif name == "--proxy_port":
|
||||
self.proxy_port = int(value)
|
||||
elif name == "--urls_file":
|
||||
self.urls_file = value
|
||||
elif name == "--user_agent":
|
||||
self.has_user_agent = True
|
||||
self.user_agent = value
|
||||
|
||||
|
||||
def main():
|
||||
conf = Configuration()
|
||||
|
||||
# Open a persistent connection to the proxy
|
||||
proxy = OpenProxy(conf)
|
||||
|
||||
if conf.js_mode:
|
||||
print "{"
|
||||
|
||||
f = open(conf.urls_file, "rt")
|
||||
for url in f:
|
||||
try:
|
||||
# Fetch url
|
||||
status = 301
|
||||
followed = 0
|
||||
while followed < 5:
|
||||
url = url.strip()
|
||||
if conf.ssl_mode:
|
||||
url = url.replace("http://", "https://", 1)
|
||||
start = time.time()
|
||||
|
||||
headers = {"Accept-Encoding": "gzip"}
|
||||
if conf.has_user_agent:
|
||||
headers["User-Agent"] = conf.user_agent
|
||||
if "Chrome/" in conf.user_agent:
|
||||
headers["Accept"] = "image/webp"
|
||||
proxy.request("GET", url, None, headers)
|
||||
|
||||
response = proxy.getresponse()
|
||||
response.read()
|
||||
stop = time.time()
|
||||
status = response.status
|
||||
|
||||
# Honor server's close request
|
||||
connect_ctl = response.getheader("connection", default="")
|
||||
if connect_ctl.lower().find("close") != -1:
|
||||
proxy = ReopenProxy(conf, proxy)
|
||||
|
||||
# Report.
|
||||
print FormatResult(conf, str((stop - start)*1000),
|
||||
str(status), url)
|
||||
|
||||
# Handle redirections
|
||||
if 301 <= status <= 303 or status == 307:
|
||||
url = urlparse.urljoin(url,
|
||||
response.getheader("Location", default=""))
|
||||
followed += 1
|
||||
else:
|
||||
break
|
||||
except httplib.BadStatusLine:
|
||||
print FormatResult(conf, "0", "BadStatusLine", url)
|
||||
proxy = ReopenProxy(conf, proxy)
|
||||
except httplib.IncompleteRead:
|
||||
print FormatResult(conf, "0", "IncompleteRead", url)
|
||||
proxy = ReopenProxy(conf, proxy)
|
||||
except socket.error:
|
||||
print FormatResult(conf, "0", "SocketError", url)
|
||||
proxy = ReopenProxy(conf, proxy)
|
||||
|
||||
if conf.js_mode:
|
||||
print "}"
|
||||
|
||||
f.close()
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
Executable
+266
@@ -0,0 +1,266 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2011 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
# A helper for running gcov on all of the project sources.
|
||||
# Usage:
|
||||
# gcov-all.sh (--prepare | --summarize) path
|
||||
#
|
||||
# where path is the same location where one runs make
|
||||
#
|
||||
# There are two modes:
|
||||
# --prepare cleans up all the .gcda files. This should be done
|
||||
# before running the test, as we need an accurate set of these
|
||||
# to know which object files to include in the executable.
|
||||
# It also effectively zeroes all the measurements, preventing
|
||||
# different runs from getting added together.
|
||||
#
|
||||
# --summarize goes through the produced files, runs gcov on
|
||||
# them, producing the gcov-summary.html and the gcov/ directory
|
||||
# with individual dumps
|
||||
#
|
||||
# Glossary:
|
||||
# .gcno file: produced by gcc during compilation, along with the
|
||||
# corresponding .o file
|
||||
# .gcda file: produced when an instrumented application is run
|
||||
# (or .so is loaded), and then at its exit. Contains
|
||||
# the actual measurements.
|
||||
#
|
||||
# To invoke gcov, we need to pass it in a list of all the source
|
||||
# files we want coverage information for, as well as the directory
|
||||
# to look into for the corresponding .gcno/.gcda files. The
|
||||
# summarize mode collects these based on the .gcda files that exist.
|
||||
#
|
||||
# TODO(morlovich): evaluate lcov as an option? Its output looks nice.
|
||||
|
||||
function summarize {
|
||||
WORKDIR=`mktemp -d`
|
||||
SRCDIR=`pwd`
|
||||
OUTNAME=gcov-summary.html
|
||||
|
||||
echo "Collecting all object and profile data into:" $WORKDIR
|
||||
|
||||
# Here, we look for the .gcda files, and the .o and .gcno that go with them.
|
||||
# This is because they get generated for any object files that gets linked in,
|
||||
# as soon as the executable/module are initialized, giving us an accurate
|
||||
# picture of what should be checked
|
||||
|
||||
GCDAS=`find ./out/Debug_Coverage -name '*.gcda'`
|
||||
DATA=
|
||||
for F in $GCDAS
|
||||
do
|
||||
BASE=${F%.gcda}
|
||||
GCNO=$BASE.gcno
|
||||
O=$BASE.o
|
||||
if [ ! -f $GCNO ]; then
|
||||
echo "WARNING: can't find " $GCNO
|
||||
continue
|
||||
fi
|
||||
|
||||
if [ ! -f $O ]; then
|
||||
echo "WARNING: can't find " $O
|
||||
continue
|
||||
fi
|
||||
|
||||
DATA+=" $F $GCNO $O"
|
||||
done
|
||||
|
||||
cp $DATA $WORKDIR/
|
||||
|
||||
echo "Generating gcov summary into file://"$PWD/$OUTNAME
|
||||
|
||||
# Collect relevant sources. For each one, we check if we have the
|
||||
# gcda (which means we have gcno, too). We want this for two reasons:
|
||||
#
|
||||
# 1) We only want coverage for a file if the gcda is there
|
||||
# 2) gcov has a bug that screws up output if some files' .gcno
|
||||
# does not exist (see http://gcc.gnu.org/bugzilla/show_bug.cgi?id=35568)
|
||||
#
|
||||
# TODO(morlovich): worry about duplicate names!
|
||||
SOURCES=`find -L $SRCDIR/net $SRCDIR/pagespeed -name '*.cc' -or -name '*.c'`
|
||||
|
||||
FILTERED_SOURCES=
|
||||
for F in $SOURCES
|
||||
do
|
||||
GCDA=`basename $F .c`
|
||||
GCDA=$WORKDIR/`basename $GCDA .cc`.gcda
|
||||
if [ -f $GCDA ]; then
|
||||
if [ $F == ${F/.svn/marker/} ]; then
|
||||
FILTERED_SOURCES="$FILTERED_SOURCES $GCDA"
|
||||
fi
|
||||
fi
|
||||
done
|
||||
htmlDriver > $OUTNAME
|
||||
echo "<pre id='data' style='display:none'>" >> $OUTNAME
|
||||
gcov -o $WORKDIR $FILTERED_SOURCES >> $OUTNAME
|
||||
echo "</pre>" >> $OUTNAME
|
||||
|
||||
echo "Moving all the .gcov files to gcov subdir (after wiping it)"
|
||||
rm -rf $SRCDIR/gcov
|
||||
mkdir $SRCDIR/gcov
|
||||
mv *.gcov $SRCDIR/gcov
|
||||
|
||||
echo "Cleaning up..."
|
||||
rm -r $WORKDIR
|
||||
}
|
||||
|
||||
# This outputs the html driver that visualizes the results
|
||||
function htmlDriver {
|
||||
cat <<TEMPLATE_END
|
||||
<!DOCTYPE html>
|
||||
<head>
|
||||
<script>
|
||||
// Computes a color for given goodness percentage. (Using CSS3 hsl syntax)
|
||||
function percentColor(percent) {
|
||||
var hue = (percent / 100 * 120).toFixed(0);
|
||||
return 'hsl(' + hue + ', 100%, 50%)';
|
||||
}
|
||||
|
||||
// Adds a row with given DOM for the file info and given coverage
|
||||
// percentage to the provided table section, giving it the appropriate color
|
||||
function addResultRow(tsection, fileInfo, percent) {
|
||||
var row = tsection.insertRow(-1);
|
||||
row.style.backgroundColor = percentColor(percent);
|
||||
|
||||
var fileNameCell = row.insertCell(-1);
|
||||
fileNameCell.appendChild(fileInfo);
|
||||
|
||||
var percentCell = row.insertCell(-1);
|
||||
percentCell.align = 'right';
|
||||
percentCell.appendChild(document.createTextNode(percent.toFixed(2) + '%'));
|
||||
}
|
||||
|
||||
// Adds a result for given filename and coverage percentage to the first body
|
||||
// of the table with id 'outTable'
|
||||
function addFileResultRow(fileName, percent) {
|
||||
var table = document.getElementById('outTable');
|
||||
var tbody = table.tBodies[0];
|
||||
|
||||
// We want a link to the .gcov file here
|
||||
var a = document.createElement('a');
|
||||
a.appendChild(document.createTextNode(fileName));
|
||||
|
||||
var fragments = fileName.split('/');
|
||||
a.setAttribute('href', 'gcov/' + fragments[fragments.length - 1] + '.gcov');
|
||||
|
||||
addResultRow(tbody, a, percent);
|
||||
}
|
||||
|
||||
function addSummaryResultRow(summary, percent) {
|
||||
var table = document.getElementById('outTable');
|
||||
var tfoot = table.tFoot;
|
||||
|
||||
addResultRow(tfoot, document.createTextNode(summary), percent);
|
||||
}
|
||||
|
||||
function prettifySummary() {
|
||||
// Get the raw data from the <pre id='data'>
|
||||
var preNode = document.getElementById('data');
|
||||
var txt = (preNode.textContent ? preNode.textContent : preNode.innerText);
|
||||
var allLines = txt.split('\n');
|
||||
|
||||
var currentFile;
|
||||
|
||||
// Collect file names, percentages, and lines
|
||||
var allFiles = []; // array of name, coverage %, lines pairs
|
||||
for (var i = 0; i < allLines.length; ++i) {
|
||||
var line = allLines[i];
|
||||
var fileInfo = /File '(.*)'/.exec(line);
|
||||
if (fileInfo) {
|
||||
currentFile = fileInfo[1];
|
||||
// get rid of ./ if needed.
|
||||
if (currentFile.substring(0, 2) == './') {
|
||||
currentFile = currentFile.substring(2);
|
||||
}
|
||||
}
|
||||
|
||||
var linesInfo = /Lines executed:(.*)% of (\d+)/.exec(line);
|
||||
if (linesInfo) {
|
||||
allFiles.push([currentFile, Number(linesInfo[1]), Number(linesInfo[2])]);
|
||||
}
|
||||
|
||||
if (/No executable lines/.exec(line)) {
|
||||
allFiles.push([currentFile, 0, 0]);
|
||||
}
|
||||
}
|
||||
|
||||
// Sort by filename
|
||||
allFiles.sort(function(a, b) {
|
||||
if (a[0] < b[0]) {
|
||||
return -1;
|
||||
} else if (a[0] == b[0]) {
|
||||
return 0;
|
||||
} else {
|
||||
return 1;
|
||||
}
|
||||
});
|
||||
|
||||
// Append all results we want to table, coloring by coverage; and also compute
|
||||
// an overall number (which may include a few things we don't care about)
|
||||
var totalLines = 0;
|
||||
var totalCovered = 0;
|
||||
for (var i = 0; i < allFiles.length; ++i) {
|
||||
var fileName = allFiles[i][0];
|
||||
var percent = allFiles[i][1];
|
||||
var lines = allFiles[i][2];
|
||||
|
||||
// Skip paths -- we don't need coverage information for system headers
|
||||
if (fileName.charAt(0) == '/') {
|
||||
continue;
|
||||
}
|
||||
|
||||
totalLines += lines;
|
||||
totalCovered += Math.round(lines * percent / 100);
|
||||
|
||||
addFileResultRow(fileName, percent);
|
||||
}
|
||||
|
||||
addSummaryResultRow('Total (' + totalCovered + '/' + totalLines +')',
|
||||
totalCovered / totalLines * 100);
|
||||
}
|
||||
</script>
|
||||
</head>
|
||||
<body onload="prettifySummary()">
|
||||
<table id="outTable">
|
||||
<thead>
|
||||
<tr><th>File name</th><th>Coverage percentage</th></tr>
|
||||
</thead>
|
||||
<tbody></tbody>
|
||||
<tfoot style="font-weight:bold; "></tfoot>
|
||||
</table>
|
||||
TEMPLATE_END
|
||||
}
|
||||
|
||||
function usage {
|
||||
echo "Usage:" $0 "(--prepare | --summarize) path"
|
||||
}
|
||||
|
||||
if [ -z $2 ]; then
|
||||
usage
|
||||
exit
|
||||
fi
|
||||
|
||||
cd $2
|
||||
|
||||
case $1 in
|
||||
--prepare)
|
||||
echo "Removing old .gcda files"
|
||||
find $2/out/Debug_Coverage -name '*.gcda' -delete;;
|
||||
--summarize)
|
||||
summarize;;
|
||||
*)
|
||||
usage;;
|
||||
esac
|
||||
|
||||
@@ -0,0 +1,33 @@
|
||||
ModPagespeedFileCachePath "#HOME/apache2/pagespeed_cache/"
|
||||
AddOutputFilterByType MOD_PAGESPEED_OUTPUT_FILTER text/html
|
||||
|
||||
<VirtualHost localhost:8080>
|
||||
ModPagespeed on
|
||||
|
||||
<Location /pagespeed_admin>
|
||||
Order allow,deny
|
||||
Allow from localhost
|
||||
Allow from 127.0.0.1
|
||||
SetHandler pagespeed_admin
|
||||
</Location>
|
||||
<Location /pagespeed_global_admin>
|
||||
Order allow,deny
|
||||
Allow from localhost
|
||||
Allow from 127.0.0.1
|
||||
SetHandler pagespeed_global_admin
|
||||
</Location>
|
||||
|
||||
KeepAlive On
|
||||
KeepAliveTimeout 60
|
||||
|
||||
<Directory "#HOME/apache2/htdocs/" >
|
||||
# This is enabled to make sure we don't crash mod_negotiation.
|
||||
Options +MultiViews
|
||||
</Directory>
|
||||
|
||||
ModPagespeedRewriteLevel AllFilters
|
||||
ModPagespeedSlurpDirectory #SLURP_DIR
|
||||
ModPagespeedSlurpReadOnly off
|
||||
ModPagespeedRewriteDeadlinePerFlushMs -1
|
||||
CustomLog "#LOG_PATH" %r
|
||||
</VirtualHost>
|
||||
+67
@@ -0,0 +1,67 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2017 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
# This script collects slurps and URLs (post-optimization, if possible), of
|
||||
# some websites with the help of phantomjs.
|
||||
|
||||
function usage {
|
||||
echo "Usage: loadtest_collect/loadtest_collect_corpus.sh pages.txt out.tar.bz2"
|
||||
echo "Where pages.txt has a URL (including http://) per line"
|
||||
}
|
||||
|
||||
set -u # exit the script if any variable is uninitialized
|
||||
set -e
|
||||
|
||||
if [ $# -ne 2 ]; then
|
||||
usage
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ -d devel ]; then
|
||||
cd devel
|
||||
fi
|
||||
if [ ! -d loadtest_collect ]; then
|
||||
echo Run this script from the top or devel/ directories
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ ! $(which phantomjs) ]; then
|
||||
echo "phantomjs not found, trying to install it with apt-get"
|
||||
sudo apt-get install phantomjs
|
||||
fi
|
||||
|
||||
SLURP_TOP_DIR=$(mktemp -d)
|
||||
SLURP_DIR=$SLURP_TOP_DIR/slurp
|
||||
mkdir $SLURP_DIR
|
||||
LOG_PATH=$SLURP_TOP_DIR/log.txt
|
||||
URLS_PATH=$SLURP_TOP_DIR/corpus_all_urls.txt
|
||||
|
||||
make clean_slate_for_tests
|
||||
make apache_debug_stop
|
||||
|
||||
sed -e "s^#HOME^$HOME^" -e "s^#SLURP_DIR^$SLURP_DIR^" \
|
||||
-e "s^#LOG_PATH^$LOG_PATH^" \
|
||||
< loadtest_collect/loadtest_collect.conf > ~/apache2/conf/pagespeed.conf
|
||||
make -j8 apache_debug_restart
|
||||
|
||||
for site in $(cat $1); do
|
||||
echo $site
|
||||
phantomjs --proxy=127.0.0.1:8080 loadtest_collect/script.js $site
|
||||
done
|
||||
cat $LOG_PATH | grep ^GET | cut -d ' ' -f 2 > $URLS_PATH
|
||||
cd $SLURP_TOP_DIR
|
||||
tar cvjf $2 .
|
||||
|
||||
@@ -0,0 +1,12 @@
|
||||
// This is basically just the stripped down http://phantomjs.org/quick-start.html
|
||||
// example.
|
||||
var page = require('webpage').create();
|
||||
var system = require('system');
|
||||
if (system.args.length === 1) {
|
||||
console.log('Usage: script.js <some URL>');
|
||||
phantom.exit();
|
||||
}
|
||||
|
||||
page.open(system.args[1], function(status) {
|
||||
phantom.exit();
|
||||
});
|
||||
Executable
+78
@@ -0,0 +1,78 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2012 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
# Author: morlovich@google.com (Maksim Orlovich)
|
||||
#
|
||||
# Helpers for doing experiments with lots of vhosts.
|
||||
#
|
||||
# usage:
|
||||
# scripts/lots_of_vhosts.sh --config | --traffic
|
||||
#
|
||||
# You can also set envvar NUM_VHOSTS to configure how many hosts to use.
|
||||
|
||||
set -e # exit script if any command returns an error
|
||||
set -u # exit the script if any variable is uninitialized
|
||||
|
||||
NUM_VHOSTS=${NUM_VHOSTS:-10000}
|
||||
|
||||
function usage {
|
||||
cat <<EOF >&2
|
||||
Usage:
|
||||
scripts/lots_of_vhosts.sh --config | --traffic
|
||||
|
||||
--config generates a suffix for pagespeed.conf
|
||||
--traffic generates a list of URLs for trace_stress_test.sh
|
||||
You can also set environment variable NUM_VHOSTS to control the number of
|
||||
virtual hosts produced.
|
||||
|
||||
See also https://github.com/pagespeed/mod_pagespeed/wiki/Memory-Profiling
|
||||
EOF
|
||||
}
|
||||
|
||||
function config {
|
||||
echo "NameVirtualHost *:8080"
|
||||
for i in $(seq 0 $NUM_VHOSTS); do
|
||||
echo "<VirtualHost *:8080>"
|
||||
echo " DocumentRoot $HOME/apache2/htdocs/"
|
||||
echo " ServerName vhost"$i".example.com"
|
||||
echo " ModPagespeed on"
|
||||
echo " ModPagespeedFileCachePath \"/tmp/vhost\""
|
||||
echo " ModPagespeedBlockingRewriteKey \"foo"$i"\""
|
||||
echo "</VirtualHost>"
|
||||
done
|
||||
}
|
||||
|
||||
function traffic {
|
||||
for i in $(seq 0 $NUM_VHOSTS); do
|
||||
echo "http://vhost"$i".example.com/mod_pagespeed_example/"
|
||||
done
|
||||
}
|
||||
|
||||
if [ $# -ne 1 ]; then
|
||||
usage
|
||||
exit 1
|
||||
fi
|
||||
|
||||
case $1 in
|
||||
--config)
|
||||
config;;
|
||||
--traffic)
|
||||
traffic;;
|
||||
*)
|
||||
usage
|
||||
exit 1
|
||||
;;
|
||||
esac
|
||||
Executable
+64
@@ -0,0 +1,64 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2012 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
# This script is intended to be run from devel/mps_load_test.sh, although it can
|
||||
# be run directly as well.
|
||||
#
|
||||
# Usage: devel/mps_generate_load.sh \
|
||||
# [--ipro_preserve] [--ssl] [--user_agent user_agent_string]
|
||||
|
||||
set -e # exit script if any command returns an error
|
||||
set -u # exit the script if any variable is uninitialized
|
||||
|
||||
devel_directory="$(dirname $0)"
|
||||
|
||||
corpus_suffix=
|
||||
IPRO_PRESERVE=0
|
||||
if [[ $# -ge 1 && "$1" = "--ipro_preserve" ]]; then
|
||||
shift
|
||||
corpus_suffix=.ipro_preserve
|
||||
IPRO_PRESERVE=1
|
||||
fi
|
||||
|
||||
extra_flags=
|
||||
if [[ $# -ge 1 && "$1" = "--ssl" ]]; then
|
||||
shift
|
||||
extra_flags=$1
|
||||
fi
|
||||
|
||||
user_agent=
|
||||
if [[ $# -ge 1 && "$1" = "--user_agent" ]]; then
|
||||
user_agent=$2
|
||||
shift 2
|
||||
fi
|
||||
|
||||
corpus_file=/tmp/corpus_all_urls.txt.$USER$corpus_suffix
|
||||
|
||||
# Grab the file from the server host if needed.
|
||||
if [ ! -e $corpus_file ]; then
|
||||
work_file=$(mktemp)
|
||||
src="$HOME/pagespeed-loadtest-corpus/corpus_all_urls.txt"
|
||||
cp $src $work_file
|
||||
if [ $IPRO_PRESERVE = 1 ]; then
|
||||
cat $work_file | fgrep -v .pagespeed. > $corpus_file
|
||||
rm $work_file
|
||||
else
|
||||
mv $work_file $corpus_file
|
||||
fi
|
||||
fi
|
||||
|
||||
PROXY_HOST=127.0.0.1 FLAGS=$extra_flags USER_AGENT=$user_agent PAR=50 RUNS=3 \
|
||||
$devel_directory/trace_stress_test.sh $corpus_file
|
||||
Executable
+282
@@ -0,0 +1,282 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2012 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
# Note: this script is not yet usable outside Google, because it depends on a
|
||||
# corpus database that we can't open source. It should be possible to create a
|
||||
# db with a combination of mod_pagespeed's slurping and a headless browser, but
|
||||
# we don't currently have a script or instructions on how to do this.
|
||||
# TODO(jefftk): resolve this
|
||||
#
|
||||
# This script runs a mod_pagespeed load-test. The typical
|
||||
# configuration is to run this on your development workstation and
|
||||
# mps_generate_load.sh will be run (via ssh) on a different machine
|
||||
# (localhost by default, for single-machine runs).
|
||||
#
|
||||
# Usage: scripts/mps_load_test.sh
|
||||
# [-start_apache_then_exit]
|
||||
# [-custom_so mod_pagespeed.so]
|
||||
# [-custom_so24 mod_pagespeed_ap24.so]
|
||||
# [-user_agent user_agent_string]
|
||||
# [-chrome]
|
||||
# [-memcached|-redis]
|
||||
# [-ipro_preserve]
|
||||
# [-purging]
|
||||
# [-inline_unauthorized_resources]
|
||||
# [-ssl]
|
||||
# [-debug]
|
||||
# [corpus_file.tar.bz2]
|
||||
#
|
||||
# Note: Order of supplied command line parameters matters for correct working.
|
||||
#
|
||||
# corpus_file.tar.bz2 is mandatory on the first run and ignored on later runs.
|
||||
# The extracted version is stored in the directory specified by $corpus (see
|
||||
# below) between runs.
|
||||
#
|
||||
# Example of user_agent_string: Chrome/23.0.1271.17
|
||||
# Saying '-chrome' is equivalent to saying 'give me a recent version of Chrome,
|
||||
# which needs to be updated by editing this script.
|
||||
#
|
||||
# If the 'machine name' argument is "localhost" then:
|
||||
# - you will not be prompted for your ssh password
|
||||
# - your machine will be unusable for a little while
|
||||
# - your results may be more consistent
|
||||
#
|
||||
# This scripts prompts you for your su password if it needs to set your
|
||||
# /proc/sys/net/ipv4/tcp_tw_recycle file to contain a "1".
|
||||
|
||||
set -e # exit script if any command returns an error
|
||||
set -u # exit the script if any variable is uninitialized
|
||||
|
||||
this_dir=$(dirname "${BASH_SOURCE[0]}")
|
||||
cd "$this_dir/.."
|
||||
src="$PWD"
|
||||
|
||||
gen_load="$src/devel/mps_generate_load.sh"
|
||||
corpus="$HOME/pagespeed-loadtest-corpus"
|
||||
|
||||
start_apache_then_exit=0
|
||||
|
||||
# Check if we are asked for an external cache (e.g memcached or redis) but
|
||||
# don't have a port configured first, as we need to re-launch ourselves using
|
||||
# run_program_with_EXTCACHE.sh, so we don't want to mess up $@.
|
||||
for argument in "$@"; do
|
||||
if [ "$argument" = "-memcached" -a -z "${MEMCACHED_PORT+x}" ]; then
|
||||
exec "$src/install/run_program_with_memcached.sh" \
|
||||
"$src/devel/mps_load_test.sh" "$@"
|
||||
elif [ "$argument" = "-redis" -a -z "${REDIS_PORT+x}" ]; then
|
||||
exec "$src/install/run_program_with_redis.sh" \
|
||||
"$src/devel/mps_load_test.sh" "$@"
|
||||
fi
|
||||
done
|
||||
|
||||
if [[ $# -ge 1 && "$1" = "-start_apache_then_exit" ]]; then
|
||||
start_apache_then_exit=1
|
||||
shift
|
||||
fi
|
||||
|
||||
custom_so=
|
||||
if [[ $# -ge 2 && "$1" = "-custom_so" ]]; then
|
||||
custom_so=$2
|
||||
shift 2
|
||||
fi
|
||||
|
||||
custom_so24=
|
||||
if [[ $# -ge 2 && "$1" = "-custom_so24" ]]; then
|
||||
custom_so24=$2
|
||||
shift 2
|
||||
fi
|
||||
|
||||
if [[ $# -ge 1 && "$1" = "-chrome" ]]; then
|
||||
export USER_AGENT_FLAG="--user_agent Chrome/47.0.2526.80"
|
||||
shift
|
||||
elif [[ $# -ge 2 && "$1" = "-user_agent" ]]; then
|
||||
export USER_AGENT_FLAG="--user_agent $2"
|
||||
shift 2
|
||||
else
|
||||
export USER_AGENT_FLAG=
|
||||
fi
|
||||
|
||||
if [[ $# -ge 1 && "$1" = "-memcached" ]]; then
|
||||
echo Using memcached on port $MEMCACHED_PORT
|
||||
shift
|
||||
export MEMCACHED=1
|
||||
export REDIS=0
|
||||
cache_stat_prefix="memcache"
|
||||
elif [[ $# -ge 1 && "$1" = "-redis" ]]; then
|
||||
echo Using redis on port "$REDIS_PORT"
|
||||
shift
|
||||
export MEMCACHED=0
|
||||
export REDIS=1
|
||||
cache_stat_prefix="redis"
|
||||
else
|
||||
export MEMCACHED=0
|
||||
export REDIS=0
|
||||
cache_stat_prefix="file_cache_"
|
||||
fi
|
||||
|
||||
if [[ $# -ge 1 && "$1" = "-ipro_preserve" ]]; then
|
||||
shift
|
||||
export IPRO_PRESERVE=1
|
||||
export EXTRA_URL_FLAGS=--ipro_preserve
|
||||
else
|
||||
export IPRO_PRESERVE=0
|
||||
export EXTRA_URL_FLAGS=
|
||||
fi
|
||||
|
||||
if [[ $# -ge 1 && "$1" = "-purging" ]]; then
|
||||
shift
|
||||
export PURGING=1
|
||||
else
|
||||
export PURGING=0
|
||||
fi
|
||||
|
||||
if [[ $# -ge 1 && "$1" = "-inline_unauthorized_resources" ]]; then
|
||||
shift
|
||||
export IUR=1
|
||||
else
|
||||
export IUR=0
|
||||
fi
|
||||
|
||||
if [[ $# -ge 1 && "$1" = "-ssl" ]]; then
|
||||
shift
|
||||
export EXTRA_FETCH_FLAGS=--ssl
|
||||
else
|
||||
export EXTRA_FETCH_FLAGS=
|
||||
fi
|
||||
|
||||
if [[ $# -ge 1 && "$1" = "-debug" ]]; then
|
||||
shift
|
||||
compile_mode="Debug"
|
||||
else
|
||||
compile_mode="OptDebug"
|
||||
fi
|
||||
|
||||
if [ $# -ge 2 ]; then
|
||||
echo "Unknown arguments: $@"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ ! -d "$corpus" ] && [ $# -ne 1 ]; then
|
||||
echo "Invalid arguments: corpus required"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ -d "$corpus" ] && [ $# -ne 0 ]; then
|
||||
echo "Warning: using already extracted corpus instead of $1"
|
||||
fi
|
||||
|
||||
# If an 'su' password is required, then get it before going off and compiling
|
||||
# stuff.
|
||||
"$src/devel/turn_on_timewait_recyling.sh"
|
||||
|
||||
if [ -d /var/run/pagespeed/ ]; then
|
||||
rm -rf /var/run/pagespeed/*
|
||||
else
|
||||
sudo mkdir -p /var/run/pagespeed
|
||||
sudo chown $USER /var/run/pagespeed
|
||||
fi
|
||||
|
||||
# Only ssh (and warn user that they will need a password) if using a separate
|
||||
# host for load generation.
|
||||
cmd="$gen_load $EXTRA_URL_FLAGS $EXTRA_FETCH_FLAGS $USER_AGENT_FLAG"
|
||||
|
||||
APACHE_DEBUG_ROOT=${APACHE_DEBUG_ROOT:-$HOME/apache2}
|
||||
|
||||
echo Checking whether we have the corpus available.
|
||||
if [ ! -d "$corpus" ]; then
|
||||
corpus_src="$1"
|
||||
echo "Copying corpus files from $corpus_src"
|
||||
mkdir -p "$corpus"
|
||||
cd "$corpus"
|
||||
tar xjf "$corpus_src"
|
||||
fi
|
||||
|
||||
cd "$src/devel"
|
||||
|
||||
# Build a version of mod_pagespeed with all optimizations enabled, but with
|
||||
# a build that includes DCHECKs.
|
||||
make -j8 CONF=$compile_mode apache_trace_stress_test_server \
|
||||
DUMP_DIR="$corpus" \
|
||||
APACHE_DEBUG_ROOT=${APACHE_DEBUG_ROOT} \
|
||||
MOD_PAGESPEED_CACHE=/var/run/pagespeed/cache
|
||||
|
||||
# If a custom .so got specified, install it.
|
||||
if [[ -n "$custom_so" ]]; then
|
||||
install -c $custom_so /usr/local/apache2/modules/mod_pagespeed.so
|
||||
fi
|
||||
|
||||
if [[ -n "$custom_so24" ]]; then
|
||||
install -c $custom_so24 /usr/local/apache2/modules/mod_pagespeed_ap24.so
|
||||
fi
|
||||
|
||||
# Restart apache for any hand-specified .so or alternative binary
|
||||
if [[ -n "$custom_so" || -n "$custom_so24" ]]; then
|
||||
make apache_debug_stop
|
||||
make apache_debug_start
|
||||
fi
|
||||
|
||||
if [[ "$start_apache_then_exit" = 1 ]]; then
|
||||
exit 0
|
||||
fi
|
||||
|
||||
stop_crash_scraper="/tmp/stop_crash_scraper"
|
||||
error_log="$APACHE_DEBUG_ROOT/logs/error_log"
|
||||
rm -f "$stop_crash_scraper"
|
||||
|
||||
echo starting test ...
|
||||
"$src/devel/scrape_error_log_for_crashes.sh" \
|
||||
"$error_log" "$stop_crash_scraper" &
|
||||
echo $cmd ...
|
||||
$cmd
|
||||
touch "$stop_crash_scraper"
|
||||
|
||||
# Print some interesting statistics from the server
|
||||
statsfile=/tmp/mps_load_test_stats.$$
|
||||
wget -q -O $statsfile http://localhost:8080/mod_pagespeed_global_statistics
|
||||
grep "$cache_stat_prefix" $statsfile | grep -v onchange=
|
||||
grep shm $statsfile
|
||||
grep dropped $statsfile
|
||||
grep cache_batcher $statsfile
|
||||
grep rewrite_cached_output_missed_deadline $statsfile
|
||||
grep bytes_saved $statsfile
|
||||
grep serf $statsfile
|
||||
grep queued-fetch-count $statsfile
|
||||
grep page_load_count $statsfile
|
||||
grep 404_count $statsfile
|
||||
grep file_cache_bytes_freed_in_cleanup $statsfile
|
||||
grep file_cache_cleanups $statsfile
|
||||
grep file_cache_write_errors $statsfile
|
||||
grep image_webp_rewrites $statsfile
|
||||
egrep "num_css|num_js" $statsfile
|
||||
rm -f $statsfile
|
||||
|
||||
set +e
|
||||
echo 'egrep "exit signal|CRASH" $error_log'
|
||||
egrep "exit signal|CRASH" $error_log
|
||||
if [ $? = 0 ]; then
|
||||
echo "*** $error_log has dangerous looking errors. Please investigate."
|
||||
exit 1
|
||||
else
|
||||
echo "No deaths reported in $error_log -- ship it."
|
||||
fi
|
||||
|
||||
if [ "$MEMCACHED" = "1" -o "$REDIS" = "1" ]; then
|
||||
date
|
||||
echo -n Sleeping 5 seconds before killing external cache server to let
|
||||
echo -n outstanding writes quiesce...
|
||||
sleep 5
|
||||
echo done
|
||||
fi
|
||||
Executable
+29
@@ -0,0 +1,29 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2012 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
if [ $# -lt 2 ]; then
|
||||
echo Usage: $0 error_log_filename stop_filename
|
||||
exit 1
|
||||
fi
|
||||
|
||||
error_log="$1"
|
||||
stop_file="$2"
|
||||
|
||||
(tail -f $error_log | egrep "exit signal|CRASH") & background_pid=$!
|
||||
while [ ! -e "$stop_file" ]; do sleep 10; done
|
||||
kill $background_pid
|
||||
|
||||
rm -f "$stop_file"
|
||||
@@ -0,0 +1,50 @@
|
||||
# Global configuration.
|
||||
#
|
||||
# The ModPagespeedFileCachePath directory must exist and be writable
|
||||
# by the apache user (as specified by the User directive).
|
||||
ModPagespeedFileCachePath "#HOME/apache2/pagespeed_cache/"
|
||||
|
||||
# Direct Apache to send all HTML output to the mod_pagespeed
|
||||
# output handler.
|
||||
AddOutputFilterByType MOD_PAGESPEED_OUTPUT_FILTER text/html
|
||||
|
||||
<VirtualHost localhost:8080>
|
||||
# Turn on mod_pagespeed. To completely disable mod_pagespeed, you
|
||||
# can set this to "off".
|
||||
ModPagespeed on
|
||||
|
||||
<Location /pagespeed_admin>
|
||||
Order allow,deny
|
||||
Allow from localhost
|
||||
Allow from 127.0.0.1
|
||||
SetHandler pagespeed_admin
|
||||
</Location>
|
||||
<Location /pagespeed_global_admin>
|
||||
Order allow,deny
|
||||
Allow from localhost
|
||||
Allow from 127.0.0.1
|
||||
SetHandler pagespeed_global_admin
|
||||
</Location>
|
||||
|
||||
# By default we siege-test without image beaconing.
|
||||
ModPagespeedCriticalImagesBeaconEnabled false
|
||||
|
||||
# Turn on "KeepAlive" so the sieges go fast.
|
||||
KeepAlive On
|
||||
KeepAliveTimeout 60
|
||||
LogFormat "%v %X %P %h %l %u %t \"%r\" %>s %b" common
|
||||
LogLevel warn
|
||||
|
||||
# This configuration is required for siege_instant_ipro.
|
||||
<Directory "#HOME/apache2/htdocs/mod_pagespeed_test/ipro/instant/wait/" >
|
||||
ModPagespeedInPlaceWaitForOptimized on
|
||||
ModPagespeedInPlaceRewriteDeadlineMs 5000
|
||||
</Directory>
|
||||
|
||||
<Directory "#HOME/apache2/htdocs/" >
|
||||
# This is enabled to make sure we don't crash mod_negotiation.
|
||||
Options +MultiViews
|
||||
</Directory>
|
||||
|
||||
# Test-specific configuration: #CUSTOM_CONFIG
|
||||
</VirtualHost>
|
||||
Executable
+39
@@ -0,0 +1,39 @@
|
||||
#!/bin/sh
|
||||
|
||||
this_dir=$(dirname "${BASH_SOURCE[0]}")
|
||||
|
||||
sieges=(extended_css extended_js html_high_entropy html instant_ipro \
|
||||
ipro_image ipro_image_memcached rewritten_css rewritten_js)
|
||||
|
||||
echo "$(date): Starting ${#sieges[*]} sieges ..."
|
||||
|
||||
# So we can make the transactions/second line up, figure out the padding
|
||||
# we'll need for smaller siege-names.
|
||||
max_len=0
|
||||
for siege in "${sieges[@]}"; do
|
||||
len=${#siege}
|
||||
if [ "$len" -gt "$max_len" ]; then
|
||||
max_len=$len
|
||||
fi
|
||||
done
|
||||
|
||||
status=0
|
||||
for siege in ${sieges[*]}; do
|
||||
out="/tmp/siege_$siege.out"
|
||||
|
||||
# Make the columns line up by padding with spaces before the >& and "."
|
||||
# before the transactions-per-second.
|
||||
dots=$(eval printf "%0.s." {0..$((max_len - ${#siege}))})
|
||||
spaces=$(echo "$dots" | sed -e 's/./ /g')
|
||||
echo -n "$this_dir/siege_$siege.sh$spaces >& $out$dots.."
|
||||
"$this_dir/siege_$siege.sh" &> "$out"
|
||||
if [ $? -eq 0 ]; then
|
||||
grep "Transaction rate:" "$out" |cut -f2 -d: | \
|
||||
sed -e 's/^[[:space:]]*//' -e 's/[[:space:]]*$//'
|
||||
else
|
||||
echo FAILED
|
||||
status=1
|
||||
fi
|
||||
done
|
||||
echo "$(date): Finished sieges, exit status $status"
|
||||
exit $status
|
||||
Executable
+25
@@ -0,0 +1,25 @@
|
||||
#!/bin/sh
|
||||
# Runs 'siege' on a single cache-extended URL cache-extended CSS file
|
||||
# scraped from rewrite_css.html.
|
||||
#
|
||||
# Usage:
|
||||
# devel/siege/siege_extended_css.sh
|
||||
|
||||
this_dir=$(dirname "${BASH_SOURCE[0]}")
|
||||
source "$this_dir/siege_helper.sh" || exit 1
|
||||
|
||||
# Fetch the rewrite_css example in cache-extend mode so we can get a small
|
||||
# cache-extended CSS file.
|
||||
EXAMPLE="http://localhost:8080/mod_pagespeed_example"
|
||||
|
||||
# The format of the 'link' HTML line we get is this:
|
||||
# <link rel="stylesheet" type="text/css"
|
||||
# href="styles/yellow.css.pagespeed.ce.lzJ8VcVi1l.css">
|
||||
# The line-break before 'href' is added here to avoid exceeding 80 cols
|
||||
# in this script but is not in the HTML.
|
||||
#
|
||||
# Splitting this by quotes seems a little fragile but it gets us the
|
||||
# URL in the 6th token.
|
||||
extract_pagespeed_url $EXAMPLE/rewrite_css.html 'link rel=' 6 extend_cache
|
||||
|
||||
run_siege "$EXAMPLE/$url"
|
||||
Executable
+15
@@ -0,0 +1,15 @@
|
||||
#!/bin/sh
|
||||
|
||||
this_dir=$(dirname "${BASH_SOURCE[0]}")
|
||||
source "$this_dir/siege_helper.sh" || exit 1
|
||||
|
||||
# Fetch the rewrite_css example in cache-extend mode so we can get a small
|
||||
# cache-extended CSS file.
|
||||
EXAMPLE="http://localhost:8080/mod_pagespeed_example"
|
||||
|
||||
# The format of the 'script' HTML line we want is this:
|
||||
# <script src="rewrite_javascript.js" ...
|
||||
extract_pagespeed_url $EXAMPLE/rewrite_javascript.html 'script src=' \
|
||||
2 extend_cache
|
||||
|
||||
run_siege "$EXAMPLE/$url"
|
||||
Executable
+120
@@ -0,0 +1,120 @@
|
||||
# This file expects to be sourced from another file in the same directory in
|
||||
# order to set us up for siege testing.
|
||||
|
||||
set -u # exit the script if any variable is uninitialized
|
||||
set -e
|
||||
|
||||
if [ -d devel ]; then
|
||||
cd devel
|
||||
fi
|
||||
if [ ! -d siege ]; then
|
||||
echo Run this script from the top or devel/ directories
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if ! hash siege 2>/dev/null; then
|
||||
echo "'siege' command is not found, please install it. "
|
||||
echo "siege_instant_ipro needs 3.0.8 or newer, other tests work with 3.0.5 "
|
||||
echo "as well."
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# If an 'su' password is required, then get it before going off and compiling
|
||||
# stuff.
|
||||
./turn_on_timewait_recyling.sh
|
||||
|
||||
# Build optimized mod_pagespeed.so if necessary, and restart it.
|
||||
callgrind=0
|
||||
if [ $# -eq 1 ]; then
|
||||
if [ $1 == "-callgrind" ]; then
|
||||
shift
|
||||
callgrind=1
|
||||
fi
|
||||
fi
|
||||
|
||||
# Stop callgrind if it was running previously.
|
||||
callgrind_control -k
|
||||
|
||||
# Clear all caches to make sure we start from a known state.
|
||||
make clean_slate_for_tests
|
||||
|
||||
# This variable contains config that we want to inject into siege.conf when
|
||||
# constructing pagespeed.conf, by sed-replacing "CUSTOM_CONFIG". This works
|
||||
# with multiple config lines.
|
||||
custom_config=""
|
||||
function add_config_line() {
|
||||
custom_config+="\n $1"
|
||||
}
|
||||
|
||||
# If $MEMCACHED_PORT is set (i.e. we were run from
|
||||
# run_program_with_memcached.sh) then configure it in the apache conf.
|
||||
set +u
|
||||
if [ ! -z "$MEMCACHED_PORT" ]; then
|
||||
add_config_line "ModPagespeedMemcachedServers localhost:$MEMCACHED_PORT"
|
||||
fi
|
||||
set -u
|
||||
|
||||
make apache_debug_stop
|
||||
sed -e "s/#CUSTOM_CONFIG/$custom_config/" -e "s^#HOME^$HOME^" < siege/siege.conf \
|
||||
> ~/apache2/conf/pagespeed.conf
|
||||
|
||||
if [ $callgrind -eq 1 ]; then
|
||||
echo running with callgrind...
|
||||
make -j8 apache_debug_install CONF=OptDebug
|
||||
valgrind --tool=callgrind --collect-systime=yes ~/apache2/bin/httpd -X &
|
||||
sleep 5
|
||||
callgrind=1
|
||||
else
|
||||
echo running without calgrind -- use -callgrind to get a profile.
|
||||
make -j8 apache_debug_restart BUILDTYPE=Release
|
||||
fi
|
||||
|
||||
# This function returns its value in shell variable 'url'. Note that it
|
||||
# will return whatever is in the HTML value, which is usually a relative
|
||||
# url.
|
||||
function extract_pagespeed_url() {
|
||||
url=""
|
||||
html=$1
|
||||
grep_pattern="$2"
|
||||
url_token_index="$3"
|
||||
filters="$4"
|
||||
OPTIONS="?PageSpeedFilters=$filters"
|
||||
|
||||
echo -n Finding pagespeed url in $html${OPTIONS}, pattern=\"${grep_pattern}\"
|
||||
echo ' #' $url_token_index
|
||||
while true; do
|
||||
LINE=$(wget -q -O - $html$OPTIONS | grep "$grep_pattern")
|
||||
if [ "$LINE" != '' ]; then
|
||||
url=$(echo $LINE | cut -d\" -f$url_token_index)
|
||||
echo $url
|
||||
break
|
||||
else
|
||||
sleep .1
|
||||
echo -n '.'
|
||||
fi
|
||||
done
|
||||
}
|
||||
|
||||
this_file=$(basename "$0")
|
||||
this_name=$(basename "$this_file" .sh)
|
||||
common_options=("--log=/tmp/$this_name.log" --rc=/dev/null)
|
||||
|
||||
# Runs siege, passing on any provided arguments.
|
||||
function run_siege_with_options() {
|
||||
(set -x; siege "${common_options[@]}" "$@")
|
||||
|
||||
if [ $callgrind -eq 1 ]; then
|
||||
sleep 2
|
||||
callgrind_control -d
|
||||
ls -ltR callgrind.*
|
||||
echo Type \'callgrind_control -k\' to close down valgrind.
|
||||
fi
|
||||
|
||||
(set -x; ./expectfail egrep "exit signal|CRASH" \
|
||||
~/apache2/logs/error_log)
|
||||
}
|
||||
|
||||
# Run siege on a set of arguments, with reasonable defaults.
|
||||
function run_siege() {
|
||||
run_siege_with_options --benchmark --time=60s --concurrent=50 "$@"
|
||||
}
|
||||
Executable
+16
@@ -0,0 +1,16 @@
|
||||
#!/bin/sh
|
||||
# Runs 'siege' on a HTML file.
|
||||
#
|
||||
# Usage:
|
||||
# devel/siege/siege_html.sh
|
||||
|
||||
this_dir=$(dirname "${BASH_SOURCE[0]}")
|
||||
source "$this_dir/siege_helper.sh" || exit 1
|
||||
|
||||
# TODO(jmarantz): There appears to be no better way to turn all
|
||||
# filters off via query-param. Though you might think that
|
||||
# PageSpeedRewriteLevel=PassThrough should work, it does not. There
|
||||
# is special handling for PageSpeedFilters=core but not for
|
||||
# PassThrough.
|
||||
URL="http://localhost:8080/mod_pagespeed_example/collapse_whitespace.html?PageSpeedFilters=rewrite_domains"
|
||||
run_siege "$URL"
|
||||
Executable
+32
@@ -0,0 +1,32 @@
|
||||
#!/bin/sh
|
||||
# Runs 'siege' on a HTML file, but with 400k unique query-params. We
|
||||
# use 400k because a typical siege covers >300k transactions and we
|
||||
# want to avoid repeats.
|
||||
#
|
||||
# Usage:
|
||||
# devel/siege/siege_html_high_entropy.sh
|
||||
|
||||
this_dir=$(dirname "${BASH_SOURCE[0]}")
|
||||
source "$this_dir/siege_helper.sh" || exit 1
|
||||
|
||||
# Generate a list of unique URLs, each of which resolving to the same trival
|
||||
# HTML file. I don't see an easy way of specifying zero rewriters (default is
|
||||
# CoreFilters) but by specifying a single rewriter "rewrite_domains" as a
|
||||
# query-param, we can emulate that. Note that "rewrite_domains" doesn't do
|
||||
# anything if there are no domain-mappings set up.
|
||||
#
|
||||
# TODO(jmarantz): There appears to be no better way to turn all
|
||||
# filters off via query-param. Though you might think that
|
||||
# PageSpeedRewriteLevel=PassThrough should work, it does not. There
|
||||
# is special handling for PageSpeedFilters=core but not for
|
||||
# PassThrough.
|
||||
echo "Generating URLs..."
|
||||
urls="/tmp/high_entropy_urls.list.$$"
|
||||
> "$urls"
|
||||
trap "rm -f $urls" EXIT
|
||||
base_url="http://localhost:8080/mod_pagespeed_example/collapse_whitespace.html?PageSpeedFilters=rewrite_domains&q"
|
||||
for i in {1..400000}; do
|
||||
echo "$base_url=$i" >> "$urls"
|
||||
done
|
||||
|
||||
run_siege --file="$urls"
|
||||
Executable
+61
@@ -0,0 +1,61 @@
|
||||
#!/bin/sh
|
||||
|
||||
if ! hash siege 2>/dev/null; then
|
||||
echo "'siege' command is not found. Please install siege >=3.0.8."
|
||||
echo "Note that repository may contain older version of Siege."
|
||||
exit 1
|
||||
fi
|
||||
|
||||
# Check that siege is at least 3.0.8.
|
||||
siege_version=$(siege --version 2>&1 | head -n 1 | awk '{print $2}')
|
||||
major=$(echo "$siege_version" | awk -F. '{print $1}')
|
||||
minor=$(echo "$siege_version" | awk -F. '{print $2}')
|
||||
point=$(echo "$siege_version" | awk -F. '{print $3}')
|
||||
|
||||
recent_siege=false
|
||||
if [ "$major" -gt 3 ]; then
|
||||
recent_siege=true
|
||||
elif [ "$major" -eq 3 ]; then
|
||||
if [ "$minor" -gt 0 ]; then
|
||||
recent_siege=true
|
||||
elif [ "$point" -ge 8 ]; then
|
||||
recent_siege=true
|
||||
fi
|
||||
fi
|
||||
|
||||
if ! "$recent_siege"; then
|
||||
# Versions before 3.0.8 didn't include the port number in the host header.
|
||||
echo "$0: siege is version $siege_version but we need at least 3.0.8"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
this_dir=$(dirname "${BASH_SOURCE[0]}")
|
||||
source "$this_dir/siege_helper.sh" || exit 1
|
||||
|
||||
# Make a list of urls large enough that we can run through them for at least
|
||||
# 20s.
|
||||
urls_file=$(mktemp /tmp/siege.urls.XXXXXX)
|
||||
function remove_urls_file() {
|
||||
rm "$urls_file" 2> /dev/null
|
||||
}
|
||||
trap remove_urls_file EXIT
|
||||
url_base="http://localhost:8080/mod_pagespeed_test/"
|
||||
url_base+="ipro/instant/wait/purple.css?$RANDOM="
|
||||
echo "Building url file..."
|
||||
> "$urls_file"
|
||||
N=100000
|
||||
for i in $(seq 1 "$N"); do
|
||||
echo "$url_base$i" >> "$urls_file"
|
||||
done
|
||||
|
||||
# The siege documentation suggests that --reps means how many times to run
|
||||
# through the file of urls, but it's actually implemented as meaning the number
|
||||
# of urls each of the concurrent processes should run through. So if we have N
|
||||
# urls to test and C processes, then each process should get N/C urls.
|
||||
C=10
|
||||
R="$(($N/$C))"
|
||||
run_siege_with_options \
|
||||
--file="$urls_file" \
|
||||
--reps="$R" \
|
||||
--benchmark \
|
||||
--concurrent="$C"
|
||||
Executable
+25
@@ -0,0 +1,25 @@
|
||||
#!/bin/sh
|
||||
# Runs 'siege' on a single ipro-optimized image.
|
||||
#
|
||||
# Usage:
|
||||
# devel/siege/siege_ipro_image.sh
|
||||
|
||||
this_dir=$(dirname "${BASH_SOURCE[0]}")
|
||||
source "$this_dir/siege_helper.sh" || exit 1
|
||||
|
||||
echo "Waiting for the image to be IPRO-optimized..."
|
||||
URL="http://localhost:8080/mod_pagespeed_example/images/Puzzle.jpg"
|
||||
|
||||
while true; do
|
||||
content_length=$(curl -sS -D- -o /dev/null "$URL" | \
|
||||
grep '^Content-Length: ' | \
|
||||
grep -o '[0-9]*')
|
||||
if [ "$content_length" -lt 100000 ]; then
|
||||
# the image is fully ipro optimized
|
||||
break
|
||||
fi
|
||||
sleep .1
|
||||
echo -n .
|
||||
done
|
||||
|
||||
run_siege "$URL"
|
||||
Executable
+12
@@ -0,0 +1,12 @@
|
||||
#!/bin/sh
|
||||
# Runs 'siege' on a single ipro-optimized image with memcached.
|
||||
#
|
||||
# Usage:
|
||||
# devel/siege/siege_ipro_image_memcached.sh
|
||||
|
||||
this_dir=$(readlink -e "$(dirname "${BASH_SOURCE[0]}")")
|
||||
root_dir=$(readlink -e "$this_dir/../..")
|
||||
install_dir="$root_dir/install"
|
||||
|
||||
set -e
|
||||
"$install_dir/run_program_with_memcached.sh" "$this_dir/siege_ipro_image.sh"
|
||||
Executable
+25
@@ -0,0 +1,25 @@
|
||||
#!/bin/sh
|
||||
# Runs 'siege' on a single cache-extended URL cache-extended CSS file
|
||||
# scraped from rewrite_css.html.
|
||||
#
|
||||
# Usage:
|
||||
# devel/siege/siege_extended_css.sh
|
||||
|
||||
this_dir=$(dirname "${BASH_SOURCE[0]}")
|
||||
source "$this_dir/siege_helper.sh" || exit 1
|
||||
|
||||
# Fetch the rewrite_css example in cache-extend mode so we can get a small
|
||||
# cache-extended CSS file.
|
||||
EXAMPLE="http://localhost:8080/mod_pagespeed_example"
|
||||
|
||||
# The format of the 'link' HTML line we get is this:
|
||||
# <link rel="stylesheet" type="text/css"
|
||||
# href="styles/yellow.css.pagespeed.ce.lzJ8VcVi1l.css">
|
||||
# The line-break before 'href' is added here to avoid exceeding 80 cols
|
||||
# in this script but is not in the HTML.
|
||||
#
|
||||
# Splitting this by quotes seems a little fragile but it gets us the
|
||||
# URL in the 6th token.
|
||||
extract_pagespeed_url $EXAMPLE/rewrite_css.html 'link rel=' 6 rewrite_css
|
||||
|
||||
run_siege "$EXAMPLE/$url"
|
||||
Executable
+15
@@ -0,0 +1,15 @@
|
||||
#!/bin/sh
|
||||
|
||||
this_dir=$(dirname "${BASH_SOURCE[0]}")
|
||||
source "$this_dir/siege_helper.sh" || exit 1
|
||||
|
||||
# Fetch the rewrite_css example in cache-extend mode so we can get a small
|
||||
# cache-extended CSS file.
|
||||
EXAMPLE="http://localhost:8080/mod_pagespeed_example"
|
||||
|
||||
# The format of the 'script' HTML line we want is this:
|
||||
# <script src="rewrite_javascript.js" ...
|
||||
extract_pagespeed_url $EXAMPLE/rewrite_javascript.html 'script src=' \
|
||||
2 rewrite_javascript
|
||||
|
||||
run_siege "$EXAMPLE/$url"
|
||||
Executable
+84
@@ -0,0 +1,84 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2016 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
|
||||
set -e
|
||||
set -u
|
||||
|
||||
APACHE_SERVER="$1"
|
||||
APACHE_SLURP_ORIGIN_PORT="$2"
|
||||
APACHE_SLURP_PORT="$3"
|
||||
WGET="$4"
|
||||
TMP_SLURP_DIR="$5"
|
||||
PAGESPEED_TEST_HOST="$6"
|
||||
|
||||
this_dir=$(dirname "${BASH_SOURCE[0]}")
|
||||
source "$this_dir/../pagespeed/automatic/system_test_helpers.sh" \
|
||||
"$APACHE_SERVER"
|
||||
|
||||
EXTEND_CACHE_URL="http://www.modpagespeed.com/extend_cache.html"
|
||||
|
||||
DEVEL_DIR="$(dirname "${BASH_SOURCE[0]}")"
|
||||
|
||||
start_test "Testing slurping (read only, via proxy)"
|
||||
http_proxy="$APACHE_SERVER" "$WGET" -q -O /dev/null \
|
||||
"$EXTEND_CACHE_URL?PageSpeedFilters=extend_cache"
|
||||
|
||||
# TODO(sligocki): Use something like fetch_until rather than
|
||||
# always waiting 2 seconds :/
|
||||
sleep 2
|
||||
|
||||
OUT="$(http_proxy="$APACHE_SERVER" "$WGET" -q -O - \
|
||||
"$EXTEND_CACHE_URL?PageSpeedFilters=extend_cache")"
|
||||
check_from "$OUT" fgrep "images/Puzzle.jpg.pagespeed.ce."
|
||||
|
||||
OUT="$(http_proxy="$APACHE_SERVER" "$WGET" -q -O - \
|
||||
"$EXTEND_CACHE_URL?PageSpeed=off")"
|
||||
check_from "$OUT" fgrep '"images/Puzzle.jpg"'
|
||||
|
||||
start_test "Testing slurping (dns mode, mimicing webpagetest)"
|
||||
OUT="$("$WGET" --header="Host: www.modpagespeed.com" -q -O - --save-headers \
|
||||
"$EXTEND_CACHE_URL?PageSpeedFilters=extend_cache")"
|
||||
check_from "$OUT" grep -q 'HTTP/1.[01] 200 OK'
|
||||
|
||||
start_test "Testing slurping http://www.example.com expecting index.html ..."
|
||||
echo "rewrite will not happen"
|
||||
OUT="$(http_proxy="$APACHE_SERVER" "$WGET" -q -O - http://www.example.com/)"
|
||||
check_from "$OUT" fgrep "example.com expected body"
|
||||
|
||||
start_test "Connection-close stripping:"
|
||||
echo 'First check we get "Connection:close"'
|
||||
|
||||
echo "straight from the origin -- no proxy."
|
||||
rm -rf "$TMP_SLURP_DIR"
|
||||
|
||||
slurp_origin_url="http://localhost:$APACHE_SLURP_ORIGIN_PORT"
|
||||
slurp_origin_url+="/close_connection/close_connection.html"
|
||||
|
||||
OUT="$("$WGET" --no-proxy -q --save-headers -O - --header="Connection:" \
|
||||
"$slurp_origin_url")"
|
||||
check_from "$OUT" fgrep "Connection: close"
|
||||
|
||||
echo "Now check that Connection:close is stripped from a writing slurp."
|
||||
OUT=$(http_proxy=localhost:$APACHE_SLURP_PORT "$WGET" -q --save-headers -O - \
|
||||
--header="Connection:" "$slurp_origin_url" || true)
|
||||
check_not_from "$OUT" fgrep -q "Connection: close"
|
||||
|
||||
start_test "Testing slurp-proxying of a POST"
|
||||
rm -rf "$TMP_SLURP_DIR"
|
||||
OUT="$(http_proxy=localhost:$APACHE_SLURP_PORT "$WGET" -q -O - \
|
||||
--post-data="a=b&c=d" \
|
||||
http://$PAGESPEED_TEST_HOST/do_not_modify/cgi/verify_post.cgi)"
|
||||
check_from "$OUT" grep "PASS"
|
||||
Executable
+152
@@ -0,0 +1,152 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2012 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# This scripts reads a list of URLs from the provided file, and
|
||||
# fetches them in parallel from a local slurping proxy in a randomized
|
||||
# order. Loading times and statuses for them are then output to
|
||||
# /tmp/latency-(encoding of settings).txt
|
||||
|
||||
# number of fetches to do in parallel
|
||||
if [ -z $PAR ]; then
|
||||
PAR=10
|
||||
fi
|
||||
|
||||
# number of times to run
|
||||
if [ -z $RUNS ]; then
|
||||
RUNS=3
|
||||
fi
|
||||
|
||||
# How many times to repeat each trace without restarting the workers
|
||||
if [ -z $EXP ]; then
|
||||
EXP=3
|
||||
fi
|
||||
|
||||
# Proxy machine. If you specify this, make sure to give an IP address,
|
||||
# as doing DNS lookups for it can slow things down a lot
|
||||
if [ -z $PROXY_HOST ]; then
|
||||
PROXY_HOST=127.0.0.1
|
||||
fi
|
||||
|
||||
# .. and port
|
||||
if [ -z $PROXY_PORT ]; then
|
||||
PROXY_PORT=8080
|
||||
fi
|
||||
|
||||
# Extra flags to pass to fetch_all.py
|
||||
FLAGS=${FLAGS:-}
|
||||
|
||||
USER_AGENT_FLAG=${USER_AGENT:+--user_agent}
|
||||
|
||||
if [ $# -lt 1 ]; then
|
||||
echo "Usage: devel/trace_stress_test.sh urls_file ..."
|
||||
echo "Shuffles each urls_file in turn, runs through shuffled file using"
|
||||
echo "$PAR parallel wget jobs. Repeats this process $RUN times."
|
||||
exit 2
|
||||
fi
|
||||
|
||||
OUR_PATH=`dirname $0`
|
||||
STAMP=`date +%Y%m%d-%H%M`
|
||||
LATENCY_REPORT=/tmp/latency-$PROXY_HOST-R$RUNS-P$PAR-E$EXP-$STAMP.txt
|
||||
TAIL_HEAD_TEMP=/tmp/tail_head.$$
|
||||
|
||||
echo "time status url" > $LATENCY_REPORT
|
||||
|
||||
# Examines file in $1, starting at line $2, and the next $3 lines into file $4.
|
||||
function tail_head {
|
||||
input_file=$1
|
||||
start_pos=$2
|
||||
num_lines=$3
|
||||
outfile=$4
|
||||
|
||||
# We make a temp file because otherwise we (at least Josh) get a lot of
|
||||
# "tail: write error" printed out.
|
||||
tail $input_file -n +$start_pos < $input_file > $TAIL_HEAD_TEMP
|
||||
head $TAIL_HEAD_TEMP -n $num_lines >$outfile
|
||||
}
|
||||
|
||||
function single_run {
|
||||
FILE=$1
|
||||
# Shuffle the log and split it into pieces
|
||||
SHUF_FILE=`mktemp`
|
||||
for I in `seq 1 $EXP`; do
|
||||
shuf $FILE >> $SHUF_FILE
|
||||
done
|
||||
LINES=`wc -l $SHUF_FILE | sed s#$SHUF_FILE##`
|
||||
# Setting chunk size slightly too large balances load a little better, most
|
||||
# obvious when $LINES < $PAR.
|
||||
CHUNK=`expr 1 + $LINES / $PAR`
|
||||
|
||||
# feed each chunk to a separate wget
|
||||
PIECES=
|
||||
LOGS=
|
||||
POS=0
|
||||
for I in `seq 1 $PAR`; do
|
||||
CUR_CHUNK=$CHUNK
|
||||
if [ $I -eq $PAR ]; then
|
||||
# make sure we also include the remainder
|
||||
EXTRA=`expr $LINES - $PAR \* $CHUNK`
|
||||
CUR_CHUNK=`expr $CUR_CHUNK + $EXTRA`
|
||||
fi
|
||||
PIECE=`mktemp`
|
||||
LOG=`mktemp`
|
||||
PIECES="$PIECES $PIECE"
|
||||
LOGS="$LOGS $LOG"
|
||||
tail_head $SHUF_FILE $POS $CUR_CHUNK $PIECE
|
||||
$OUR_PATH/fetch_all.py $FLAGS $USER_AGENT_FLAG $USER_AGENT \
|
||||
--proxy_host $PROXY_HOST --proxy_port $PROXY_PORT \
|
||||
--urls_file $PIECE &> $LOG &
|
||||
POS=`expr $POS + $CHUNK`
|
||||
done
|
||||
|
||||
# Wait for all to finish
|
||||
wait
|
||||
|
||||
# Print out the summary messages
|
||||
cat $LOGS >> $LATENCY_REPORT
|
||||
|
||||
# clean up
|
||||
rm $PIECES
|
||||
rm $LOGS
|
||||
rm $SHUF_FILE
|
||||
}
|
||||
|
||||
START=$SECONDS
|
||||
|
||||
for RUN in `seq 1 $RUNS`; do
|
||||
echo "Run $RUN"
|
||||
for FILE in "$@"; do
|
||||
echo "File $FILE"
|
||||
single_run "$FILE"
|
||||
done
|
||||
echo "----------------------------------------------------------------------"
|
||||
done
|
||||
|
||||
STOP=$SECONDS
|
||||
LINES=`tail -n +2 $LATENCY_REPORT|wc -l`
|
||||
ELAPSED=`expr $STOP - $START`
|
||||
QPS=`expr $LINES / $ELAPSED`
|
||||
echo "QPS estimate (inaccurate for short runs):" $QPS "requests/sec"
|
||||
echo
|
||||
$OUR_PATH/trace_stress_test_percentiles.sh $LATENCY_REPORT | cut -c 1-80
|
||||
echo
|
||||
echo "10 worst latencies:"
|
||||
head -n 10 ${LATENCY_REPORT%%.txt}-sorted.txt
|
||||
echo
|
||||
echo "Status statistics:"
|
||||
tail -n +2 $LATENCY_REPORT | cut -d ' ' -f 2 | sort | uniq -c
|
||||
echo "Full latency report in:" $LATENCY_REPORT
|
||||
|
||||
rm -f $TAIL_HEAD_TEMP
|
||||
|
||||
Executable
+36
@@ -0,0 +1,36 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2012 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
# This script takes the output of trace_stress_test.sh and reports cheap and
|
||||
# cheerful median, 75th, 90th, 95th, 99th, and worst latencies.
|
||||
if [ "X$1" == "X" ]; then
|
||||
# work from stdin
|
||||
sorted="/tmp/latency-$$-sorted.txt"
|
||||
sort -r -g -k 1 > $sorted
|
||||
else
|
||||
# construct sorted file name
|
||||
sorted="${1%%.txt}-sorted.txt"
|
||||
sort -r -g -k 1 "$1" > "$sorted"
|
||||
fi
|
||||
echo "Sorted latency data in: $sorted" 1>&2
|
||||
echo "% ms status url" 1>&2
|
||||
lines=$(wc -l < "$sorted")
|
||||
for i in 50 75 90 95 99; do
|
||||
divisor=$((100 / (100 - $i)))
|
||||
echo -n "$i "
|
||||
head -$(($lines / $divisor)) "$sorted" | tail -1
|
||||
done
|
||||
echo -n "mx "
|
||||
head -1 "$sorted"
|
||||
Executable
+35
@@ -0,0 +1,35 @@
|
||||
#!/bin/bash
|
||||
#
|
||||
# Copyright 2012 Google Inc.
|
||||
#
|
||||
# Licensed under the Apache License, Version 2.0 (the "License");
|
||||
# you may not use this file except in compliance with the License.
|
||||
# You may obtain a copy of the License at
|
||||
#
|
||||
# http://www.apache.org/licenses/LICENSE-2.0
|
||||
#
|
||||
# Unless required by applicable law or agreed to in writing, software
|
||||
# distributed under the License is distributed on an "AS IS" BASIS,
|
||||
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
# Makes linux enable fast reuse of sockets in TIME-WAIT state. We need this for
|
||||
# load testing so that we don't run out of connection table slots and fail to
|
||||
# get a socket. This isn't generally a good idea to set on public-facing
|
||||
# servers because of trouble with NATs, but is fine here.
|
||||
#
|
||||
# This scripts prompts you for your su password if TIME-WAIT recycling isn't
|
||||
# already enabled.
|
||||
|
||||
set -e # exit script if any command returns an error
|
||||
set -u # exit the script if any variable is uninitialized
|
||||
|
||||
recycle_file=/proc/sys/net/ipv4/tcp_tw_recycle
|
||||
if [ $(cat $recycle_file) -ne 1 ]; then
|
||||
echo "Putting a '1' in proc/sys/net/ipv4/tcp_tw_recycle to avoid"
|
||||
echo "running out of port numbers (due to old ones being in TIME_WAIT state)."
|
||||
echo 1 >/tmp/1
|
||||
sudo cp /tmp/1 $recycle_file
|
||||
rm /tmp/1
|
||||
fi
|
||||
@@ -0,0 +1,133 @@
|
||||
{
|
||||
Jpeg*Test - chromium_jpeg - Conditional jump or move depends on uninitialised value(s)
|
||||
Memcheck:Cond
|
||||
...
|
||||
fun:chromium_jpeg_*
|
||||
...
|
||||
fun:*Jpeg*Test_*
|
||||
}
|
||||
{
|
||||
Jpeg*Test - chromium_jpeg - Use of uninitialised value of size 8
|
||||
Memcheck:Value8
|
||||
...
|
||||
fun:chromium_jpeg_*
|
||||
...
|
||||
fun:*Jpeg*Test_*
|
||||
}
|
||||
{
|
||||
ImageTest - WebPEncode - Use of uninitialised value of size 8
|
||||
Memcheck:Value8
|
||||
...
|
||||
fun:WebPEncode
|
||||
...
|
||||
fun:*ImageTest_*
|
||||
}
|
||||
{
|
||||
PngOptimizerTest - DGifGetLine - Conditional jump or move depends on uninitialised value(s)
|
||||
Memcheck:Cond
|
||||
...
|
||||
fun:DGifGetLine
|
||||
...
|
||||
fun:*PngOptimizerTest_*
|
||||
}
|
||||
{
|
||||
JpegReaderTest - DecodeAndCompareImagesByPSNRENS - Conditional jump or move depends on uninitialised value(s)
|
||||
Memcheck:Cond
|
||||
...
|
||||
fun:*DecodeAndCompareImagesByPSNRENS*
|
||||
...
|
||||
fun:*JpegReaderTest_*
|
||||
}
|
||||
{
|
||||
re2 leaks a little memory on startup due to InitEmpty - Ignore it
|
||||
Memcheck:Leak
|
||||
...
|
||||
fun:*re2*InitEmpty*
|
||||
...
|
||||
}
|
||||
{
|
||||
protobufs with introspection leak a little memory -- Ignore it
|
||||
Memcheck:Leak
|
||||
...
|
||||
fun:*google*protobuf*internal*InitEmptyString*
|
||||
...
|
||||
}
|
||||
{
|
||||
ImageAnalysisTest - PhotoMetric - Conditional jump or move depends on uninitialised value(s)
|
||||
Memcheck:Cond
|
||||
...
|
||||
fun:*PhotoMetric*
|
||||
...
|
||||
fun:*ImageAnalysisTest_*
|
||||
}
|
||||
{
|
||||
ImageAnalysisTest - PhotoMetric - Use of uninitialised value of size 8
|
||||
Memcheck:Value8
|
||||
...
|
||||
fun:*Histogram*
|
||||
...
|
||||
fun:*ImageAnalysisTest_*
|
||||
}
|
||||
{
|
||||
ScanlineResizerTest - ResizeAndWrite - Conditional jump or move depends on uninitialised value(s)
|
||||
Memcheck:Cond
|
||||
...
|
||||
fun:*chromium_jpeg_write_scanlines*
|
||||
...
|
||||
fun:*ScanlineResizerTest_*
|
||||
}
|
||||
{
|
||||
ScanlineResizerTest - ResizeAndWrite - Conditional jump or move depends on uninitialised value(s)
|
||||
Memcheck:Cond
|
||||
...
|
||||
fun:*chromium_jpeg_finish_compress*
|
||||
...
|
||||
fun:*ScanlineResizerTest_*
|
||||
}
|
||||
{
|
||||
ScanlineResizerTest - ResizeAndWrite - Use of uninitialised value of size 8
|
||||
Memcheck:Value8
|
||||
...
|
||||
fun:*chromium_jpeg_finish_compress*
|
||||
...
|
||||
fun:*ScanlineResizerTest_*
|
||||
}
|
||||
{
|
||||
OpenSSL fancy math
|
||||
Memcheck:Value8
|
||||
fun:bn_mul_mont
|
||||
}
|
||||
{
|
||||
OpenSSL fancy math
|
||||
Memcheck:Value8
|
||||
fun:bn_mul4x_mont
|
||||
}
|
||||
{
|
||||
mod_ssl leak
|
||||
Memcheck:Leak
|
||||
...
|
||||
fun:EC_GROUP_new_by_curve_name
|
||||
...
|
||||
fun:ssl_init_Module
|
||||
}
|
||||
{
|
||||
GFlags bookkeeping
|
||||
Memcheck:Leak
|
||||
...
|
||||
fun:_ZN6google14FlagRegistererC1EPKcS2_S2_S2_PvS3_
|
||||
...
|
||||
}
|
||||
{
|
||||
RE2::Init singleton "leak"
|
||||
Memcheck:Leak
|
||||
...
|
||||
fun:_ZZN3re23RE24InitERKNS_11StringPieceERKNS0_7OptionsEENKUlvE_clEv
|
||||
}
|
||||
|
||||
{
|
||||
grpc error "leak" -- TODO(cheesy): find the root cause and eliminate.
|
||||
Memcheck:Leak
|
||||
...
|
||||
fun:grpc_error_create
|
||||
fun:grpc_server_add_insecure_http2_port
|
||||
}
|
||||
Executable
+39
@@ -0,0 +1,39 @@
|
||||
#!/bin/sh
|
||||
#
|
||||
# Given a deb, extract mod_pagespeed.so and mod_pagespeed_ap24.so. This is
|
||||
# useful for running load tests on prior releases. The files are left in a temp
|
||||
# directory, and the path to them is printed to stdout.
|
||||
|
||||
set -e # exit script if any command returns an error
|
||||
set -u # exit the script if any variable is uninitialized
|
||||
|
||||
if [ ! $# -eq 1 ]; then
|
||||
echo "Usage: ./extract_so_from_deb.sh mod-pagespeed-beta_current_amd64.deb"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
if [ ! -e $1 ]; then
|
||||
echo "File '$1' not found."
|
||||
exit 1
|
||||
fi
|
||||
|
||||
input_deb=$(readlink -e $1)
|
||||
|
||||
TMP=$(mktemp -d)
|
||||
cd "$TMP"
|
||||
mkdir scratch
|
||||
cd scratch
|
||||
|
||||
ar vx "$input_deb" > /dev/null
|
||||
# all deb files have a data.tar.gz, which is now in the current directory.
|
||||
tar -x --file=data.tar.gz \
|
||||
--wildcards ./usr/lib/apache2/modules/mod_pagespeed\*.so
|
||||
|
||||
mv usr/lib/apache2/modules/* ..
|
||||
cd ..
|
||||
rm -r scratch/
|
||||
|
||||
echo "The .so files are:"
|
||||
for x in $PWD/*; do
|
||||
echo " $x"
|
||||
done | sort -r
|
||||
@@ -0,0 +1,21 @@
|
||||
# Turn on server side include processing for the header inclusion.
|
||||
AddOutputFilter INCLUDES .html
|
||||
Options +Includes
|
||||
Options +FollowSymLinks
|
||||
|
||||
# Make /foo.html available at /foo
|
||||
RewriteEngine on
|
||||
RewriteCond %{REQUEST_FILENAME}.html -f
|
||||
RewriteRule !.*\.html$ %{REQUEST_FILENAME}.html [L]
|
||||
|
||||
# Turn on mod_pagespeed to optimize our docs.
|
||||
ModPagespeed on
|
||||
ModPagespeedRewriteLevel CoreFilters
|
||||
ModPagespeedEnableFilters collapse_whitespace
|
||||
ModPagespeedEnableFilters remove_comments
|
||||
ModPagespeedInPlaceResourceOptimization on
|
||||
|
||||
# Do not optimize these resources which are used for blogpost
|
||||
ModPagespeedDisallow */puzzle_optimized_to_low_quality_webp.webp
|
||||
ModPagespeedDisallow */puzzle_optimized_to_low_quality_webp_and_saved_as_png.png
|
||||
ModPagespeedDisallow */puzzle_original.jpg
|
||||
@@ -0,0 +1,40 @@
|
||||
<html>
|
||||
<head>
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1">
|
||||
<title>mod_pagespeed Security Advisory: Insufficient Hostname Verification</title>
|
||||
<link rel="stylesheet" href="doc.css">
|
||||
</head>
|
||||
<body>
|
||||
<!--#include virtual="_header.html" -->
|
||||
|
||||
|
||||
<div id=content>
|
||||
<h1>mod_pagespeed Security Advisory: Insufficient Hostname Verification</h1>
|
||||
<dl>
|
||||
<dt>CVE Identifier:</dt>
|
||||
<dd>CVE-2012-4001</dd>
|
||||
<dt>Disclosed:</dt>
|
||||
<dd>September 12, 2012</dd>
|
||||
<dt>Versions Affected:</dt>
|
||||
<dd>All versions of mod_pagespeed up to and including 0.10.22.4.</dd>
|
||||
<dt>Summary:</dt>
|
||||
<dd>mod_pagespeed performs insufficient verification of its own host name,
|
||||
which makes it possible to trick it into doing HTTP fetches and resource
|
||||
processing from arbitrary host names, including potentially bypassing
|
||||
firewalls.</dd>
|
||||
<dt>Solution:</dt>
|
||||
<dd>mod_pagespeed 0.10.22.6 has been released with a fix.</dd>
|
||||
<dt>Workaround:</dt>
|
||||
<dd>If you are unable to upgrade to the new version, you can avoid this
|
||||
issue by changing your Apache httpd configuration. Give any virtual host
|
||||
that enables mod_pagespeed (and the global configuration, if it also enables
|
||||
mod_pagespeed) an accurate explicit <code>ServerName</code>, and set the
|
||||
options <code>UseCanonicalName</code> and
|
||||
<code>UseCanonicalPhysicalPort</code> to <code>On</code> in each. Please be
|
||||
aware, however, that depending on the version,
|
||||
<a href="CVE-2012-4360">CVE-2012-4360</a> may also apply.
|
||||
</dd>
|
||||
</div>
|
||||
<!--#include virtual="_footer.html" -->
|
||||
</body>
|
||||
</html>
|
||||
@@ -0,0 +1,30 @@
|
||||
<html>
|
||||
<head>
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1">
|
||||
<title>mod_pagespeed Security Advisory: Cross-Site Scripting</title>
|
||||
<link rel="stylesheet" href="doc.css">
|
||||
</head>
|
||||
<body>
|
||||
<!--#include virtual="_header.html" -->
|
||||
|
||||
|
||||
<div id=content>
|
||||
<h1>mod_pagespeed Security Advisory: Cross-Site Scripting</h1>
|
||||
<dl>
|
||||
<dt>CVE Identifier:</dt>
|
||||
<dd>CVE-2012-4360</dd>
|
||||
<dt>Disclosed:</dt>
|
||||
<dd>September 12, 2012</dd>
|
||||
<dt>Versions Affected:</dt>
|
||||
<dd>mod_pagespeed versions 0.10.19.1 through 0.10.22.4 (inclusive).
|
||||
Versions 0.9.18.6 and earlier are unaffected.</dd>
|
||||
<dt>Summary:</dt>
|
||||
<dd>mod_pagespeed performs insufficient escaping in some cases, which can
|
||||
permit a hostile 3rd party to inject JavaScript running in context of
|
||||
the site.</dd>
|
||||
<dt>Solution:</dt>
|
||||
<dd>mod_pagespeed 0.10.22.6 has been released with a fix.</dd>
|
||||
</div>
|
||||
<!--#include virtual="_footer.html" -->
|
||||
</body>
|
||||
</html>
|
||||
@@ -0,0 +1,61 @@
|
||||
<html>
|
||||
<head>
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1">
|
||||
<title>mod_pagespeed and ngx_pagespeed Security Advisory: Cross-Site Scripting</title>
|
||||
<link rel="stylesheet" href="doc.css">
|
||||
</head>
|
||||
<body>
|
||||
<!--#include virtual="_header.html" -->
|
||||
|
||||
|
||||
<div id=content>
|
||||
<h1>mod_pagespeed and ngx_pagespeed Security Advisory: Cross-Site Scripting</h1>
|
||||
<dl>
|
||||
<dt>CVE Identifier:</dt>
|
||||
<dd><p>CVE-2013-6111</p></dd>
|
||||
<dt>Disclosed:</dt>
|
||||
<dd><p>October 28th, 2013</p></dd>
|
||||
<dt>Versions Affected:</dt>
|
||||
<dd>
|
||||
<ul>
|
||||
<li>mod_pagespeed versions earlier than 1.0</li>
|
||||
<li>mod_pagespeed version 1.0.22.7 (fixed in 1.0.22.8)</li>
|
||||
<li>mod_pagespeed versions 1.1</li>
|
||||
<li>mod_pagespeed 1.2.24.1 (fixed in 1.2.24.2)</li>
|
||||
<li>mod_pagespeed 1.3.25.1 through 1.3.25.4 (fixed in 1.3.25.5)</li>
|
||||
<li>mod_pagespeed 1.4.26.1 through 1.4.26.4 (fixed in 1.4.26.5)</li>
|
||||
<li>mod_pagespeed and ngx_pagespeed 1.5.27.1 through 1.5.27.3 (fixed in 1.5.27.4)</li>
|
||||
<li>mod_pagespeed and ngx_pagespeed 1.6.29.1 through 1.6.29.6 (fixed in 1.6.29.7)</li>
|
||||
</ul>
|
||||
</dd>
|
||||
<dt>Summary:</dt>
|
||||
<dd><p>Some versions of mod_pagespeed and ngx_pagespeed are vulnerable to
|
||||
cross-site scripting (XSS), which can permit a hostile 3rd party to
|
||||
inject javascript running in the context of the site.</p></dd>
|
||||
<dt>Solution:</dt>
|
||||
<dd><p>For mod_pagespeed, update to one of versions 1.0.22.8-stable,
|
||||
1.2.24.2-stable, 1.3.25.5-stable, 1.4.26.5-stable, 1.5.27.4-beta, or
|
||||
1.6.29.7 or newer.</p>
|
||||
|
||||
<p>For ngx_pagespeed, update to 1.6.29.7 or newer.</p>
|
||||
</dd>
|
||||
<dt>Workaround:</dt>
|
||||
<dd>
|
||||
<p>No workaround is available for mod_pagespeed.</p>
|
||||
|
||||
<p>For ngx_pagespeed, you can completely prohibit access to
|
||||
<code>/ngx_pagespeed_statistics</code>,
|
||||
<code>/ngx_pagespeed_global_statistics</code> and
|
||||
<code>/ngx_pagespeed_message</code> (an IP whitelist is insufficient), via
|
||||
options similar to:
|
||||
<pre>
|
||||
location /ngx_pagespeed_global_statistics { deny all; }
|
||||
location /ngx_pagespeed_statistics { deny all; }
|
||||
location /ngx_pagespeed_message { deny all; }
|
||||
</pre>
|
||||
</p>
|
||||
</dd>
|
||||
</div>
|
||||
<!--#include virtual="_footer.html" -->
|
||||
</body>
|
||||
</html>
|
||||
@@ -0,0 +1,91 @@
|
||||
<div id=footer>
|
||||
<!--#include virtual="_navline.html" -->
|
||||
</div>
|
||||
|
||||
<script>
|
||||
function buildTocHelper(node, headers) {
|
||||
if (node.nodeType == 1) {
|
||||
// Element node.
|
||||
var nodeName = node.nodeName.toLowerCase();
|
||||
if (nodeName == "h2" || nodeName == "h3" || nodeName == "h4" ||
|
||||
nodeName == "h5" || nodeName == "h6") {
|
||||
if (node.id) {
|
||||
headers.push([nodeName, node.innerHTML, node.id]);
|
||||
node.appendChild(document.createTextNode("\u00A0")); // nbsp
|
||||
var a = document.createElement("a");
|
||||
a.class = "header-link";
|
||||
a.href = "#" + node.id;
|
||||
a.textContent = "\uD83D\uDD17"; // link symbol
|
||||
node.appendChild(a);
|
||||
}
|
||||
} else {
|
||||
for (var i = 0; i < node.childNodes.length; i++) {
|
||||
buildTocHelper(node.childNodes[i], headers);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
function buildToc() {
|
||||
var headers = [];
|
||||
buildTocHelper(document.body, headers);
|
||||
if (headers.length == 0) {
|
||||
return;
|
||||
}
|
||||
|
||||
var toc = document.getElementById("toc");
|
||||
var tocContents = document.createElement("div");
|
||||
tocContents.id = "toc-contents";
|
||||
tocContents.textContent = "Contents";
|
||||
toc.appendChild(tocContents);
|
||||
|
||||
var level = 1;
|
||||
var currentUl = null;
|
||||
for (var i = 0; i < headers.length; i++) {
|
||||
var header = headers[i];
|
||||
var headerLevel = header[0];
|
||||
var headerValue = header[1];
|
||||
var headerId = header[2];
|
||||
|
||||
var newLevel = parseInt(headerLevel.substring(1));
|
||||
while (newLevel > level) {
|
||||
// We loop here to handle the case where we have h2 ... h4. This
|
||||
// isn't a good way to write html, but someone may still do it.
|
||||
|
||||
var newUl = document.createElement("ul");
|
||||
if (currentUl == null) {
|
||||
toc.appendChild(newUl);
|
||||
} else {
|
||||
currentUl.appendChild(newUl);
|
||||
}
|
||||
currentUl = newUl;
|
||||
level++;
|
||||
}
|
||||
while (newLevel < level) {
|
||||
currentUl = currentUl.parentNode;
|
||||
level--;
|
||||
}
|
||||
var li = document.createElement("li");
|
||||
var a = document.createElement("a");
|
||||
a.href = "#" + headerId;
|
||||
a.textContent = headerValue;
|
||||
li.appendChild(a);
|
||||
currentUl.appendChild(li);
|
||||
}
|
||||
}
|
||||
|
||||
function wrapTables() {
|
||||
var tables = document.getElementsByTagName("table");
|
||||
for (var i = 0; i < tables.length; i++) {
|
||||
var table = tables[i];
|
||||
var parent = table.parentNode;
|
||||
var div = document.createElement('div');
|
||||
div.className = "table-wrapper";
|
||||
parent.insertBefore(div, table);
|
||||
div.appendChild(table);
|
||||
}
|
||||
}
|
||||
|
||||
buildToc();
|
||||
wrapTables();
|
||||
</script>
|
||||
@@ -0,0 +1,15 @@
|
||||
<div id=header>
|
||||
<div id=logoline>
|
||||
<div id=logo>
|
||||
<img src="https://www.gstatic.com/images/branding/product/1x/pagespeed_32dp.png"
|
||||
srcset="https://www.gstatic.com/images/branding/product/2x/pagespeed_32dp.png"
|
||||
width=32 height=32 alt="pagespeed logo">
|
||||
</div>
|
||||
<div id=logotext>PageSpeed</div>
|
||||
</div>
|
||||
<div id=navline>
|
||||
<a href="/doc/">← documentation index</a>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<div id=toc></div>
|
||||
@@ -0,0 +1,3 @@
|
||||
<div id=navline>
|
||||
<a href="/doc/">← documentation index</a>
|
||||
</div>
|
||||
@@ -0,0 +1,392 @@
|
||||
<html>
|
||||
<head>
|
||||
<meta name="viewport" content="width=device-width, initial-scale=1">
|
||||
<title>PageSpeed Admin Pages</title>
|
||||
<link rel="stylesheet" href="doc.css">
|
||||
</head>
|
||||
<body>
|
||||
<!--#include virtual="_header.html" -->
|
||||
|
||||
|
||||
<div id=content>
|
||||
<h1>PageSpeed Admin Pages</h1>
|
||||
<p>
|
||||
The admin pages are a collection of features that provide visibility
|
||||
into the operation of the PageSpeed optimizations.
|
||||
</p>
|
||||
<p>
|
||||
The pagespeed_admin and pagespeed_global_admin pages aggregate a set of pages
|
||||
showing server state so they can be accessed from a single handler. By
|
||||
organizing all these features under a single admin page, this can be done once,
|
||||
and can serve as a launching point for future administration features.
|
||||
Before <strong>version 1.9.32.1</strong> the admin pages were read-only, but
|
||||
starting in <strong>version 1.9.32.1</strong>, cache purging is supported.
|
||||
</p>
|
||||
<img src="images/admin_config.png" style="border:1px solid black" />
|
||||
<p>
|
||||
The name of the currently active page is underlined in the top navigation bar.
|
||||
</p>
|
||||
<table>
|
||||
<thead>
|
||||
<tr>
|
||||
<th>Page</th>
|
||||
<th>Related Options</th>
|
||||
<th>Description</th>
|
||||
</tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td>Statistics</td>
|
||||
<td>
|
||||
<a href="#statistics"><code>Statistics</code></a><br/>
|
||||
<a href="#virtual-hosts-and-stats"
|
||||
><code>UsePerVHostStatistics</code></a><br/>
|
||||
<code>mod_pagespeed_beacon</code><br/>
|
||||
<code>ngx_pagespeed_beacon</code>
|
||||
</td>
|
||||
<td>
|
||||
Shows server statistics since startup, such as how many
|
||||
resources are being optimized by filters, as well as various
|
||||
latency and cache effectiveness metrics.
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Configuration</td>
|
||||
<td><a href="config_filters">Configuring Filters</a><br/>
|
||||
<a href="https_support#spdy_configuration"
|
||||
><code>ModPagespeedIf</code></a> (Apache only)</td>
|
||||
<td>
|
||||
Shows detailed configuration information including all filters,
|
||||
options, and the current cache flush timestamp.
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Histograms</td>
|
||||
<td>
|
||||
<a href="filter-instrumentation-add"
|
||||
><code>add_instrumentation</code></a><br/>
|
||||
</td>
|
||||
<td>
|
||||
Shows detailed latency data for Page Load Time, rewriting,
|
||||
caches and HTTP fetching.
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Caches</td>
|
||||
<td>
|
||||
<a href="system#memcached"><code>MemcachedServers</code></a>
|
||||
<a href="system#shm_cache"><code>CreateSharedMemoryMetadataCache</code></a>
|
||||
<a href="system#purge_cache"><code>EnableCachePurge</code></a>
|
||||
</td>
|
||||
<td>
|
||||
Shows detailed cache configuration information. When accessed
|
||||
from the Admin handler, it can be used to inspect the contents
|
||||
of the cache, and provides an interface to purge the cache.
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Console</td>
|
||||
<td>
|
||||
<a href="admin#statistics"><code>Statistics</code></a><br/>
|
||||
<a href="console#configuring"><code>StatisticsLogging</code></a><br/>
|
||||
<a href="console#configuring"><code>LogDir</code></a>
|
||||
</td>
|
||||
<td>
|
||||
Displays a <a href="console">console</a> of graphs
|
||||
of server optimization behavior over time.
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td>Message History</td>
|
||||
<td>
|
||||
<a href="#message-buffer-size"><code>MessageBufferSize</code></a>
|
||||
</td>
|
||||
<td>
|
||||
Server-wide history of recent logging output from PageSpeed,
|
||||
including messages that are omitted from the server log file based on
|
||||
its log level.
|
||||
</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
<p>
|
||||
Before 1.8.31.2, the main admin page is not available, but there
|
||||
are page-specific handlers for statistics, messages, and the
|
||||
console. In 1.8.31.2 and later, the <code>*_pagespeed_*</code> handlers, such
|
||||
as <code>mod_pagespeed_statistics</code>, will continue to be supported:
|
||||
<ul>
|
||||
<li>They provide read-only access to server operation. There may
|
||||
be cases where a site owner wants to share statistics or console
|
||||
information but not the ability to purge the cache.</li>
|
||||
<li>Existing configurations must continue to work after an upgrade to
|
||||
a release that supports pagespeed_admin.</li>
|
||||
<li>The admin pages may later gain support for modifying the server
|
||||
state</li>
|
||||
</ul>
|
||||
</p>
|
||||
<h2 id="config">Configuring Admin Pages</h2>
|
||||
|
||||
<p>
|
||||
In this table we use the term "server" for an Apache VirtualHost and
|
||||
an nginx Server Block. We use the term "global" to mean the entire
|
||||
Apache or nginx system, covering all the configured VirtualHost and
|
||||
Server Blocks.
|
||||
</p>
|
||||
<table>
|
||||
<thead>
|
||||
<tr><th>Apache Handler</th><th>Nginx Option</th><th>Version</th>
|
||||
<th>Description</th></tr>
|
||||
</thead>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td><code>pagespeed_admin</code></td>
|
||||
<td><code>AdminPath</code></td>
|
||||
<td>1.8.31.2+</td><td>Covers all administrative functions for
|
||||
a host in one handler. If you establish this handler,
|
||||
you don't need any of the other server-scoped methods. Only
|
||||
give 'admin' page access to clients that you are comfortable
|
||||
allowing to modify the state of your PageSpeed configuration.
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>pagespeed_global_admin</code></td>
|
||||
<td><code>GlobalAdminPath</code></td>
|
||||
<td>1.8.31.2+</td><td>Covers all administrative functions for
|
||||
the entire global state in one handler. If you establish this
|
||||
handler, you don't
|
||||
need <code>mod_pagespeed_global_statistics</code>.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>mod_pagespeed_statistics</code></td>
|
||||
<td><code>StatisticsPath</code> (1.8.31.2+)</td>
|
||||
<td>All</td><td>Launchpad for Statistics, Histograms, and
|
||||
a subset of the Caches page as described above.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>mod_pagespeed_global_statistics</code></td>
|
||||
<td><code>GlobalStatisticsPath</code> (1.8.31.2+)</td>
|
||||
<td>1.1+</td><td>Same as above, but aggregates statistics across all
|
||||
configured servers. You must enable
|
||||
<a href="#virtual-hosts-and-stats"
|
||||
><code>UsePerVHostStatistics</code></a> for separate global
|
||||
statistics to be retained, otherwise all statistics will be global.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>mod_pagespeed_message</code></td>
|
||||
<td><code>MessagesPath</code> (1.8.31.2+)</td>
|
||||
<td>1.0+</td><td>Displays recent log messages printed by PageSpeed,
|
||||
including messages that may be below the current server loglevel
|
||||
threshold such as "Info" messages. Requires that
|
||||
<a href="#message-buffer-size"><code>MessageBufferSize</code></a> be set.</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td><code>pagespeed_console</code></td>
|
||||
<td><code>ConsolePath</code> (1.8.31.2+)</td>
|
||||
<td>1.6+</td><td>Displays a <a href="console">console</a> of graphs
|
||||
of server optimization behavior over time.</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
<h3 id="handlers">Establishing Handlers in Apache</h2>
|
||||
<p>
|
||||
Each handler is optional; add them individually to enable
|
||||
admin features. Note that when you add handlers for
|
||||
<code>pagespeed_admin</code> and <code>pagespeed_global_admin</code>
|
||||
you are granting read/write access to server-state. The other handlers
|
||||
are read-only. A sample handler that filters on IP address is
|
||||
in the default configuration, whose general form is:
|
||||
</p>
|
||||
<pre class="prettyprint lang-sh">
|
||||
<Location /PATH>
|
||||
Order allow,deny
|
||||
Allow from localhost
|
||||
Allow from 127.0.0.1
|
||||
SetHandler HANDLER_NAME
|
||||
</Location>
|
||||
</pre>
|
||||
<p>
|
||||
You can choose any path for a handler, but you must specify the handler
|
||||
name exactly as it appears in the table above. By convention we use
|
||||
use the handler name for the path. You may also want to
|
||||
employ login-based access to the admin pages, using
|
||||
<code>AllowOverride AuthConfig</code>. Please see the Apache
|
||||
<a href="http://httpd.apache.org/docs/2.2/howto/auth.html">2.2</a>
|
||||
or
|
||||
<a href="http://httpd.apache.org/docs/2.4/howto/auth.html">2.4</a>
|
||||
Documentation for details.
|
||||
</p>
|
||||
<h3 id="handlers">Establishing Handlers in Nginx</h2>
|
||||
<p>
|
||||
In nginx, the handlers must be specified as location blocks.
|
||||
</p>
|
||||
<pre class="prettyprint lang-sh">
|
||||
location /ngx_pagespeed_statistics { allow 127.0.0.1; deny all; }
|
||||
location /ngx_pagespeed_global_statistics { allow 127.0.0.1; deny all; }
|
||||
location /ngx_pagespeed_message { allow 127.0.0.1; deny all; }
|
||||
location /pagespeed_console { allow 127.0.0.1; deny all; }
|
||||
location ~ ^/pagespeed_admin { allow 127.0.0.1; deny all; }
|
||||
location ~ ^/pagespeed_global_admin { allow 127.0.0.1; deny all; }
|
||||
</pre>
|
||||
<p class="note">
|
||||
Note that these handlers must precede the
|
||||
"<code>\.pagespeed\.([a-z]\.)?[a-z]{2}\.[^.]{10}\.[^.]+</code>" location block.
|
||||
</p>
|
||||
<p>
|
||||
In version 1.8.31.2 and later, the above location blocks are
|
||||
needed for each path you elect to enable in PageSpeed options:
|
||||
</p>
|
||||
<pre>
|
||||
pagespeed StatisticsPath /ngx_pagespeed_statistics;
|
||||
pagespeed GlobalStatisticsPath /ngx_pagespeed_global_statistics;
|
||||
pagespeed MessagesPath /ngx_pagespeed_message;
|
||||
pagespeed ConsolePath /pagespeed_console;
|
||||
pagespeed AdminPath /pagespeed_admin;
|
||||
pagespeed GlobalAdminPath /pagespeed_global_admin;
|
||||
</pre>
|
||||
<p>
|
||||
You can choose any path, as long as it's consistent between
|
||||
the <code>pagespeed Path</code> and the <code>location</code>. By
|
||||
convention we use the names as specified in the example.
|
||||
</p>
|
||||
<p>
|
||||
Prior to version 1.8.31.2, the above "Path" settings do not exist,
|
||||
and the failure to specify location blocks leaves the paths active
|
||||
with no access restrictions. The module will service requests
|
||||
to the paths whether the location blocks are specified or not.
|
||||
This applies to <code>/ngx_pagespeed_statistics</code>,
|
||||
<code>/ngx_pagespeed_global_statistics</code>,
|
||||
<code>/ngx_pagespeed_message</code>, and <code>/pagespeed_console</code>.
|
||||
</p>
|
||||
<p class="note">
|
||||
If you define access control for <code>/pagespeed_admin</code> or
|
||||
<code>/pagespeed_console</code>, you must do so earlier in the configuration
|
||||
file than the path to handle <code>.pagespeed</code> resources, to ensure
|
||||
that the handlers are disambiguated.
|
||||
</p>
|
||||
<h3 id="limiting-handlers">Limiting Handler Access</h3>
|
||||
<p class="note"><strong>Note: New feature as of 1.10.33.0</strong></p>
|
||||
<p>
|
||||
Apache's SetHandler access controls are accessible to anyone who can
|
||||
modify <code>.htaccess</code> files, so in a typical shared hosting context
|
||||
the global admin site isn't sufficiently protected. As of 1.10.33.0,
|
||||
PageSpeed allows setting an additional restriction of what domains are allowed
|
||||
to load handlers. For example, to deny access entirely, you could put:
|
||||
</p>
|
||||
<dl>
|
||||
<dt>Apache:<dd><pre class="prettyprint"
|
||||
>ModPagespeedStatisticsDomains Disallow *
|
||||
ModPagespeedGlobalStatisticsDomains Disallow *
|
||||
ModPagespeedMessagesDomains Disallow *
|
||||
ModPagespeedConsoleDomains Disallow *
|
||||
ModPagespeedAdminDomains Disallow *
|
||||
ModPagespeedGlobalAdminDomains Disallow *</pre>
|
||||
<dt>Nginx:<dd><pre class="prettyprint"
|
||||
>pagespeed StatisticsDomains Disallow *;
|
||||
pagespeed GlobalStatisticsDomains Disallow *;
|
||||
pagespeed MessagesDomains Disallow *;
|
||||
pagespeed ConsoleDomains Disallow *;
|
||||
pagespeed AdminDomains Disallow *;
|
||||
pagespeed GlobalAdminDomains Disallow *;</pre>
|
||||
</dl>
|
||||
<p>
|
||||
To allow access only to an admin, define a new VHost
|
||||
like <code>admin.example.com</code>, use standard web-server access control
|
||||
(IP or password) to restrict access to only that admin, and then at the top
|
||||
level of your config put:
|
||||
</p>
|
||||
<dl>
|
||||
<dt>Apache:<dd><pre class="prettyprint"
|
||||
>ModPagespeedStatisticsDomains Allow admin.example.com
|
||||
ModPagespeedGlobalStatisticsDomains Allow admin.example.com
|
||||
ModPagespeedMessagesDomains Allow admin.example.com
|
||||
ModPagespeedConsoleDomains Allow admin.example.com
|
||||
ModPagespeedAdminDomains Allow admin.example.com
|
||||
ModPagespeedGlobalAdminDomains Allow admin.example.com</pre>
|
||||
<dt>Nginx:<dd><pre class="prettyprint"
|
||||
>pagespeed StatisticsDomains Allow admin.example.com;
|
||||
pagespeed GlobalStatisticsDomains Allow admin.example.com;
|
||||
pagespeed MessagesDomains Allow admin.example.com;
|
||||
pagespeed ConsoleDomains Allow admin.example.com;
|
||||
pagespeed AdminDomains Allow admin.example.com;
|
||||
pagespeed GlobalAdminDomains Allow admin.example.com;</pre>
|
||||
</dl>
|
||||
<p>
|
||||
Now when you visit <code>admin.example.com/pagespeed_global_admin</code>
|
||||
you'll see global (server-level) admin information, but users are not able to
|
||||
access this under their own domain or turn the handler on
|
||||
with <code>.htaccess</code>.
|
||||
</p>
|
||||
<p>
|
||||
For all six of these options the default value is <code>Allow *</code>. If
|
||||
you explicitly <code>Allow</code> access to any site, all others are
|
||||
automatically <code>Disallow</code>ed. Wildcards are allowed, and additional
|
||||
directives are applied in sequence. For example, consider the following
|
||||
config:
|
||||
</p>
|
||||
<dl>
|
||||
<dt>Apache:<dd><pre class="prettyprint"
|
||||
>ModPagespeedAdminDomains Allow *.example.*
|
||||
ModPagespeedAdminDomains Disallow *.example.org
|
||||
ModPagespeedAdminDomains Allow www.example.org</pre>
|
||||
<dt>Nginx:<dd><pre class="prettyprint"
|
||||
>pagespeed AdminDomains Allow *.example.*;
|
||||
pagespeed AdminDomains Disallow *.example.org;
|
||||
pagespeed AdminDomains Allow www.example.org;</pre>
|
||||
</dl>
|
||||
<p>
|
||||
This would allow access to <code>www.example.com/pagespeed_admin</code>,
|
||||
and <code>www.example.org/pagespeed_admin</code> but
|
||||
not <code>shared.example.com/pagespeed_admin</code>.
|
||||
</p>
|
||||
|
||||
<h3 id="statistics">Shared Memory Statistics</h2>
|
||||
<p>
|
||||
By default PageSpeed collects cross-process statistics. While
|
||||
they're mostly intended for debugging and evaluation
|
||||
using <code>/mod_pagespeed_statistics</code>, <code>/ngx_pagespeed_statistics</code>,
|
||||
and the <a href="console">PageSpeed Console</a>, statistics are also
|
||||
necessary for limiting concurrent image rewrites
|
||||
and <a href="#rate_limit_background_fetches">background fetches</a>.
|
||||
It's not recommended to turn them off, as their performance impact
|
||||
is minimal, but if you need to you can do so with:
|
||||
<dl>
|
||||
<dt>Apache:<dd><pre class="prettyprint"
|
||||
>ModPagespeedStatistics off</pre></dd></dt>
|
||||
<dt>Nginx:<dd><pre class="prettyprint"
|
||||
>pagespeed Statistics off;</pre></dd></dt>
|
||||
</dl>
|
||||
</p>
|
||||
<h3 id="virtual-hosts-and-stats">Virtual hosts and statistics</h3>
|
||||
<p>
|
||||
You can choose whether PageSpeed aggregates its statistics
|
||||
over all virtual hosts (the default), or to keeps separate counts for each. You
|
||||
can chose the latter by specifying
|
||||
<code>UsePerVHostStatistics on</code>. In that
|
||||
case, <code>/pagespeed_admin</code>, <code>/mod_pagespeed_statistics</code>
|
||||
and <code>/ngx_pagespeed_statistics</code> will show the data for
|
||||
whatever virtual host is being accessed. If you do turn per-virtual
|
||||
host statistics on, you can still access the aggregates
|
||||
under <code>/pagespeed_global_admin</code>, <code>/mod_pagespeed_global_statistics</code>
|
||||
or <code>/ngx_pagespeed_global_statistics</code>.
|
||||
</p>
|
||||
<dl>
|
||||
<dt>Apache:<dd><pre class="prettyprint">ModPagespeedUsePerVhostStatistics on</pre>
|
||||
<dt>Nginx:<dd><pre class="prettyprint">pagespeed UsePerVhostStatistics on;</pre>
|
||||
</dl>
|
||||
|
||||
<h3 id="message-buffer-size">Message Buffer Size</h3>
|
||||
<p>
|
||||
Determines the number of bytes of shared memory to allocate as a circular
|
||||
buffer for holding recent PageSpeed log messages. By default, the size of
|
||||
this buffer is zero, and no messages will be retained.
|
||||
</p>
|
||||
<dl>
|
||||
<dt>Apache:<dd><pre class="prettyprint">ModPagespeedMessageBufferSize 100000</pre>
|
||||
<dt>Nginx:<dd><pre class="prettyprint">pagespeed MessageBufferSize 100000;</pre>
|
||||
</dl>
|
||||
|
||||
</div>
|
||||
<!--#include virtual="_footer.html" -->
|
||||
</body>
|
||||
</html>
|
||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 86 KiB |
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user